







摘要:
由于表格结构的多样性和复杂的单元生成关系,表格结构识别是一项具有挑战性的任务。以前的方法从不同粒度的元素(行\列、文本区域)开始处理这个问题,不知何故,这些元素会陷入有损启发式规则或忽略空单元划分等问题。基于表格结构特征,我们发现获得文本区域的对齐边界框可以有效地保持不同单元格的整个相关范围。然而,由于视觉模糊性,对齐的边界框很难准确预测。在本文中,我们的目标是通过充分利用所提出的局部特征中的文本区域的视觉信息和全局特征中的单元关系来获得更可靠的对齐边界框。具体而言,我们提出了局部和全局金字塔掩码对齐框架,在局部和全局特征映射中采用soft金字塔掩码学习机制。它允许边界框的预测边界突破原始方案的限制。然后集成金字塔掩码重新评分模块,以折衷局部和全局信息并细化预测边界。最后,我们提出了一种鲁棒的表结构恢复流水线来获得最终结构,在该流水线中我们还有效地解决了空单元的定位和划分问题。实验结果表明,所提出的方法在多个公共基准上实现了有竞争力的甚至是最新的性能。
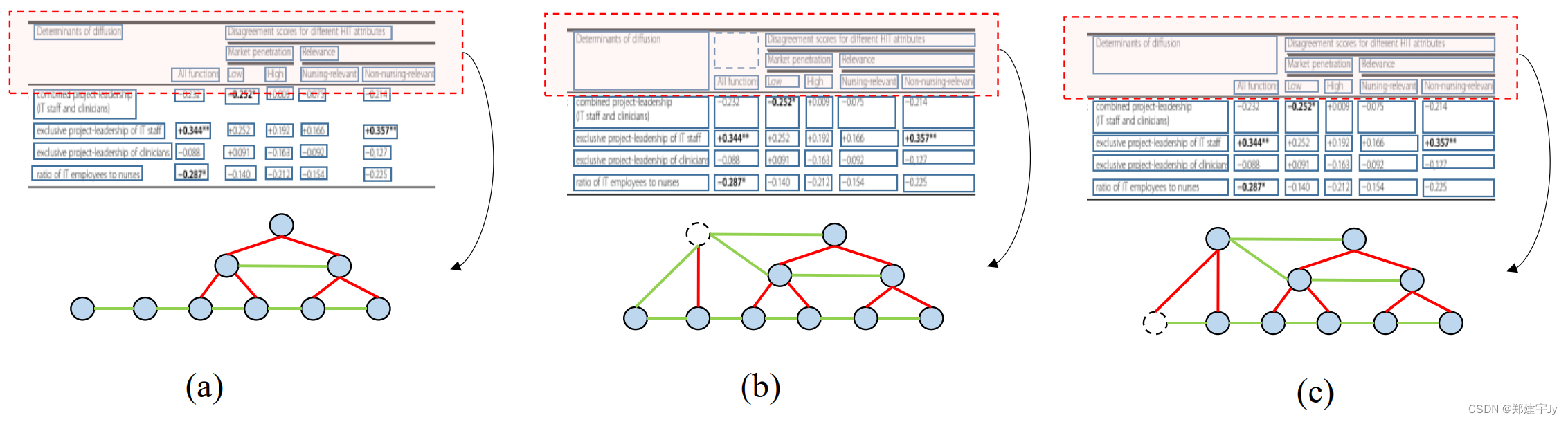
图1:(a)未考虑空单元格的可视化结果。(b) 对齐边界框和节点关系的基本真相。(c) 由于空单元格和跨列单元格之间的模糊性,这是一个错误的示例。单元及其关系表示为节点和连接线(红色:垂直,绿色:水平)。空单元格以虚线圆圈显示。
1导言
表是许多真实文档(如财务报表、科学文献、采购清单等)中的丰富信息数据格式之一。除了文本内容外,表结构对于人们进行关键信息提取至关重要。因此,表格结构识别[10,21,34,30,5,4,39]成为当前文档理解系统中的重要技术之一。
从全局角度来看,早期的表结构识别过程通常取决于网格边界的检测[19,18]。但是,这些方法不能处理没有网格边界的表,例如三行表。尽管最近的工作[30,22,32,31]试图预测行/列区域,甚至是不可见的网格线[33],但它们仅限于处理跨多行/列的表。
