







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

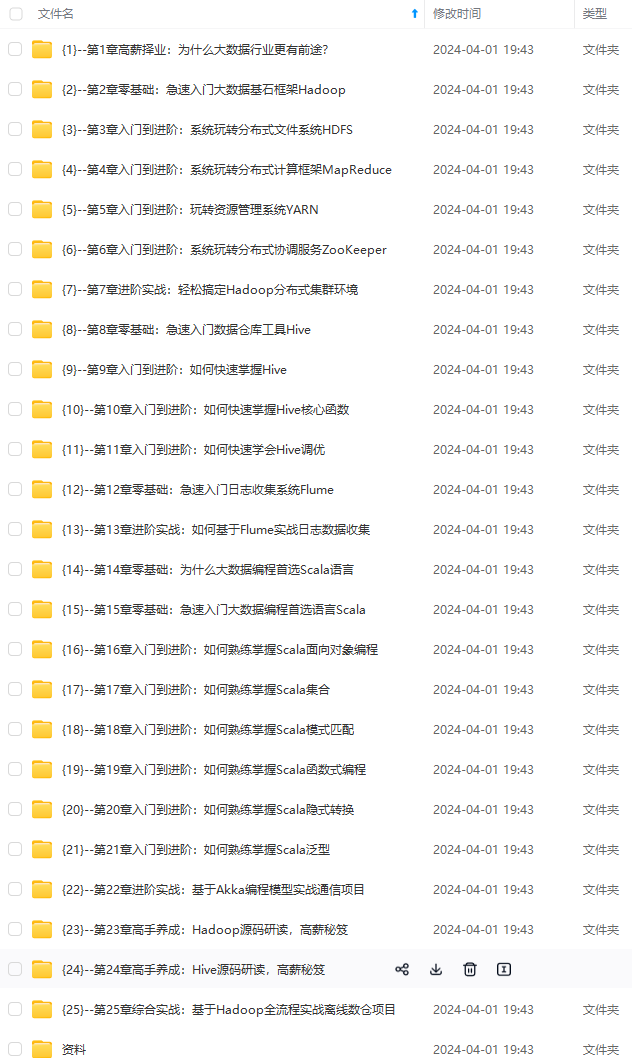
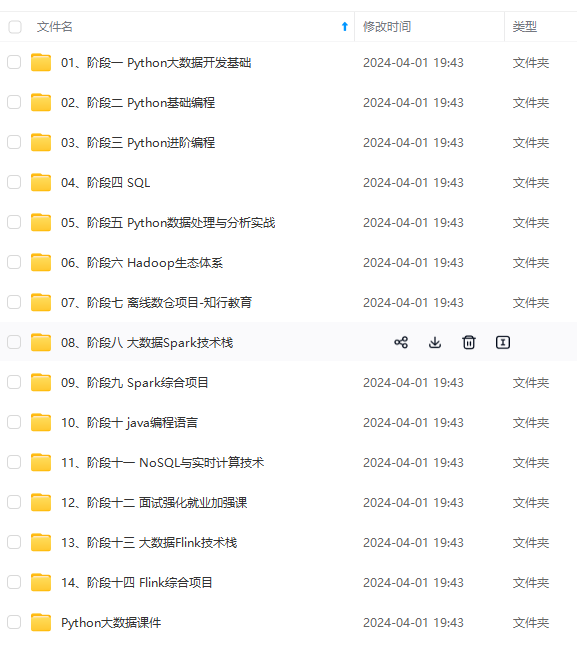
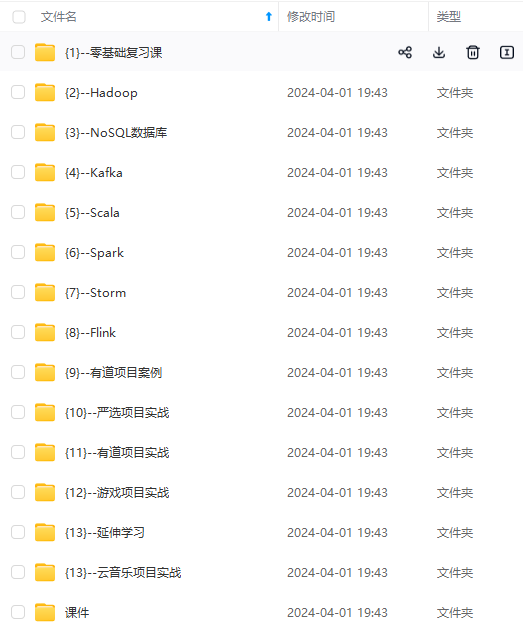
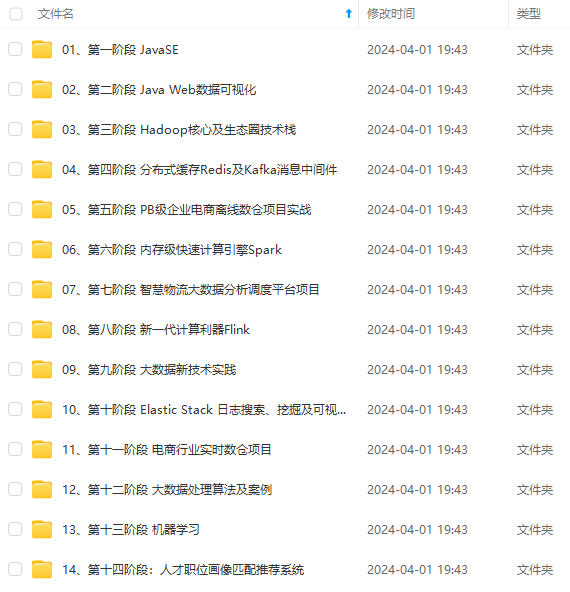
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
Sonnet 是由 DeepMind 发布的,在 TensorFlow 上用于构建复杂神经网络的开源库。
Sonnet 主要用于让 DeepMind 开发的其它模型更容易共享,Sonnet 可以在内部的其它子模块中编写模块,或者在构建新模块时传递其它模型作为参数;同时,Sonnet 提供实用程序来处理这些任意层次结构,以便于使用不同的 RNN 进行实验,整个过程无需繁琐的代码改写。
GitHub 地址:
https://github.com/deepmind/sonnet
八、DL4J star 11.5k fork 4.8k
DL4J 是采用 java 和 jvm 编写的开源深度学习库,支持各种深度学习模型。DL4J 最重要的特点是支持分布式,可以在 Spark 和 Hadoop 上运行,它支持分布式 CPU 和 GPU 运行,并可以利用 Spark 在多台服务器多个 GPU 上开展分布式的深度学习模型训练,让模型运行更快。
DL4J 的基本特性包括:DL4J 中的神经网络训练通过簇的迭代并行计算;整个过程由 Hadoop 和 Spark 架构支持;使用 Java 允许开发者在 Android 设备的程序开发周期中使用。
GitHub 地址:
https://github.com/eclipse/deeplearning4j
III . 适用于强化学习的工具
九、Gym star 19.6k fork 5.5k
Gym 是一个用于开发和比较强化学习算法的工具(https://gym.openai.com/)。
它无需对 agent 的先验知识,并且采用 python 作为主要开发语言,因此可以简单的和 TensorFlow 等深度学习库进行开发集成,同时直观的将学习结果用画面直观的展示出来。Gym 库中包含许多可以用于制定强化学习算法的测试问题(即环境),这些环境有共享接口,允许编写通用的算法。
GitHub 地址:
https://github.com/openai/gym
十、Dopamine star 8.7k fork 1.1k
一款基于 Tensorflow 的框架,旨在为新手和经验丰富的强化学习研究人员提供兼具灵活性、稳定性和可重复性的新工具。
该框架的灵感来源于大脑中奖励-动机行为的主要成分「多巴胺受体」,这反映了神经科学与强化学习研究之间的强大的历史联系,是一个强化学习算法快速原型的研究框架。
GitHub 地址:
https://github.com/google/dopamine
十一、ReAgent star 2.4k fork 312
Facebook 推出的一个构建决策推理系统的模块化端到端平台,用于推理系统(强化学习、上下文管理等), 可以显著简化推理模型构建过程。
ReAgent 由三部分组成:生成决策并接收决策反馈的模型、用于评估新模型部署前性能的模块及快速迭代的服务平台。同时,ReAgent 也是创建基于 AI 的推理系统的最全面、模块化开源平台,并且是第一个包含策略评估的平台,将会加速相关决策系统的部署。
GitHub 地址:
https://github.com/facebookresearch/ReAgent
十二、Tensorlayer star 5.9k fork 1.3k
