








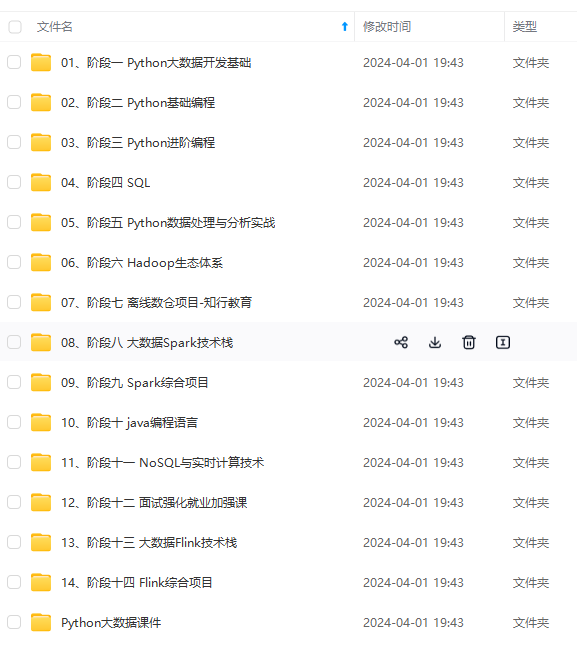
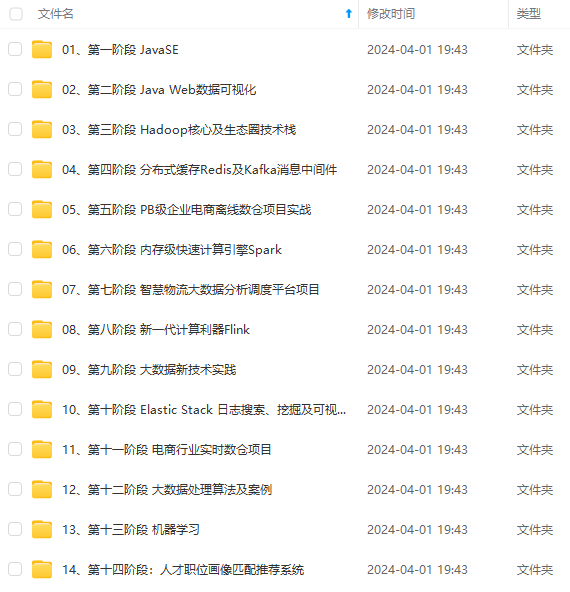
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
```
+ 查看模式
```
docker network ls
```
+ 删除
```
docker network rm ……
```
-
小结
- 了解Docker的网络管理设计
08:Docker的使用
-
目标:了解docker的基本使用
-
路径
- step1:docker管理
- step2:image管理
- step3:container管理
-
实施
-
docker管理
- 默认开机自启
- 了解即可,不用操作
- 启动服务
systemctl start docker- 查看状态
systemctl status docker- 关闭服务
systemctl stop docker -
image管理
- 了解即可,不用操作
- 添加镜像
docker pull registry.cn-hangzhou.aliyuncs.com/helowin/oracle_11g- 列举镜像
docker images- 移除镜像