行/列拆分操作还可能剪切包含多行文本的单元格。另一组方法以自下而上的方式解决上述问题,首先检测文本块的位置,然后通过启发式规则[38]或GNN(图形神经网络)[29,14,2,24,26]恢复边界框的关系。然而,基于文本区域边界框设计的规则很容易处理复杂的匹配情况。基于GNN的方法不仅带来额外的网络成本,而且还依赖于更昂贵的训练成本,例如数据量。另一个问题是,这些方法很难获得空单元格,因为它们通常会陷入跨行\列单元格的视觉模糊问题。空单元格的预测直接影响表结构的正确性,如图1(a)所示。此外,如何分割或合并这些空白区域仍然是一个不可忽视的挑战性问题,因为当图像转换为数字格式时,不同的分割结果将生成不同的可编辑区域。
请注意,表本身的结构是一种基于规则的人工数据形式。在表没有视觉旋转或透视转换的情况下,如果我们可以获得所有完美对齐的单元格区域,而不是文本区域[26],结构推断将很容易,几乎是无损的,如图1(b)所示。然而,获取此类信息并不容易。一方面,文本区域[5,2,39]的注释比单元格区域更容易获得。另一方面,由于区域外围通常没有可见的边界纹理,因此很难准确地学习对齐的框。多行\列单元格很容易与空单元格区域混淆。例如,在图1(c)中,网络通常会陷入预测的对齐框不够大的情况,从而导致错误的单元匹配。虽然[26]设计了一个对齐损失来帮助边界框学习,但它只考虑了框之间的相对关系,无法捕获小区的绝对覆盖区域。
在本文中,我们旨在训练网络以获得更可靠的对齐单元区域,并在一个模型中解决空单元生成和划分问题。通过观察人们在阅读时感知到来自局部文本区域和全局布局的视觉信息,我们提出了一个统一的表结构识别框架,以兼顾局部和全局信息的好处,称为LGPMA(局部和全局金字塔掩码对齐)网络。具体而言,该模型同时学习基于局部掩码RCNN的[6]对齐边界框检测任务和全局分割任务。在这两项任务中,我们采用金字塔软掩模监督[17],以帮助获得更精确的对齐边界框。在LGPMA中,局部分支(LPMA)通过可见纹理感知器获取更可靠的文本区域信息,而全局分支(GPMA)可以学习更清晰的细胞范围或分裂的空间信息。这两个分支通过联合学习帮助网络更好地学习融合特征,并通过提出的掩码重新评分策略有效地细化检测到的对齐边界框。基于改进后的结果,我们设计了一个健壮而直观的表结构恢复管道,该管道可以有效地定位空单元,并根据全局分割的指导进行精确合并。