这是一个面向科学家的深度学习和强化学习库。TensorLayer 由底层到上层可以分为三大模块:神经网络模块、工作流模块、应用模块。
与 Keras 和 Pytorch 相比,TensorLayer 提高了神经网络模块的抽象化设计,同时实现了降低使用现有层和开发新层的工作量。
GitHub 地址:
https://github.com/tensorlayer/tensorlayer
IV . 适用于自然语言处理的工具
十三、BERT star 21.3k fork 5.8k
BERT 是一个基于双向 Transformer 的大规模预训练语言模型,用于对大量未标记的文本数据进行预训练,以学习一种语言表示形式,这种语言表示形式可用于对特定机器学习任务进行微调。
BERT 被称为是 NLP 领域中里程碑的进展;目前,BERT 也是 NLP 深度学习中的重要组成部分,很多之后的自然语言处理模型都是在此基础上优化与改进而得。
GitHub 地址:
https://github.com/google-research/bert
十四、Transformers star 21.7k fork 4.8k
Transformers 是神经机器翻译中使用的一种神经网络,它主要涉及将输入序列转换为输出序列的任务,这些任务包括语音识别和文本转换语音。
这类任务需要「记忆」,下一个句子必须与前一个句的上下文相关联(这是相当关键的),以免丢失重要的信息。通过将 attention 应用到正在使用的单词上,则可以解决当句子太长的时,RNN 或 CNN 无法跟踪上下文和内容的问题。
GitHub 地址:
https://github.com/huggingface/transformers
十五、AllenNLP star 8k fork 1.7k
一个基于 PyTorch 的 NLP 研究库,利用深度学习来进行自然语言理解,通过处理低层次的细节、提供高质量的参考实现,能轻松快速地帮助研究员构建新的语言理解模型。
AllenNLP 能让设计和评估新的深度学习模型变得简单,几乎适用于任何 NLP 问题,通过利用一些基础组件,你可以轻松地在云端或是你自己的笔记本上跑模型。
GitHub 地址:
https://github.com/allenai/allennlp
十六、flair star 8.1k fork 1k
一款简单易用的 Python NLP 库,允许将当前最优自然语言处理(NLP)模型应用于文本,如命名实体识别(NER)、词性标注(PoS)、词义消歧和分类。
Flair 基于 Pytorch 的 NLP 框架,它的接口相对更简单,允许用户使用和结合不同的词嵌入和文档嵌入,包括 Flair 嵌入、BERT 嵌入和 ELMo 嵌入。
GitHub 地址:
https://github.com/flairNLP/flair
十七、spaCy star 15.7k fork 2.8k
这是一个具有工业强度级的 Python 自然语言处理工具包。
它已经成为 Python 中最广泛使用的工业级自然语言库之一,它提供了当前最佳的准确性和效率,并且有一个活跃的开源社区支持。
GitHub 地址:
https://github.com/explosion/spaCy
十八、fastText star 20.5k fork 3.9k
FastText 是 Facebook 人工智能研究实验室(FAIR)开源的一个文本处理库,他是一个专门用于文本分类和外文本表示的库,用于高效文本分类和表示学习。
fastText 的核心是使用「词袋」的方式,不管文字的顺序;但它不是线性的,而是使用分层分类器来将时间复杂度降低到对数级别,并且在具有更高分类数量的大数据集上更高效。
GitHub 地址:
https://github.com/facebookresearch/fastText
V . 适用于语音识别的工具
十九、Kaldi star 8.2k fork 3.7k
Kaldi 是目前使用广泛的开发语音识别应用的框架。