docker rmi …… -
container管理
- 熟悉常用操作
- 创建并启动container:不用做
docker run --net docker-bd0 --ip 172.33.0.100 -d -p 1521:1521 --name oracle 3fa112fd3642* run = create + start- 列举container
#列举所有的 docker ps -a #列举正在运行的 docker ps- 进入container
docker exec -it Name bash- 退出container
exit- 删除container
docker rm ……
-
-
小结
- 了解docker的基本使用
09:Oracle的介绍
-
目标:了解Oracle工具的基本功能和应用场景
-
路径
- step1:数据库分类
- step2:Oracle的介绍
-
实施
-
数据库分类
- RDBMS:关系型数据库管理系统
- 工具:MySQL、Oracle、SQL Server……
- 应用:业务性数据存储系统:事务和稳定性
- 特点:体现数据之间的关系,支持事务,保证业务完整性和稳定性,小数据量的性能也比较好
- 开发:SQL
- NoSQL:Not Only SQL:非关系型数据库
- 工具:Redis、HBASE、MongoDB……
- 分类:KV、文档、时序、图……
- 应用:一般用于高并发高性能场景下的数据缓存或者数据库存储
- 特点:读写速度特别快,并发量非常高,相对而言不如RDBMS稳定,对事务性的支持不太友好
- 开发:每种NoSQL都有自己的命令语法
- RDBMS:关系型数据库管理系统
-
Oracle的介绍
-
概念:甲骨文公司的一款关系数据库管理系统
- Oracle在古希腊神话中被称为“神谕”,指的是上帝的宠儿
- 在中国的商周时期,把一些刻在龟壳上的文字也称为上天的指示,所以在中国Oracle又翻译为甲骨文
- Oracle是现在全世界最大的数据库提供商,编程语言提供商,应用软件提供商,它的地位等价于微软的地位
-
分类:RDBMS,属于大型RDBMS数据库
- 大型数据库:IBM DB2、Oracle、Sybase
- 中型数据库:SQL Server、MySQL、Informix、PostgreSQL
- 小型数据库:Access、Visual FoxPro、SQLite
-
功能:实现大规模关系型数据存储
-
特点
- 功能全面:数据字典、动态性能视图、TRACE跟踪、AWR、ASH、SQL Monitor等