本文的主要贡献如下:(1)我们提出了一种新的框架,称为LGPMA网络,它从局部和全局角度兼顾视觉特征。该模型通过提出的掩码重新评分策略,充分利用了来自局部和全局特征的信息,可以获得更可靠的对齐单元区域。(2) 我们介绍了一种统一的表结构恢复流水线,包括单元匹配、空单元搜索和空单元合并。可以有效地定位和拆分非空细胞和空细胞。(3) 大量的实验表明,我们的方法在几个流行的基准测试上取得了有竞争力的甚至是最先进的结果。
2.相关工作
传统的表格识别研究主要使用手工特征和启发式规则[8,10,34,19,18,3]。这些方法主要应用于简单的表结构或特定的数据格式,如PDF。早期关于表格检测和识别的技术可以在综合调查中找到[37]。随着深度神经网络在计算机视觉领域的巨大成功,人们开始关注具有更一般结构的基于图像的表格[21,30,24,9,13,36,23,14,33]。根据基本组件粒度,我们将以前的方法大致分为两类:基于全局对象的方法和基于局部对象的方法。
基于全局对象的方法:主要关注全局表组件的特性,主要从行\列或网格边界检测开始。[30,31,32]的工作首先使用检测或分割模型获得行和列区域,然后将这两个区域相交以获得细胞网格。[22]通过表区域掩码学习和表的行/列掩码学习,以端到端的方式处理表检测和表识别任务。[33]通过学习行/列之间的间隔区域分割,然后预测合并分离单元的指示器,来检测行和列。
还有一些方法[13,39],它们直接将整个图像信息和输出表结构感知为编码器-解码器框架中的文本序列。虽然这些方法看起来很优雅,而且完全避免了人为因素的影响,但这些模型通常很难训练,并且依赖于大量的训练数据。基于全局对象的方法通常难以处理各种复杂的表结构,例如跨多行\列的单元格或包含多行文本的单元格。
基于局部对象的方法:从最小的基本元素单元开始。考虑到单元级文本区域标注,文本检测任务相对容易通过Yolo[27]、更快的RCNN[28]等通用检测方法完成。之后,一组方法[36,23,38]尝试基于一些启发式规则和算法恢复单元关系。另一类方法[11,2,14,24,26]将检测到的盒子视为图中的节点,并尝试基于图神经网络技术预测关系[29]。