







只管知道有办法能让一句话、一段声音信号,一个图表(graph)转换为一堆向量,这是输入
这种任务输出的话有四种可能性:1.一个向量对应一个标签,2.一组向量对应一个标签,3.输入的个数和输出不一致(比如中文翻译成英文,词的数量不一致)
Sequence to Sequence :序列到序列的任务,(如翻译、语音识别)
今天只讲,一个向量对应一个标签,该任务又称Sequence Labeling
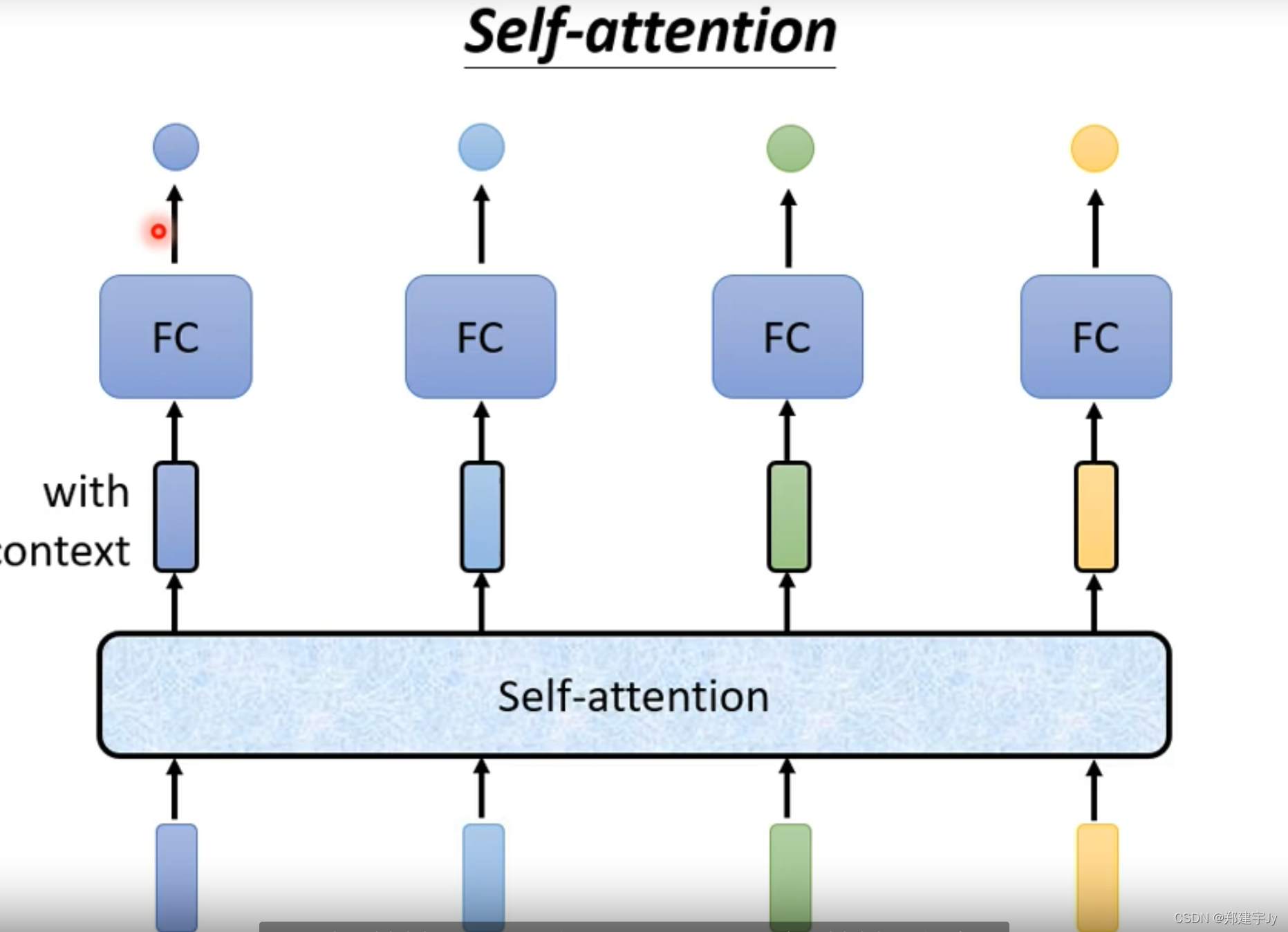
self attention :专注整个序列的信息
FC:专注某个位置的信息
下面看 self attention 模块的工作原理:↓↓↓↓↓↓↓↓↓↓
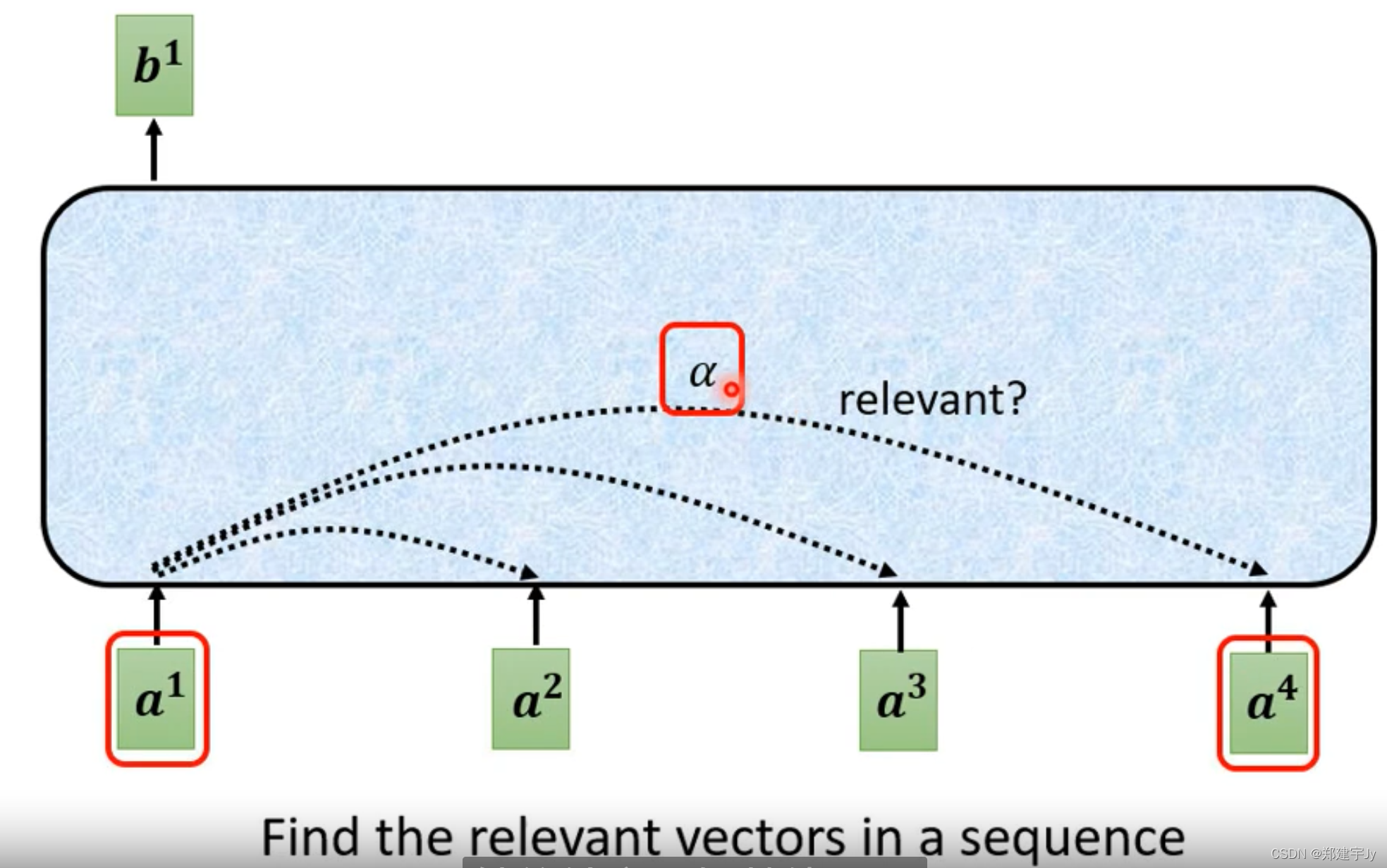