该语音识别工具包使用了 C ++编写,研究开发人员利用 Kaldi 可以训练出语音识别神经网路模型,但如果需要将训练得到的模型部署到移动端设备上,通常需要大量的移植开发工作。
GitHub 地址:
https://github.com/kaldi-asr/kaldi
二十、DeepSpeech star 13k fork 2.4k
DeepSpeech 是一个开源语音转文本引擎,使用基于百度深度语音研究论文的机器学习技术训练的模型。其中,该项目运用到了 Google 的 TensorFlow 来简化实施过程。
GitHub 地址:
https://github.com/mozilla/DeepSpeech
二十一、wav2letter star 4.8k fork 770
这是由 Facebook 人工智能研究院发布的首个全卷积自动语音识别工具包,它是一个简单高效的端到端自动语音识别(ASR)系统。
wav2letter 的核心设计基于三个关键原则,包括:实现在包含成千上万小时语音数据集上的高效模型训练;简单可扩展模型,可以接入新的网络架构、损失函数以及其他语音识别系统中的核心操作;以及平滑语音识别模型从研究到生产部署的过渡。
GitHub 地址:
https://github.com/facebookresearch/wav2letter
VI . 适用于计算机视觉的工具
二十二、YOLO star 16.2k fork 10.4k
YOLO 是当前深度学习领域解决图像检测问题最先进的实时系统。在检测过程中,YOLO 首先将图像划分为规定的边界框,然后对所有边界框并行运行识别算法,来确定物体所属的类别。确定类别之后,YOLO 再智能地合并这些边界框,在物体周围形成最优边界框。
这些步骤全部并行进行,因此 YOLO 能够实现实时运行,并且每秒处理多达 40 张图像。据官网显示,在 Pascal Titan X 上,它以 30 FPS 的速度处理图像,并且在 COCO 测试开发中的 mAP 为 57.9%。
GitHub 地址:
https://github.com/allanzelener/YAD2K
二十三、OpenCV star 41.9k fork 32.4k
OpenCV 是英特尔开源的跨平台计算机视觉库(https://opencv.org),被称为 CV 领域开发者与研究者的必备工具包。
这是一套包含从图像预处理到预训练模型调用等大量视觉 API 的库,并可以处理图像识别、目标检测、图像分割和行人再识别等主流视觉任务。其最显著的特点是它提供了整套流程的工具,因此开发者无需了解各个模型的原理就能用 API 构建视觉任务。它具备 C++、Python 和 Java 接口,支持 Windows、Linux、Mac OS、iOS 和 Android 系统。
GitHub 地址:
https://github.com/opencv/opencv
二十四、Detectron2 star 7.7k fork 1.4k
Detectron2 则是 PyTorch 1.3 中一重大新工具,它源于 maskrcnn 基准测试,也是对先前版本 detectron 的一次彻底重写。
Detectron2 通过全新的模块化设计,变得更灵活且易于扩展,它能够在单个或多个 GPU 服务器上提供更快速的训练速度,包含了更大的灵活性与扩展性,并增强了可维护性和可伸缩性,以支持在生产中的用例。
GitHub 地址:
https://github.com/facebookresearch/detectron2
二十五、OpenPose star 15.9k fork 4.7k
OpenPose 人体姿态识别项目是美国卡耐基梅隆大学(CMU)基于卷积神经网络和监督学习并以 caffe 为框架开发的开源库。
它可以实现人体动作、面部表情、手指运动等姿态估计。适用于单人和多人,具有极好的鲁棒性。是世界上首个基于深度学习的实时多人二维姿态估计应用,很多人体姿态估计实例都是基于它实现,如动作采集、3D 试衣、绘画辅助等。