[14] 使用视觉特征、文本位置、单词嵌入等多种特征预测三类(水平连接、垂直连接、无连接)节点之间的关系[2]采用图形注意机制提高预测精度。[24]通过成对采样策略缓解了大型图节点数的问题。上述三部著作[14,2,24]也为该研究领域发布了新的表格数据集。由于没有检测到空单元,基于局部对象的方法通常陷入空单元模糊。
在本文中,我们试图兼顾全局和局部特征的优点。基于局部检测结果,我们整合全局信息以细化检测到的边界框,并为空单元划分提供直接指导。
3.方法
3.1概述:
我们提出了模型LGPMA,其总体工作流程如图2所示。
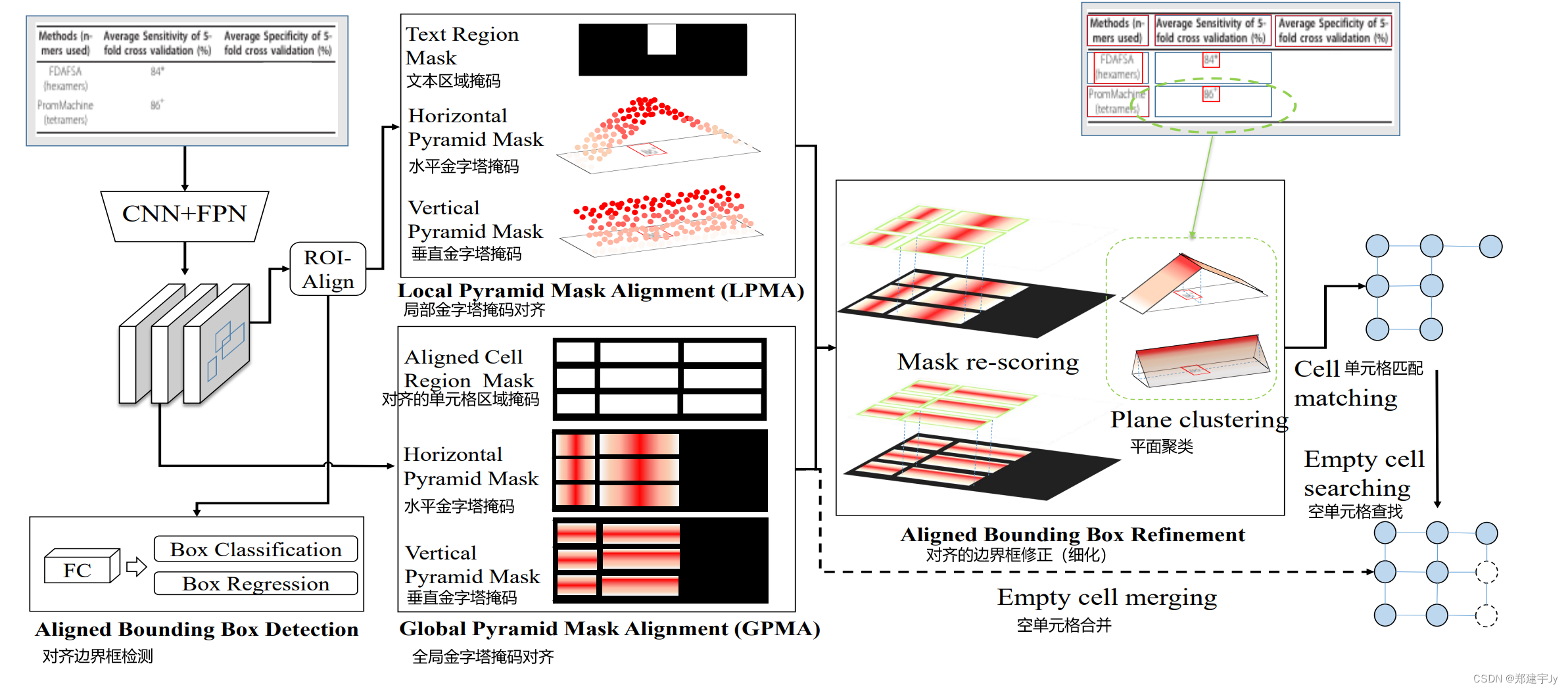
图2.LGPMA的工作流程。该网络同时学习局部对齐边界框检测任务(LPMA)和全局分割任务(GPMA)。我们在两个分支中采用金字塔掩码学习机制,并使用掩码重新评分策略来细化预测的边界框。最后,可以通过管道统一恢复表结构,包括单元匹配、空单元搜索和空单元合并。
该模型是基于现有的掩码RCNN[6]建立的。边界框分支直接学习非空单元对齐边界框的检测任务。网络同时学习基于由RoI对齐操作提取的局部特征的局部金字塔掩码对齐(LPMA)任务和基于全局特征图的全局金字塔掩码对准(GPMA)任务。
在LPMA中,除了学习文本区域掩码的二进制分割任务外,还使用金字塔软掩码在水平和垂直方向上对网络进行训练。
在GPMA中,网络学习非空单元的所有对齐边界框的全局金字塔掩码。为了获得有关空单元分割的更多信息,网络还学习了同时考虑非空单元和空单元的全局二进制分割任务。
然后采用金字塔掩码重新评分模块来细化预测的金字塔标签。通过平面聚类可以获得精确对齐的边界框。最后,集成包含单元匹配、空单元搜索和空单元合并的统一结构恢复管道,以获得最终的表结构。
3.2对齐边界框检测
精确文本区域匹配的困难主要来自文本区域和真实单元区域之间的覆盖范围间隙。真实细胞区域可以是包含行\列对齐的空格,尤其是跨多行\列的单元格。受[26,36]的启发,通过文本区域和行/列索引的注释,我们可以根据每行/列中的最大框高/宽度轻松生成对齐的边界框注释。对齐边界框的区域近似等于真实单元的区域。对于打印格式且无视觉旋转或透视变换的表格图像,如果我们可以获得对齐的单元格区域并假设没有空单元格,则很容易根据水平和垂直方向上的坐标重叠信息推断单元格关系。