- 性能优越:支持SQL大量的表连接、子查询、集合运算,长度可达上千行
- 数据量大:相比较于其他的数据库,Oracle支持千万级别以上的数据高性能存储
- 高可靠性:基于Oracle自带的RAC架构下,可靠性和稳定性相对比较高
-
综合排名

-
应用
- 中国各大银行、电信、政府单位等机构所有系统
-
趋势
- 去IOE【IBM服务器、Oracle数据库、EMC存储】
-
-
-
小结
- 了解Oracle工具的基本功能和应用场景
10:集群软件规划
- 目标:了解项目的集群软件规划
- 实施
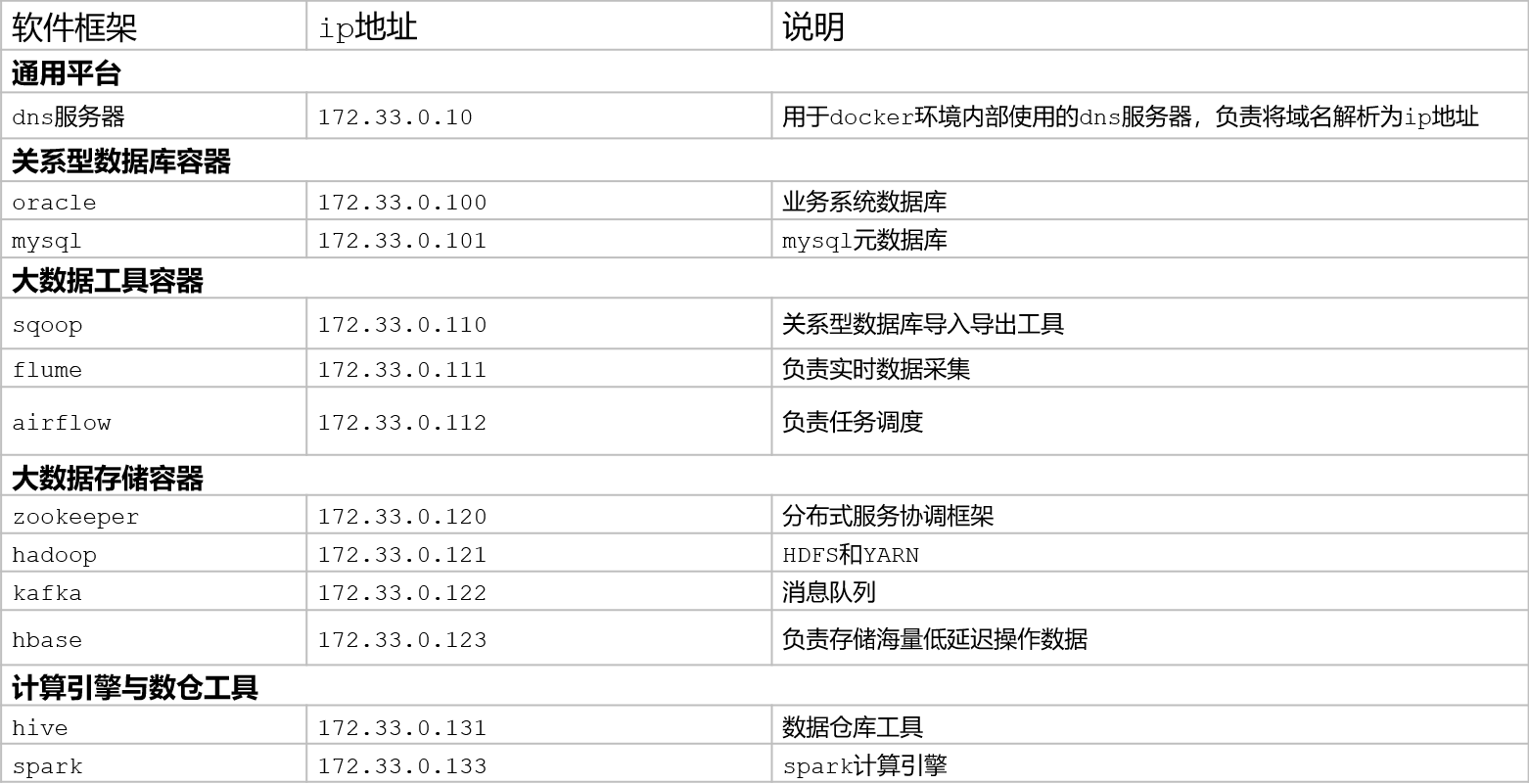
172.33.0.100 oracle.bigdata.cn
172.33.0.110 sqoop.bigdata.cn
172.33.0.121 hadoop.bigdata.cn
172.33.0.131 hive.bigdata.cn
172.33.0.133 spark.bigdata.cn
-
小结
- 了解项目的集群软件规划
11:项目环境导入
-
目标:实现项目虚拟机的导入
-
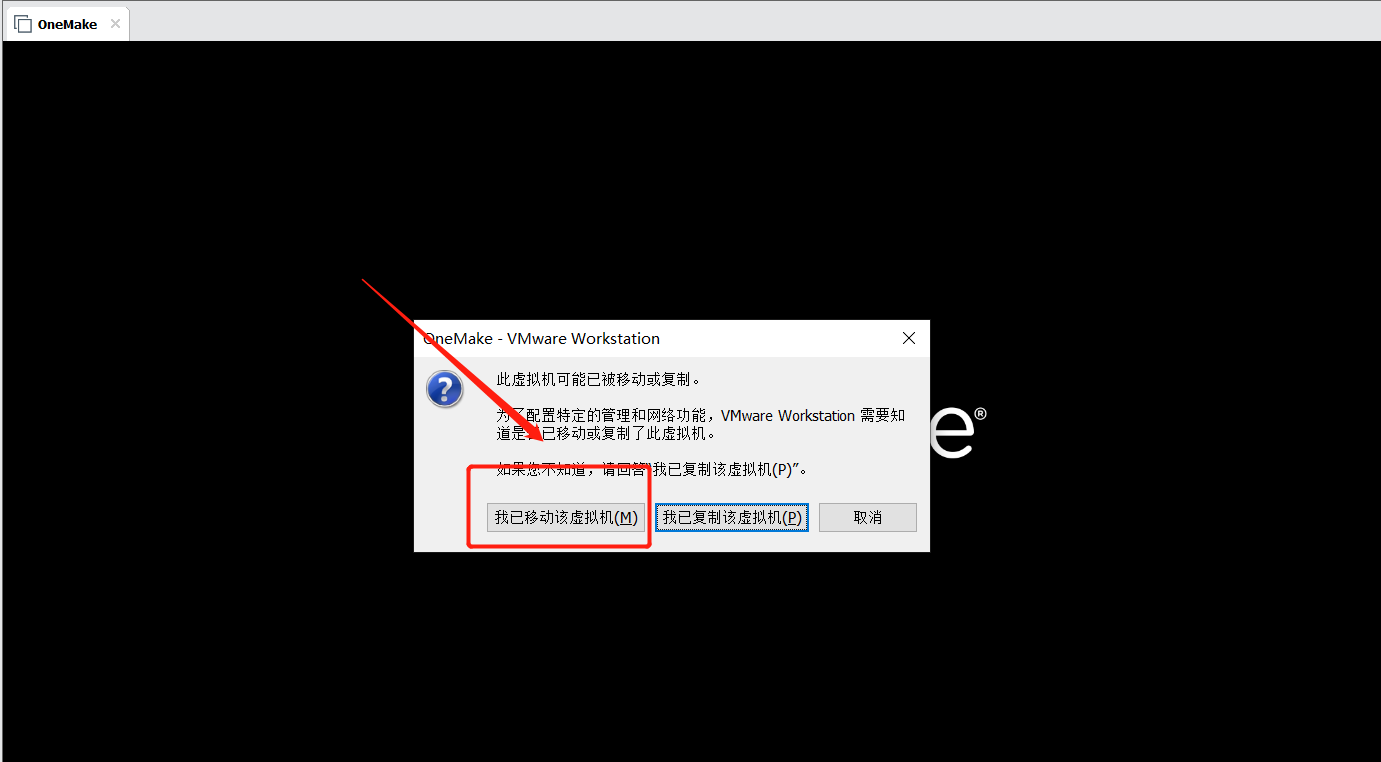
实施
- step1:导入:找到OneMake虚拟机中以.vmx结尾的文件,使用VMware打开