GitHub 地址:
https://github.com/CMU-Perceptual-Computing-Lab/openpose
二十六、facenet star 10k fork 4.1k
FaceNet 采用了深度卷积神经网络(CNN)学习将图像映射到欧式空间,也被称为通用人脸识别系统。
该系统可从人脸中提取高质量的特征,称为人脸嵌入(face embeddings),可用于训练人脸识别系统,从而实现对人脸的验证。它在 LFW 数据集上测试的准确率达到了 99.63%,在 YouTube Faces DB 数据集上准确率为 95.12%。
GitHub 地址:
https://github.com/davidsandberg/facenet
VII . 适****用于分布式训练的工具
二十七、Spark MLlib star 25.1k fork 21.1k
Spark 是一个开源集群运算框架,也是现在大数据领域热门开源软件之一(https://spark.apache.org/mllib/)。
由于 Spark 使用了内存内运算技术,它在内存上的运算速度比 Hadoop MapReduce 的运算速度快上 100 倍;这也使得 Spark MLlib 分布式计算框架运行非常高效、快速。它可以实现大部分机器学习,如:聚类、分类、回归等算法,并允许将数据加载至集群内存,多次对其进行查询,所以非常适合用于机器学习算法。
GitHub 地址:
https://github.com/apache/spark
二十八、Mahout star 1.8k fork 930
Mahout 是一个分布式线性代数框架,用于快速创建可扩展的高性能机器学习应用程序(http://mahout.apache.org/ )。
Mahout 框架长期以来一直与 Hadoop 绑定,但它的许多算法也可以在 Hadoop 之外运行。它允许多种算法可以跨越分布式 Spark 群集上运行,并且支持 CPU 和 GPU 运行。
GitHub 地址:
https://github.com/apache/mahout
二十九、Horovod star 8.5k fork 1.3k
这是由 Uber 开源的一个跨多台机器的分布式深度学习的 TensorFlow 训练框架,可以使分布式深度学习快速且易于使用。
据介绍,Horovod 让开发人员只需几行代码就可以完成任务。这不仅加快了初始修改过程,而且进一步简化了调试。考虑到深度学习项目的高度迭代性,这也可以节省大量时间。除此之外,它还结合了高性能和修补低级模型细节的能力,例如:同时使用高级 api,并使用 NVIDIA 的 CUDA 工具包实现自己的自定义操作符。
GitHub 地址:
https://github.com/horovod/horovod
三十、Dask star 6.2k fork 994
当开发者需要并行化到多核时,可以用 Dask 来将计算扩展到多个内核甚至多个机器。
Dask 提供了 NumPy Arrays,Pandas Dataframes 和常规列表的抽象,能够在无法放入主内存的数据集上并行运行。对大型数据集来说,Dask 的高级集合是 NumPy 和 Pandas 的替代方案。
GitHub 地址:
https://github.com/dask/dask
三十一、Ray star 10.3k fork 1.5k
Ray 是一个高性能分布式执行框架,它使用了和传统分布式计算系统不一样的架构和对分布式计算的抽象方式,用于快速而简单的构建和运行分布式应用程序。
Ray 按照典型的 Master-Slave 进行设计。其中,Master 负责全局协调和状态维护,Slave 执行分布式计算任务。不过和传统的分布式计算系统不同的是,Ray 使用了混合任务调度的思路,性能更强。