我们采用掩码RCNN[6]作为基础模型。在包围盒分支中,基于对齐的包围盒监督来训练网络。然而,对齐边界框学习并不容易,因为单元格很容易与空白区域混淆。受高级金字塔掩码文本检测器[17]的启发,我们发现使用软标签分割可以突破提议的边界框的限制,并提供更精确的对齐边界框。为了充分利用局部纹理和全局布局的视觉特征,我们建议同时学习这两个折叠中的金字塔掩码对齐信息。

图3(a)显示了原始对齐的边界框(蓝色)和文本区域框(红色)。(b) 分别在水平方向和垂直方向显示棱锥遮罩标签。
3.3局部垂直掩模对齐
在掩码分支中,训练模型以学习二进制分割任务和金字塔掩码回归任务,我们称之为局部金字塔掩码对齐(LPMA)。
二进制分割任务与原始模型相同,其中只有文本区域标记为1,其他区域标记为0。检测到的掩码区域可用于以下文本识别任务。对于金字塔掩码回归,我们在水平和垂直方向上为提案边界框区域中的像素分配软标签,如图3所示。文本的中点将具有最大的回归目标1。具体而言,我们假设所提出的对齐边界框的形状为H×W。文本区域的左上点和右下点分别表示为{(x1,y1),(x2,y2)},其中0≤x1<x2≤ W和0≤y1<y2≤ H、 因此,金字塔掩模的目标形状为R2×H×W∈[0,1],其中两个通道分别表示水平掩模和垂直掩模的目标图。对于每个像素(h,w),这两个目标可以形成为:
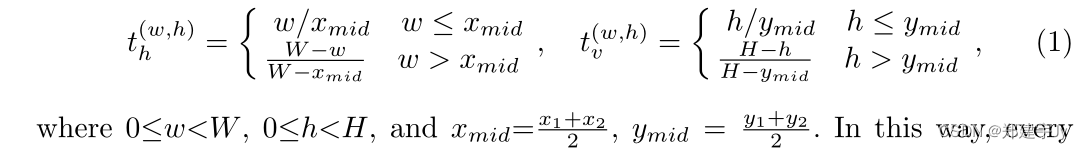
这样,建议区域中的每个像素都参与预测边界。
3.4全局金字塔掩码对齐
虽然LPMA允许预测的掩码突破提议边界框,但局部区域的接受域是有限的。为了确定单元格的准确覆盖区域,全局特征还可能提供一些视觉线索。受[40,25]的启发,从全局视图中学习每个像素的偏移可以帮助定位更精确的边界。然而,celllevel中的边界框可能在宽高比上有所不同,这导致了回归学习中的不平衡问题。因此,我们使用金字塔标签作为每个像素的回归目标,称为全局金字塔掩码对齐(GPMA)。