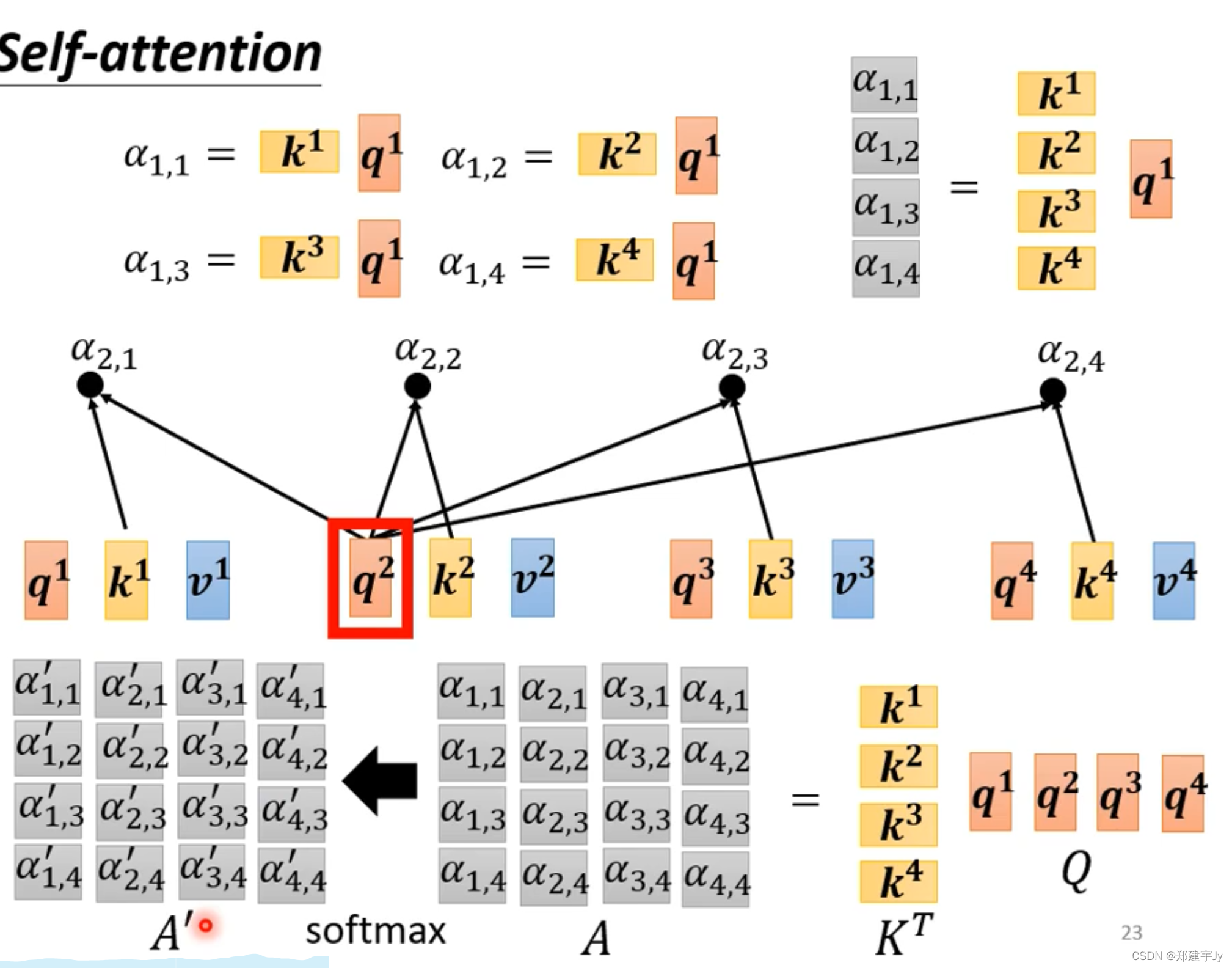
计算a1与a2a3a4的相关性(a1和a1也会自己做相关性计算)
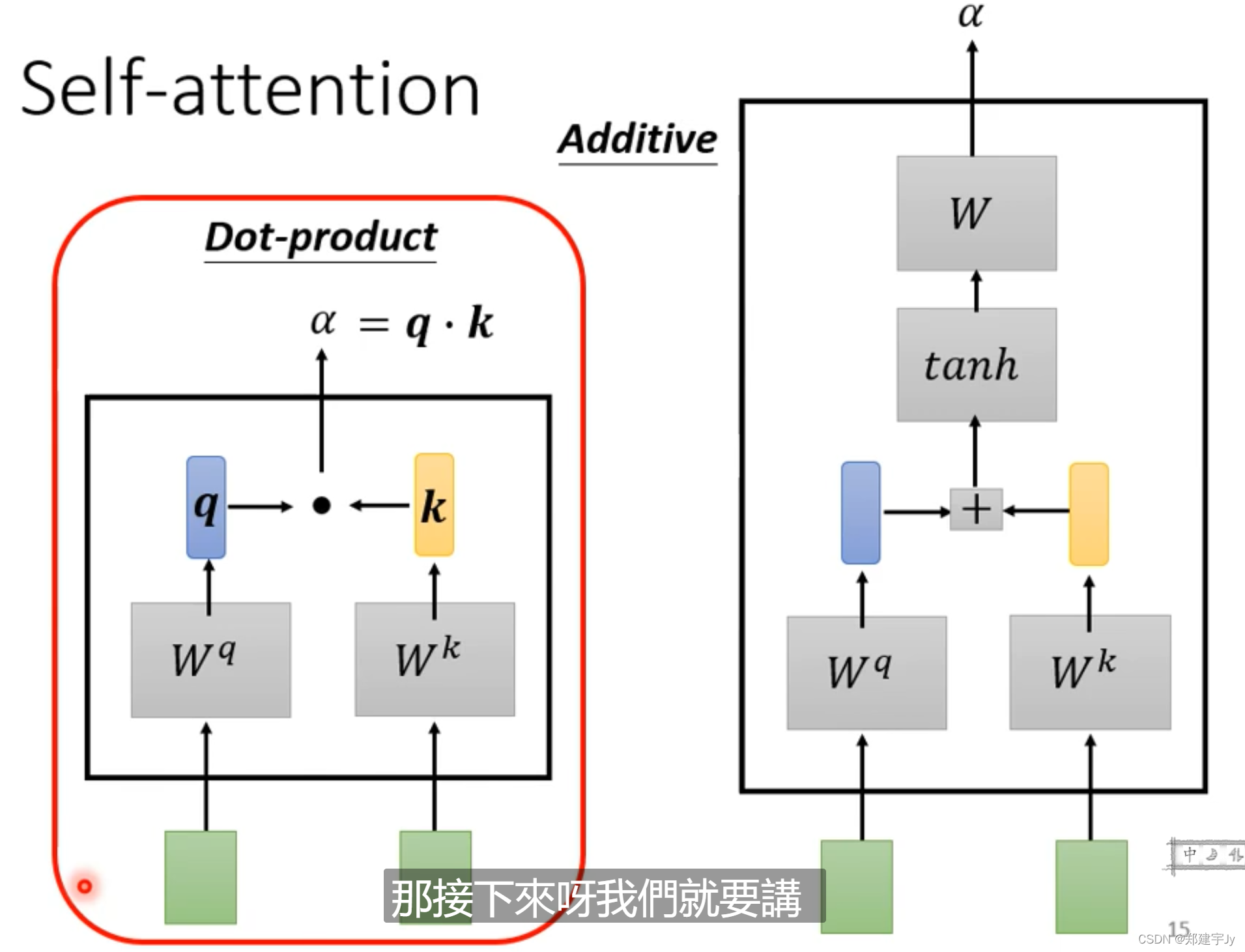
计算方法如下:有左右两种方法,常用左边
下面看怎么将该方法应用进自注意力模块:a1和a1也会自己做相关性计算