GitHub 地址:
https://github.com/ray-project/ray
VIII . 适用于自动建模的工具
三十二、TPOT star 6.7k fork 1.2k
TPOT 是一个 Python 编写的软件包,利用遗传算法行特征选择和算法模型选择,仅需几行代码,就能生成完整的机器学习代码。
在机器学习模型开发图中,TPOT 所完成的即通过利用遗传算法,分析数千种可能的组合,为模型、参数找到最佳的组合,从而自动化机器学习中的模型选择及调参部分。
GitHub 地址:
https://github.com/EpistasisLab/tpot
三十三、AutoKeras star 6.6k fork 1.1k
它使用了高效神经架构搜索(ENAS,https://arxiv.org/abs/1802.03268),只需使用 pip install autokeras 就能快速轻松地安装软件包,然后就能用自己的数据集来执行自己的架构搜索构建思路。
相比谷歌 AutoML,两者构建思路类似,但不同的是,AutoKeras 所有代码都已经开源,可供开发者无偿使用。
GitHub 地址:
https://github.com/keras-team/autokeras
三十四、Featuretools star 4.6k fork 602
这是一个用于自动化特性工程的开源 python 框架(https://www.featuretools.com/)。
它可以帮助开发者从一组相关数据表中自动构造特征。开发者只需要知道数据表的基本结构和它们之间的关系,然后在实体集(一种数据结构)中指明。然后在有了实体集之后,使用一个名为深度特征合成(DFS)的方法,在一个函数调用中构建出数千个特征。
GitHub 地址:
https://github.com/FeatureLabs/featuretools
三十五、NNI star 5.3k fork 683
NNI 是由微软发布的一个用于神经网络超参数调整的开源 AutoML 工具包,也是目前较为热门的 AutoML 开源项目之一。
最新版本的 NNI 对机器学习生命周期的各个环节做了更加全面的支持,包括:特征工程、神经网络架构搜索(NAS)、超参调优和模型压缩,开发者都能使用自动机器学习算法来完成,即使是开发小白也能轻松上手。
GitHub 地址:
https://github.com/microsoft/nni
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
它们之间的关系,然后在实体集(一种数据结构)中指明。然后在有了实体集之后,使用一个名为深度特征合成(DFS)的方法,在一个函数调用中构建出数千个特征。
GitHub 地址:
https://github.com/FeatureLabs/featuretools
三十五、NNI star 5.3k fork 683
NNI 是由微软发布的一个用于神经网络超参数调整的开源 AutoML 工具包,也是目前较为热门的 AutoML 开源项目之一。
最新版本的 NNI 对机器学习生命周期的各个环节做了更加全面的支持,包括:特征工程、神经网络架构搜索(NAS)、超参调优和模型压缩,开发者都能使用自动机器学习算法来完成,即使是开发小白也能轻松上手。
GitHub 地址:
https://github.com/microsoft/nni
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)
[外链图片转存中…(img-rIYvu5u1-1713407785494)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1737
1737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