与LPMA一样,GPMA同时学习两个任务:全局分割任务和全局金字塔掩码回归任务。在全局分割任务中,我们直接分割所有对齐的单元格,包括非空单元格和空单元格。根据同一行\列中非空单元格的最大高度\宽度生成空单元格的基本真值。请注意,只有此任务才能学习空单元划分信息,因为空单元没有可能在某种程度上影响区域建议网络的可见文本纹理。我们希望该模型能够在全局边界分割过程中根据人类的阅读习惯捕获最合理的细胞分裂模式,这一点可以通过手动标记的注释反映出来。对于全局金字塔掩码回归,由于只有文本区域可以提供不同“山顶”的信息,所有非空单元格将被分配类似于LPMA的软标签。GPMA中对齐边界框的所有基本事实将缩小5%,以防止框重叠。
3.5优化
该网络通过多个优化任务进行端到端训练。全局优化可以写成:
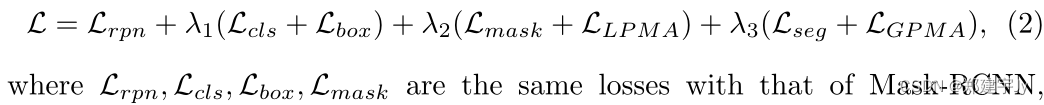
其中,Lrpn、LCL、Lbox、Lmask的损失与掩码RCNN的损失相同,分别表示提议中掩码的区域提议网络损失、包围盒分类损失、包围框回归损失和分割损失。Lseg是在骰子系数损失[20]中实现的全局二进制分割损失,LLP M A和LGP M A是通过逐像素L1损失优化的金字塔标签回归损失。λ1、λ2、λ3是加权参数。
3.6推断
推理过程可以分为两个阶段。我们首先根据金字塔掩码预测获得精确对齐的边界框,然后通过提出的结构恢复管道生成最终的表结构。
对齐边界框以优化。除了通过联合训练产生的好处外,局部和全局特征在对象感知方面也表现出各种优势[35]。在我们的设置中,我们发现局部特征预测更可靠的文本区域掩码,而全局预测可以提供更可靠的远距离视觉信息。为了兼顾这两种水平的优点,我们提出了一种金字塔掩码重新评分策略,以兼顾LPMA和GPMA的预测。对于具有局部金字塔掩码预测的任何建议区域,我们添加来自全局金字塔掩码的信息以调整这些分数。我们使用一些动态权重来平衡LPMA和GPMA的影响。