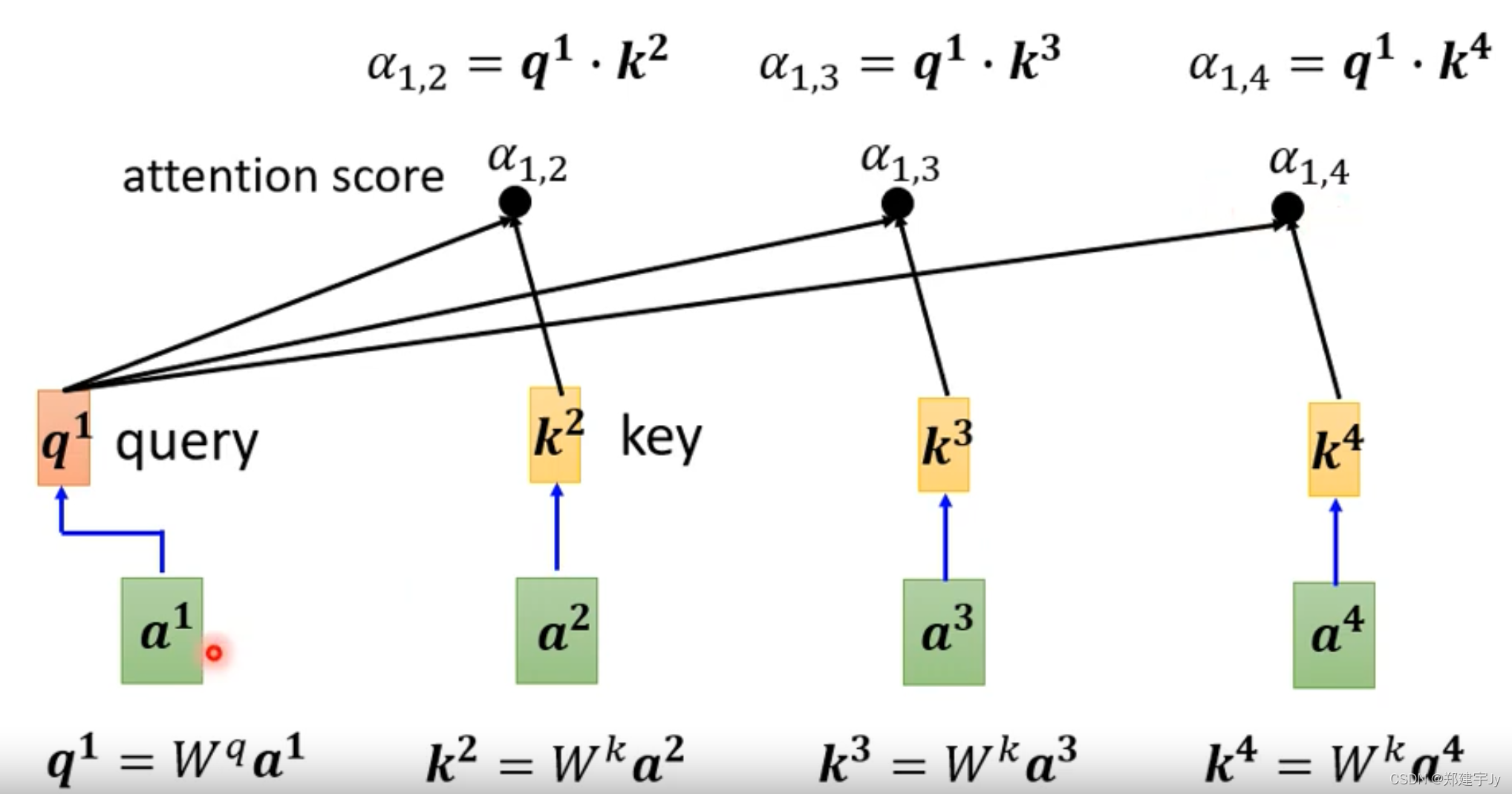
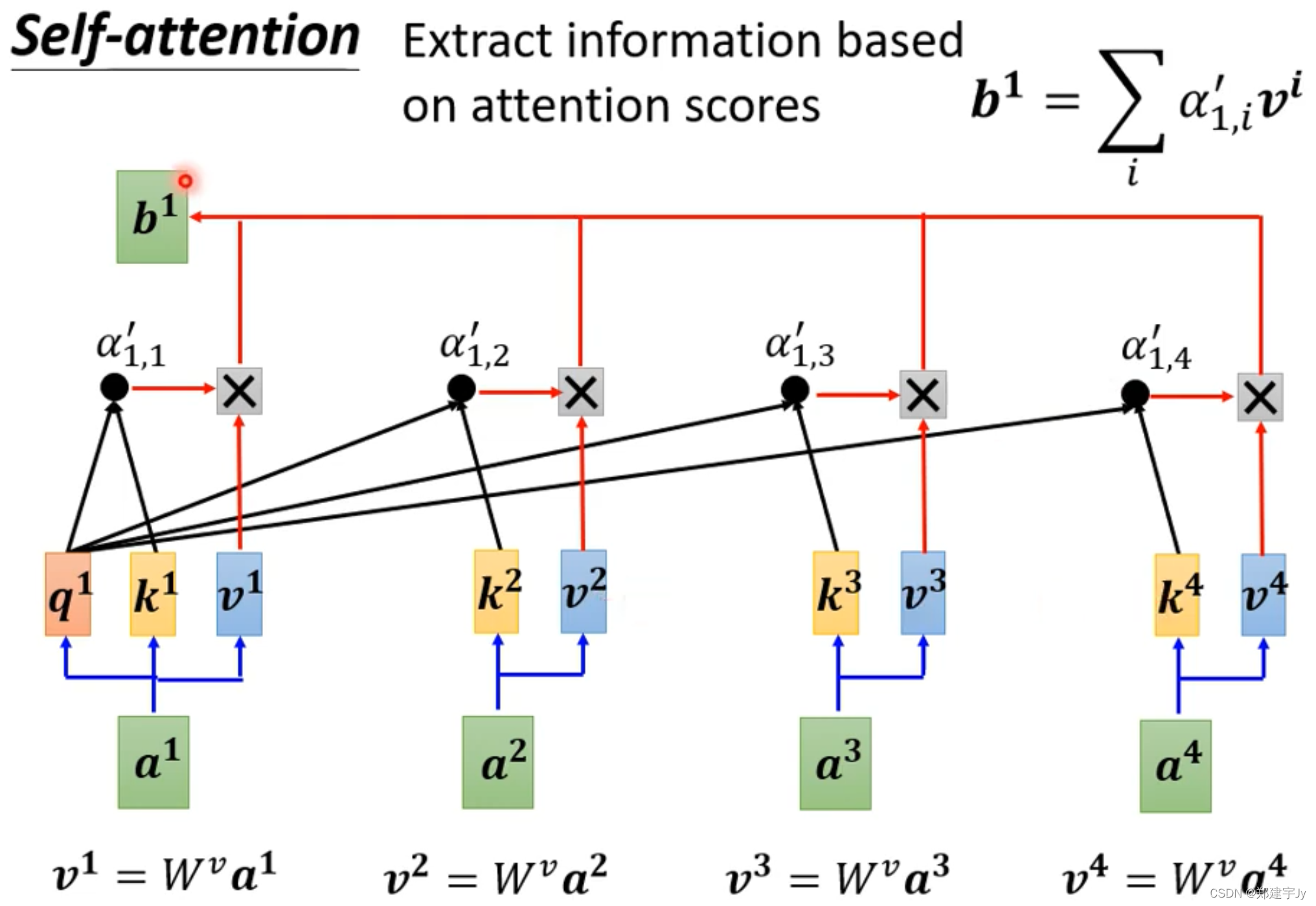
计算出相关性之后,接着加一层softmax层(也可以加别的激活函数,比如ReLu):

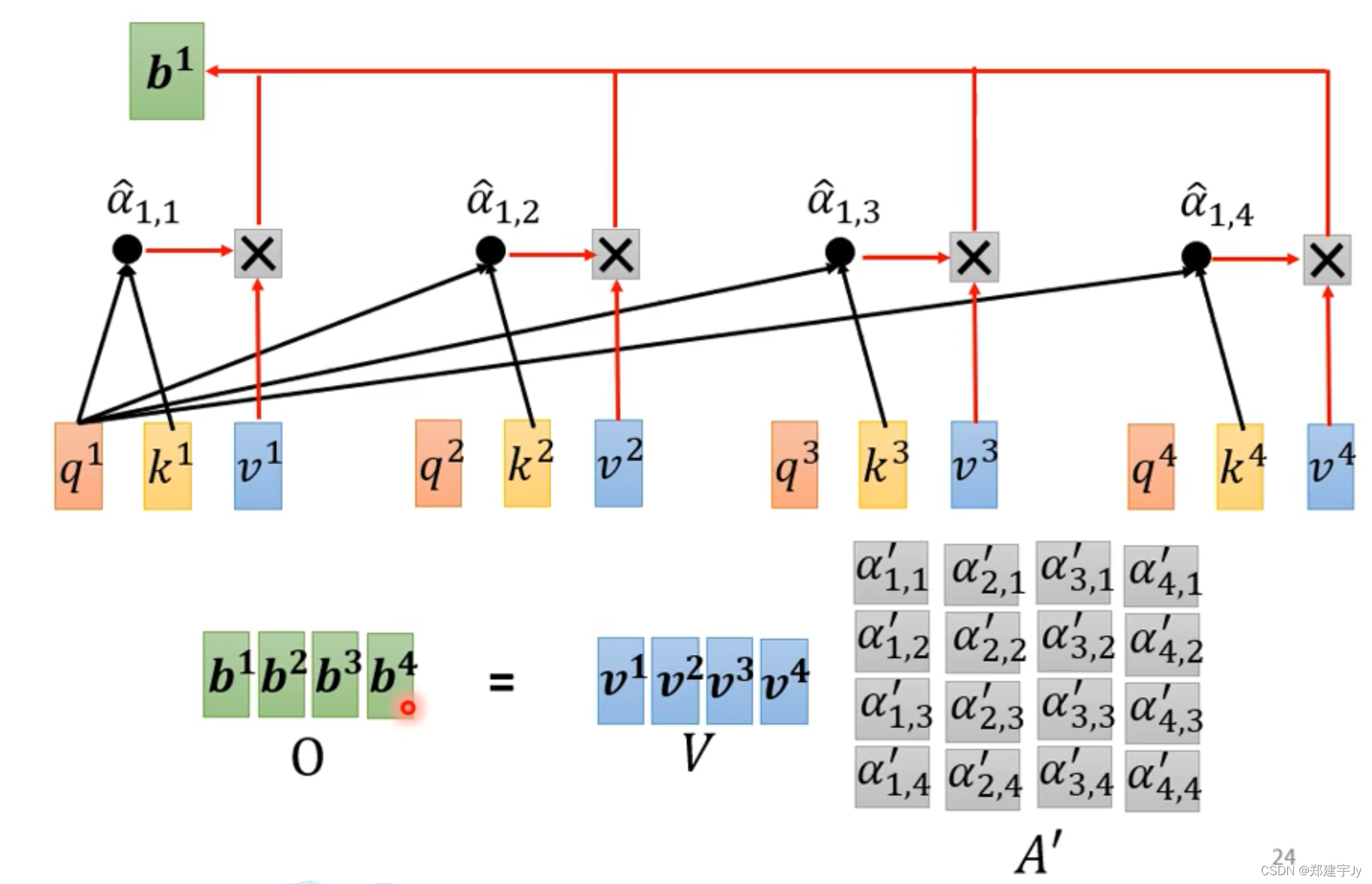
接着看一下b1是怎么得到的:
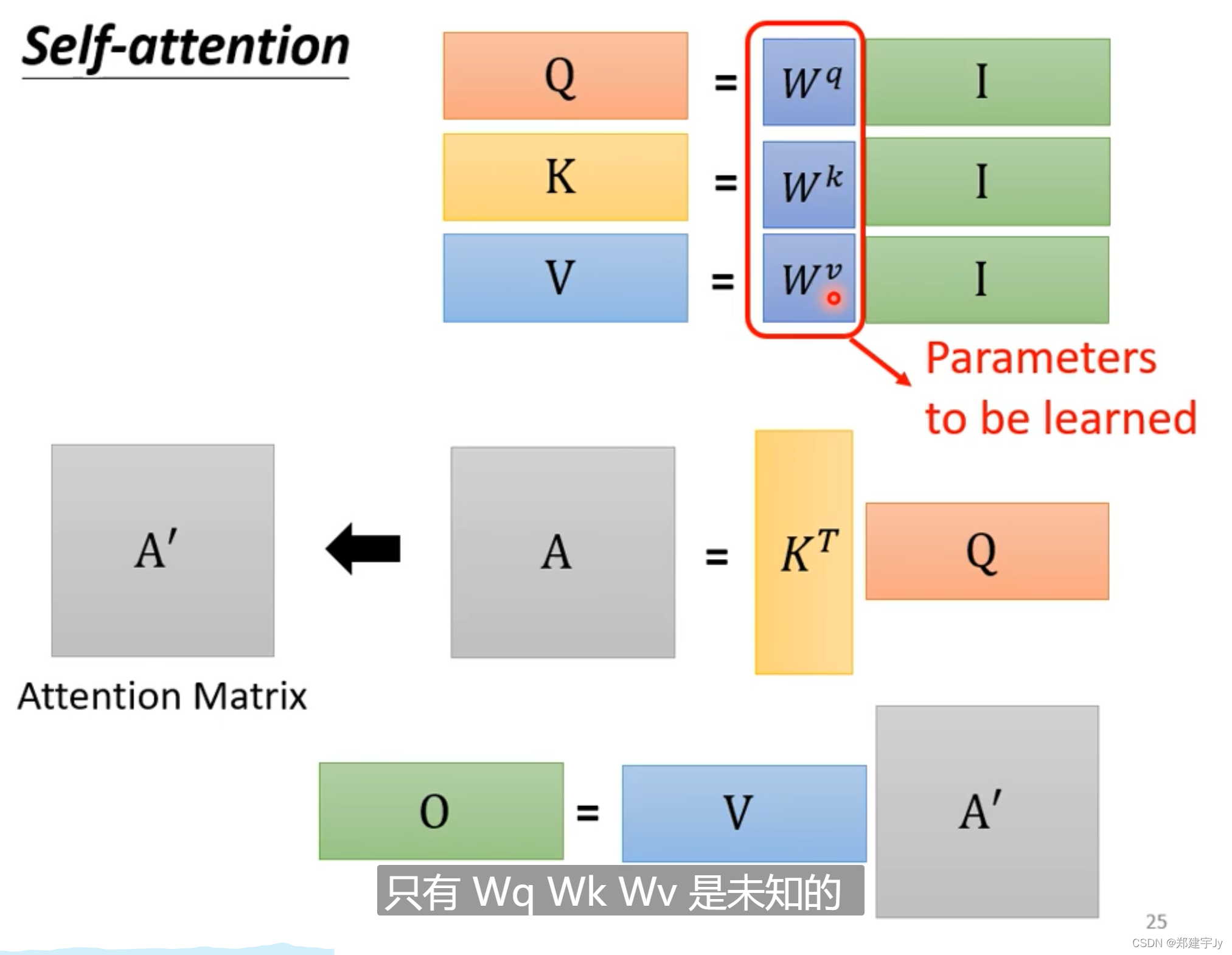
上述操作的矩阵解释:
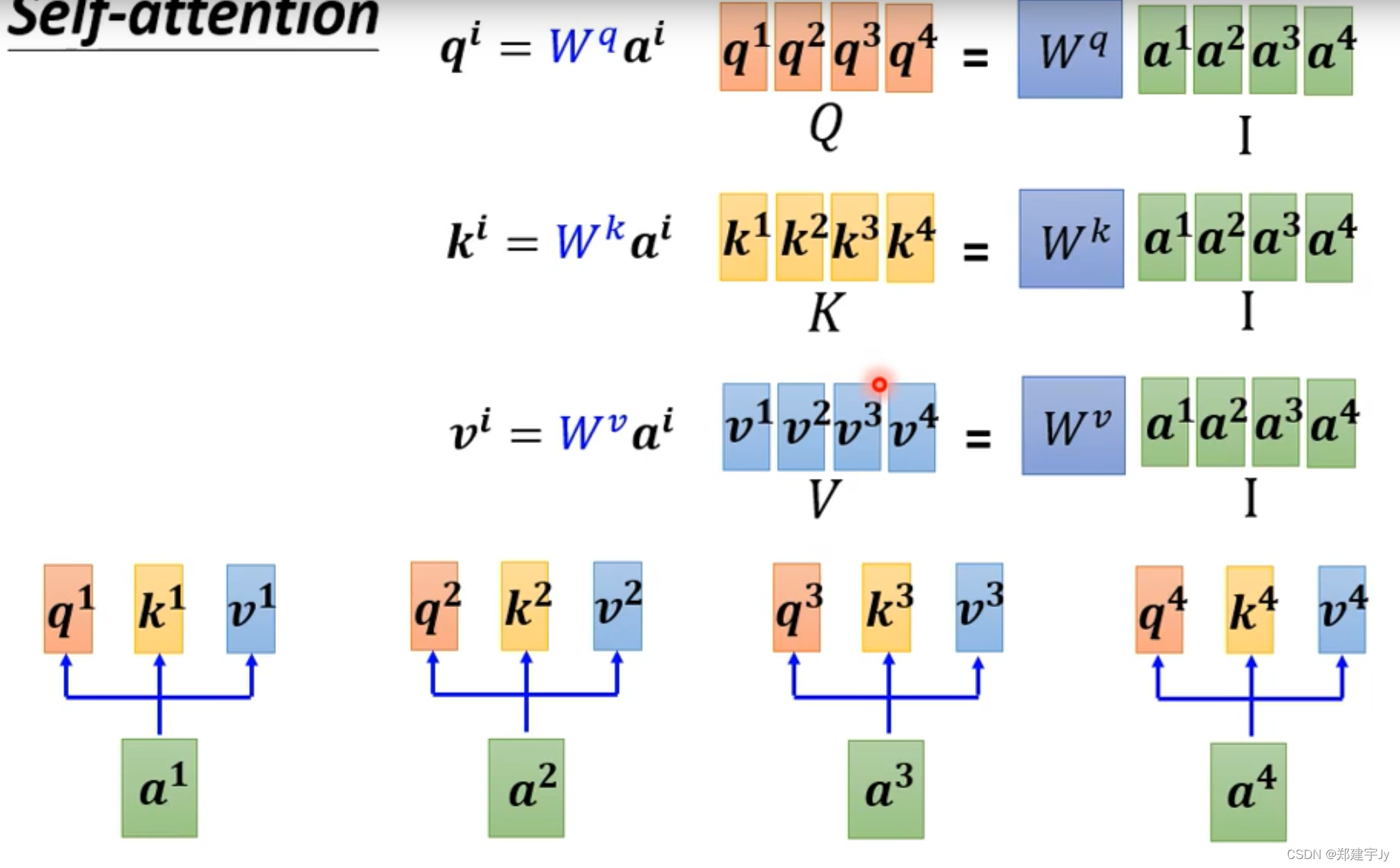
详细矩阵见下面三张图:
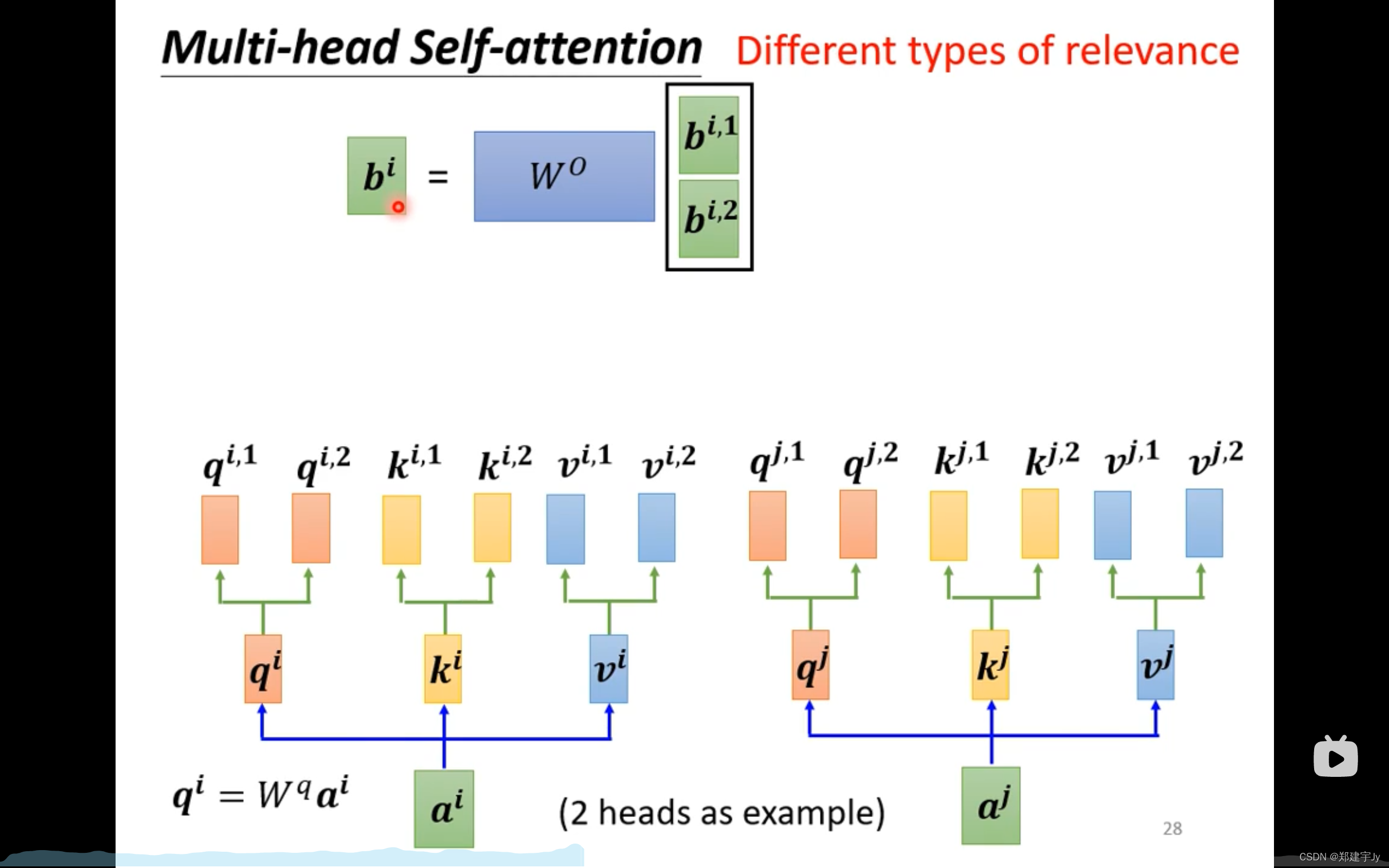
下面看多头注意力机制:
就是有多个Q、K、V,如下:(例如有两个Q)