具体而言,对于预测的对齐边界框B={(x1,y1),(x2,y2)},我们首先获得文本区域掩码的边界框,表示为Bt={(x01,y01),(x02,y02)}。然后,我们可以在全局分割图中找到匹配的连通区域P={p1,p2,…,pn},其中P=(x,y)表示一个像素。我们使用Po={p|x1≤ p、 x≤ x2、y1≤ p、 y≤ y2,∀p∈ P}表示重叠区域。然后,点(x,y)的预测金字塔标签∈ Po可按以下方式重新评分。
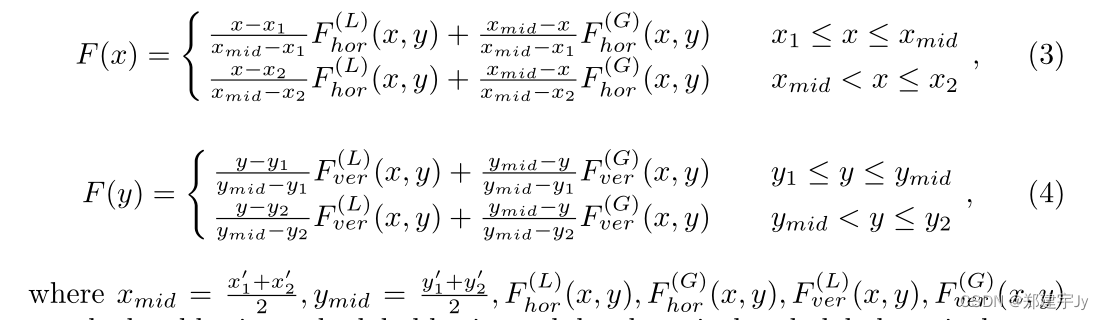
分别是局部水平、全局水平、局部垂直和全局垂直金字塔标签预测。
接下来,对于任何建议区域,可以使用水平和垂直金字塔掩码标签(对应于z坐标)分别拟合三维空间中的两个平面。所有四个平面与零平面的相交线都是细化的边界。例如,为了优化对齐框的右边界,我们选择Pr={p|xmid的所有像素≤ p、 x≤ x2,p∈ Po}与改进的金字塔掩模预测F(x,y)拟合平面。如果我们将平面形成为ax+by+c− z=0,使用最小二乘法,问题等于最小化方程:
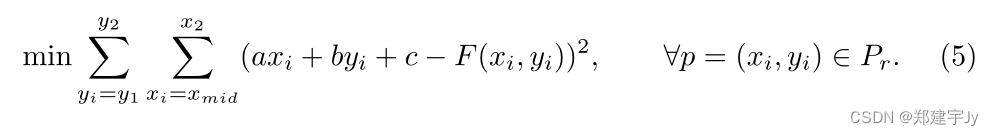
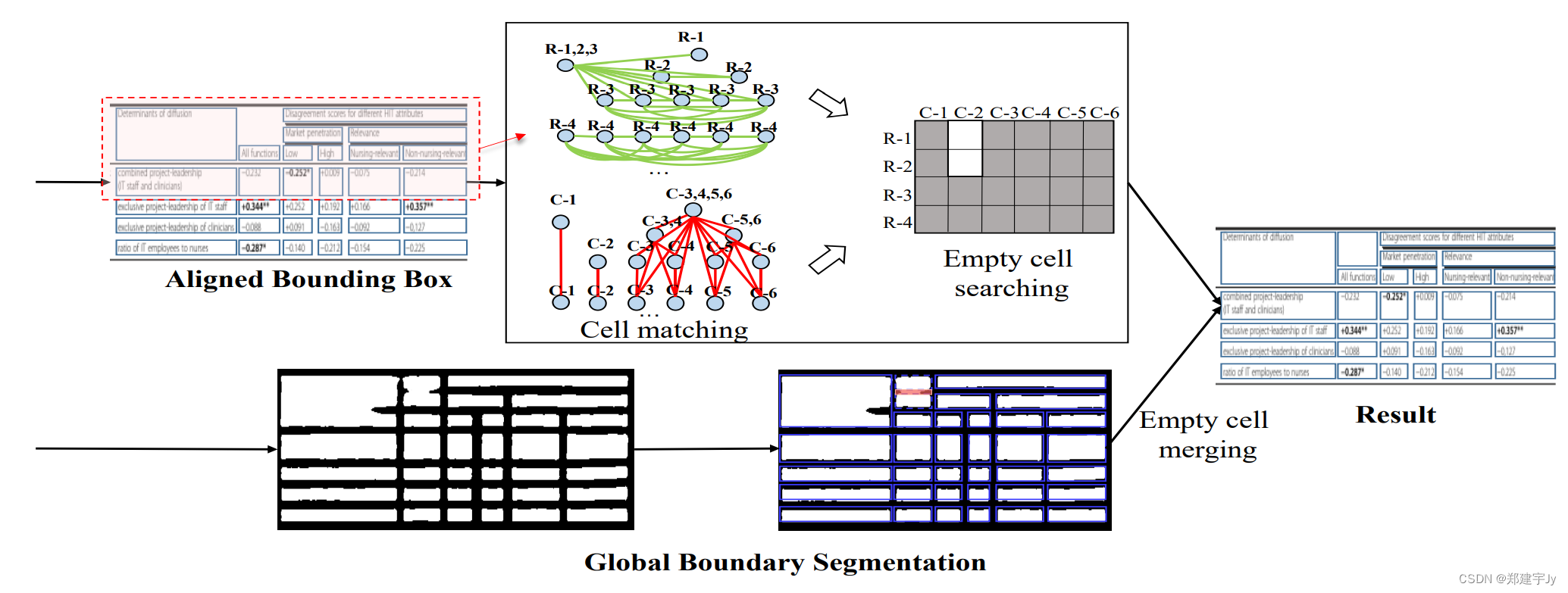
图4.表结构恢复管道的图示。
a、b、c的参数可通过矩阵计算如下:
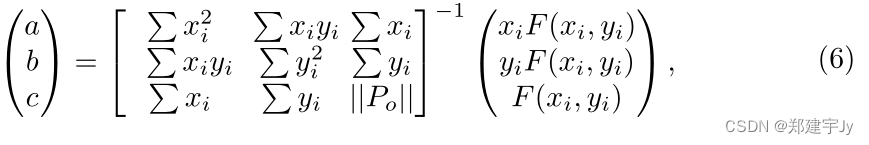
其中||.|是设置的大小。然后,我们计算拟合平面与z=0的平面之间的交线。假设边界框是轴对齐的,我们计算细化的x坐标作为平均值:
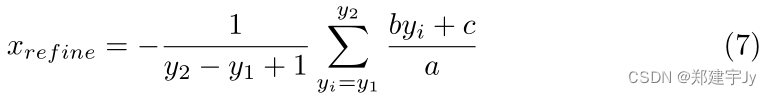
类似地,我们可以获得其他三个细化边界。请注意,精炼过程可以选择性地迭代进行,参见[17]。
表结构恢复。基于精确对齐的边界框,表结构恢复管道旨在获得最终的表结构,包括三个步骤:单元匹配、空单元搜索和空单元合并,如图4所示。
细胞匹配。在所有对齐的边界框都是轴对齐的情况下,单元匹配过程非常简单,但很稳健。按照与[14,2,24]相同的命名约定,连接关系可分为水平类型和垂直类型。其主要思想是,如果两个对齐的边界框在x/y坐标上有足够的重叠,我们将在垂直\水平方向上匹配它们。对于每两个对齐的边界框,