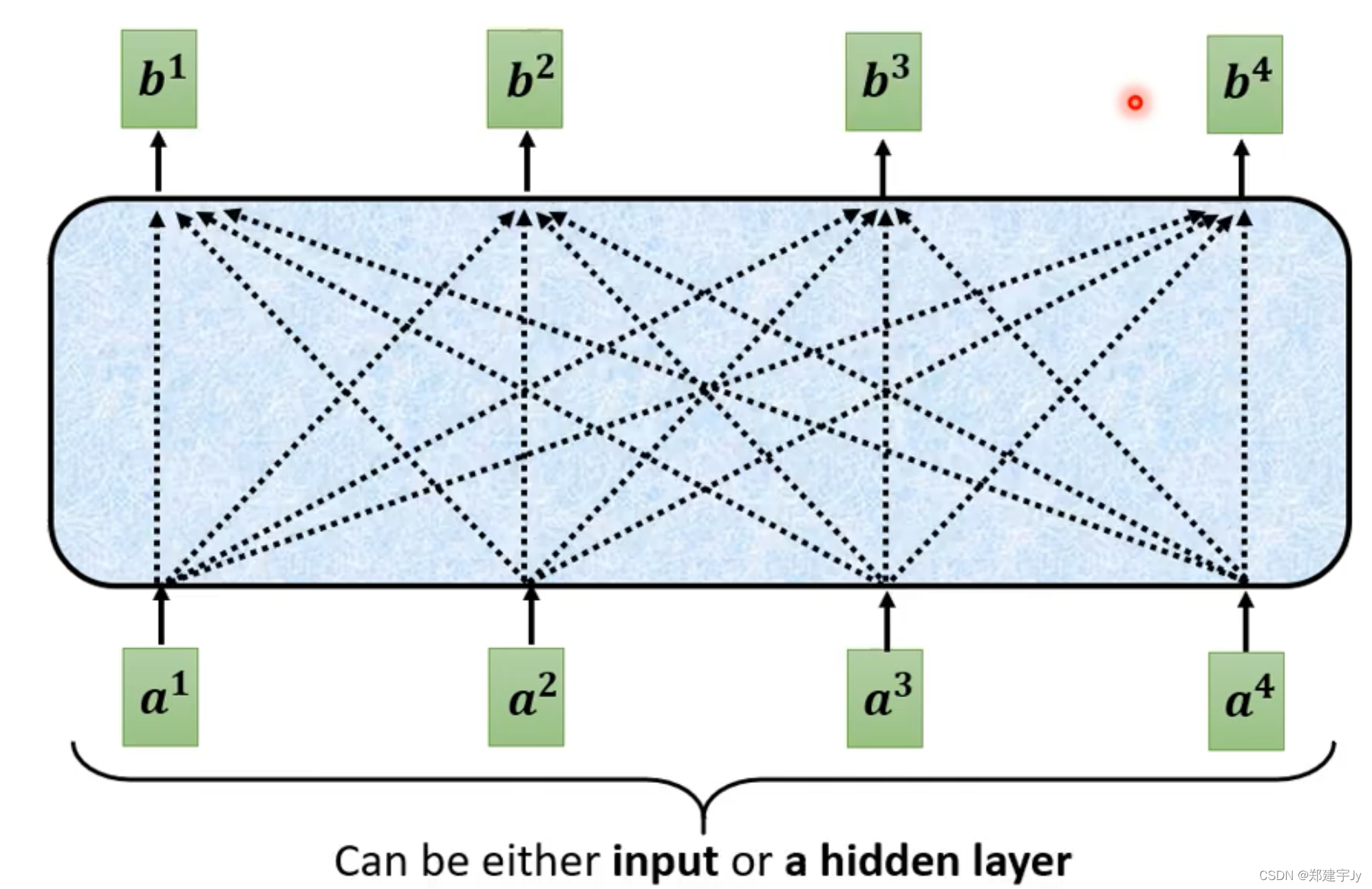
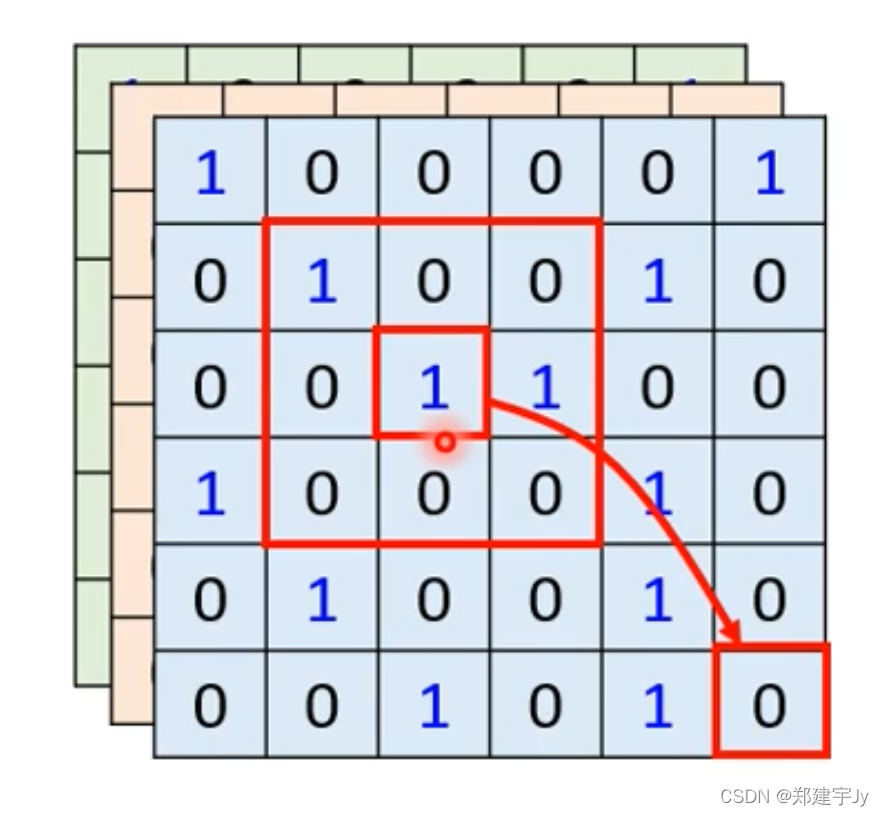
截止到目前所介绍的,注意力机制存在一个缺陷,只有互相的相关性信息,缺少了每个字符的位置信息:(position encoding 位置编码)
自注意力机制与CNN 的区别:
CNN就像一个简化版的自注意力机制,自注意力机制就像一个复杂化的CNN
有篇论文,用数学的角度解释两者之间的关系:
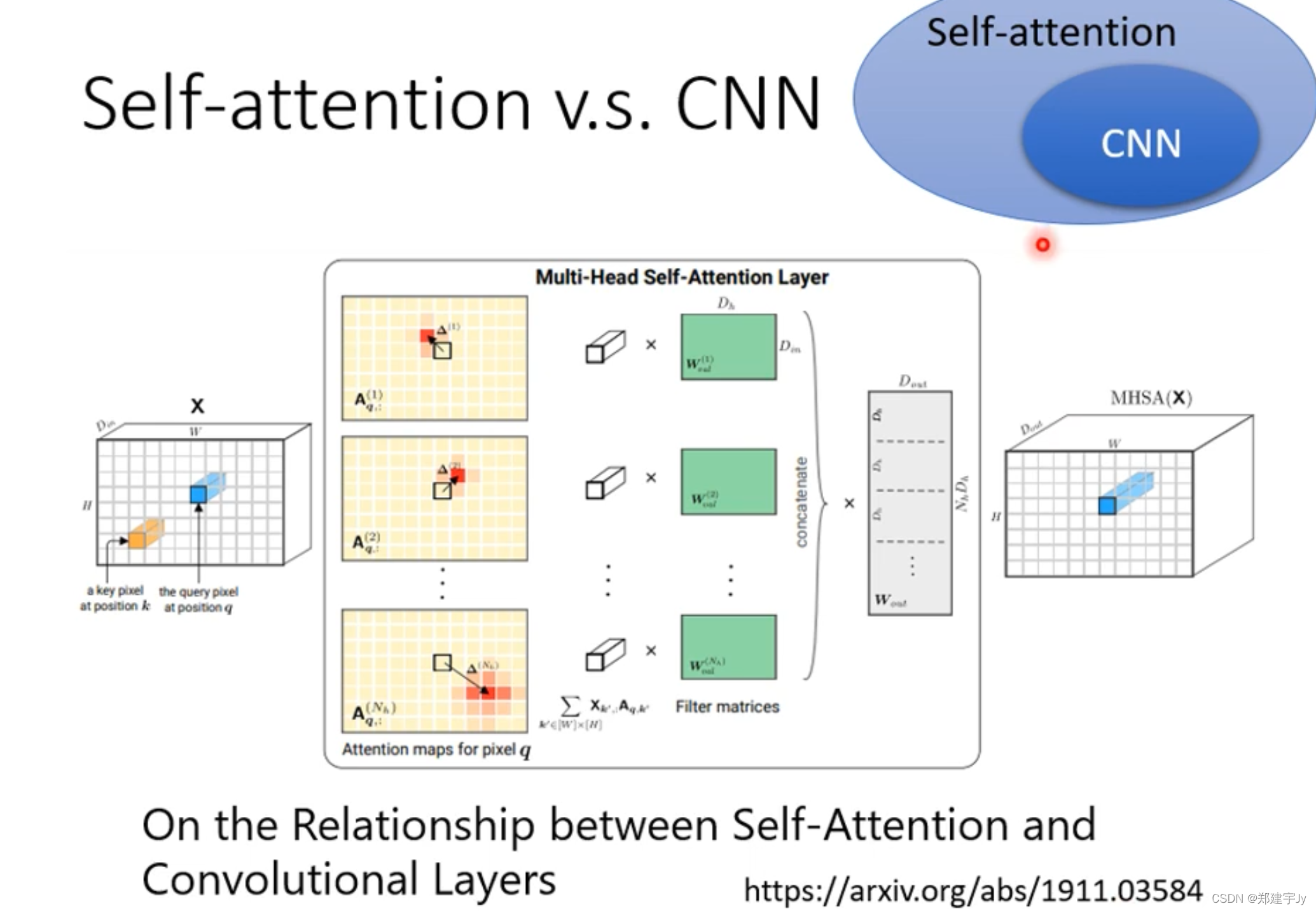

在训练资料少的时候,CNN表现的更好
训练资料足够多的时候,自注意力表现得更好
——————————————————————————————————————————
自注意力和RNN比较:(具体可以看这篇论文,下载地址点这里:Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention)
李宏毅:RNN很大一部分可以被self-attention取代了(2021年课程)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