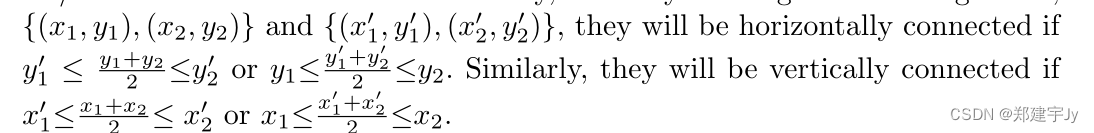
空单元格正在搜索。在获得检测到的对齐边界盒之间的关系后,我们将它们视为图中的节点,连通的关系是边。同一行/列中的所有节点构成一个完整的子图。受[24]的启发,我们采用最大团搜索算法[1]来查找图中的所有最大团。以行搜索过程为例,属于同一行的每个节点都将位于同一集团中。对于跨多行的单元格,相应的节点将在不同的团中出现多次。在按平均ycoordinate对这些团进行排序后,我们可以很容易地用其行索引标记每个节点。出现在多个集团中的节点将使用多个行索引进行标记。我们可以很容易地找到对应于空单元格的那些空缺位置。空单元格合并。到目前为止,我们已经获得了最小级别的空单元格(占用1行1列)。为了更可行地合并这些单元格,我们首先将具有对齐边界框形状的单个空单元格指定为同一行/列中单元格的最大高度/宽度。由于全局分割任务学习到的视觉线索,我们可以根据分割结果设计简单的合并策略。我们计算每两个相邻空单元的间隔区域中预测为1的像素比率,如图4所示的红色区域。如果该比率大于预设阈值,我们将合并这两个单元。正如我们所看到的,空区域的视觉模糊总是存在的,并且分割任务很难被完美地学习。这就是为什么许多基于分割的方法[24,23,22]难以进行复杂的后处理,例如裂缝完成和阈值设置。该方法直接采用全局分割提供的原始视觉线索,并使用像素投票来获得更可靠的结果。
4实验
4.1数据集
4.2实验细节
4.3表格结构识别基准的结果
4.4消融研究
5.结论
本文提出了一种新的表结构识别框架LGPMA。我们采用局部和全局金字塔掩码学习,从局部纹理和全局布局信息两方面折衷的优势。在推理阶段,通过掩码重新评分策略融合两个级别的预测,网络生成更可靠的对齐边界框。最后,我们提出了一个统一的表结构恢复管道来获得最终结果,该管道还可以预测可行的空单元划分。实验结果表明,我们的方法在三个公共基准中达到了最新水平。
















 3533
3533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