- step2:启动:启动导入的虚拟机,选择我已移动该虚拟机
-
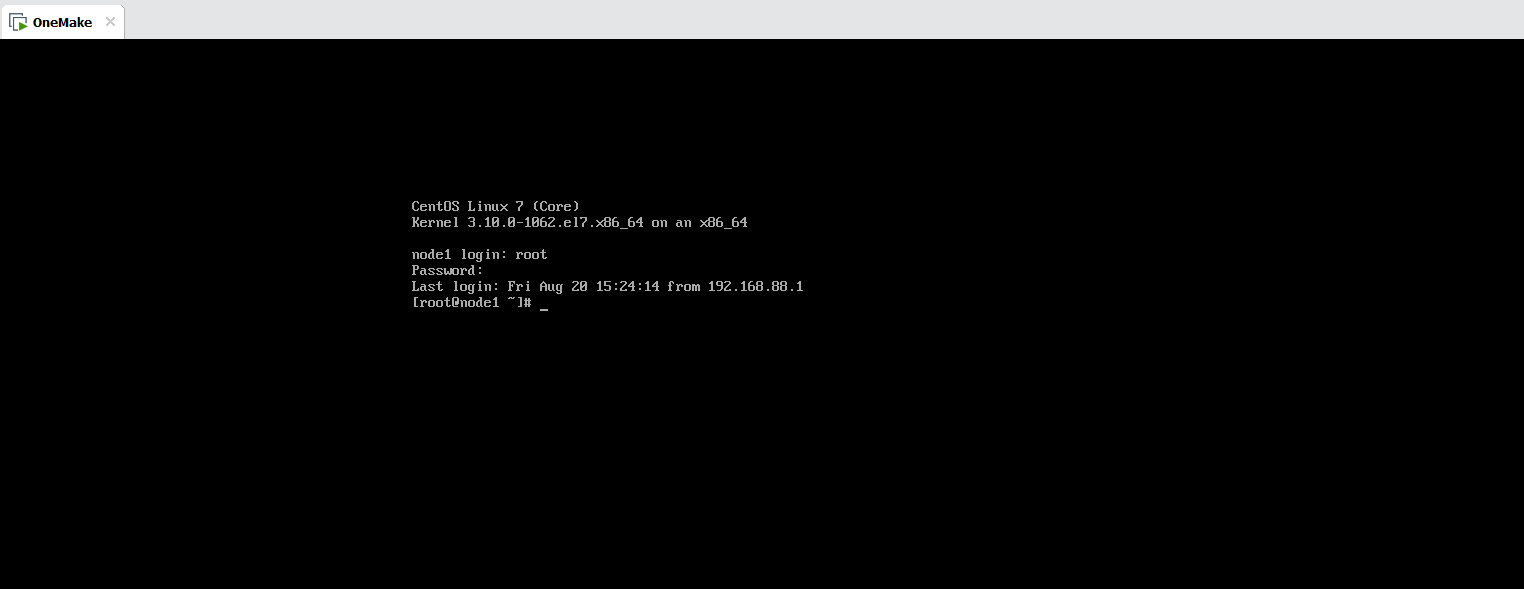
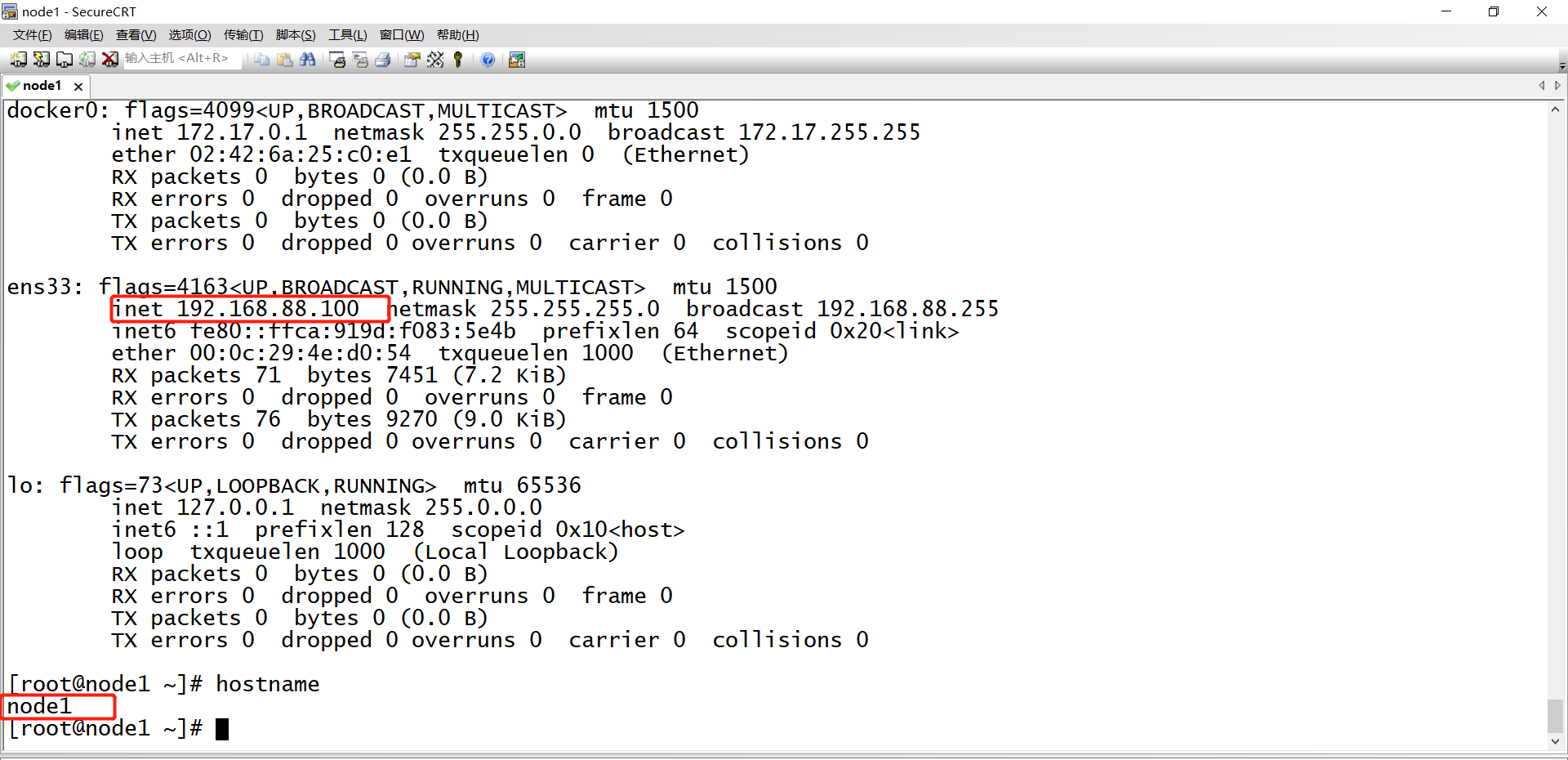
step3:登陆:登陆到虚拟机内部,或者使用远程工具连接
- 默认IP:192.168.88.100
- 主机名:node1
- 用户名:root
- 密码:123456
-
小结
- 实现项目虚拟机的导入
12:项目环境配置
-
目标:根据需求实现项目环境配置
-
实施
-
注意:所有软件Docker、Hadoop、Hive、Spark、Sqoop都已经装好,不需要额外安装配置,启动即可
-
配置网络:如果你的VM Nat网络不是88网段,请按照以下修改
- 修改Linux虚拟机的ens33网卡,网卡和网关,修改为自己的网段
vim /etc/sysconfig/network-scripts/ifcfg-ens33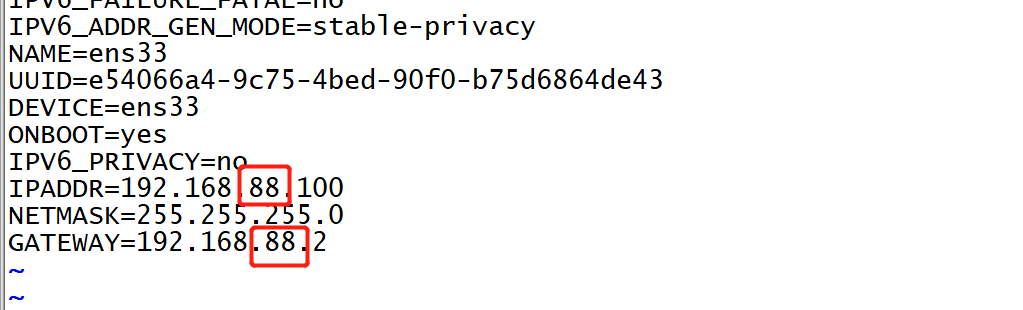
- 重启网卡
systemctl restart network- 查看是否修改成功
ifconfig -
配置映射
- 修改Linux映射,修改为自己的网段
vim /etc/hosts- 配置Windows上的映射,方便使用主机名访问【把以前的有冲突的注释掉】192.168.88.100 oracle.bigdata.cn
192.168.88.100 hadoop.bigdata.cn
192.168.88.100 hive.bigdata.cn
192.168.88.100 mysql.bigdata.cn
192.168.88.100 node1
 -
-
小结
- 根据需求实现项目环境配置
13:项目环境测试:Oracle
-
目标:实现项目Oracle环境的测试
-
实施
- 启动
docker start oracle- 进入
docker exec -it oracle bash- 连接
#进入客户端命令行:/nolog表示只打开,不登录,不用输入用户名和密码 sqlplus /nolog #登陆连接服务端:/ as sysdba表示使用系统用户登录 conn / as sysdba- 测试select TABLE_NAME from all_tables where TABLE_NAME LIKE ‘CISS_%’;
- 退出
exit
- 远程连接:DG
- step1:安装DG
- step2:创建连接
- SID:helowin
- 用户名:ciss
- 密码:123456
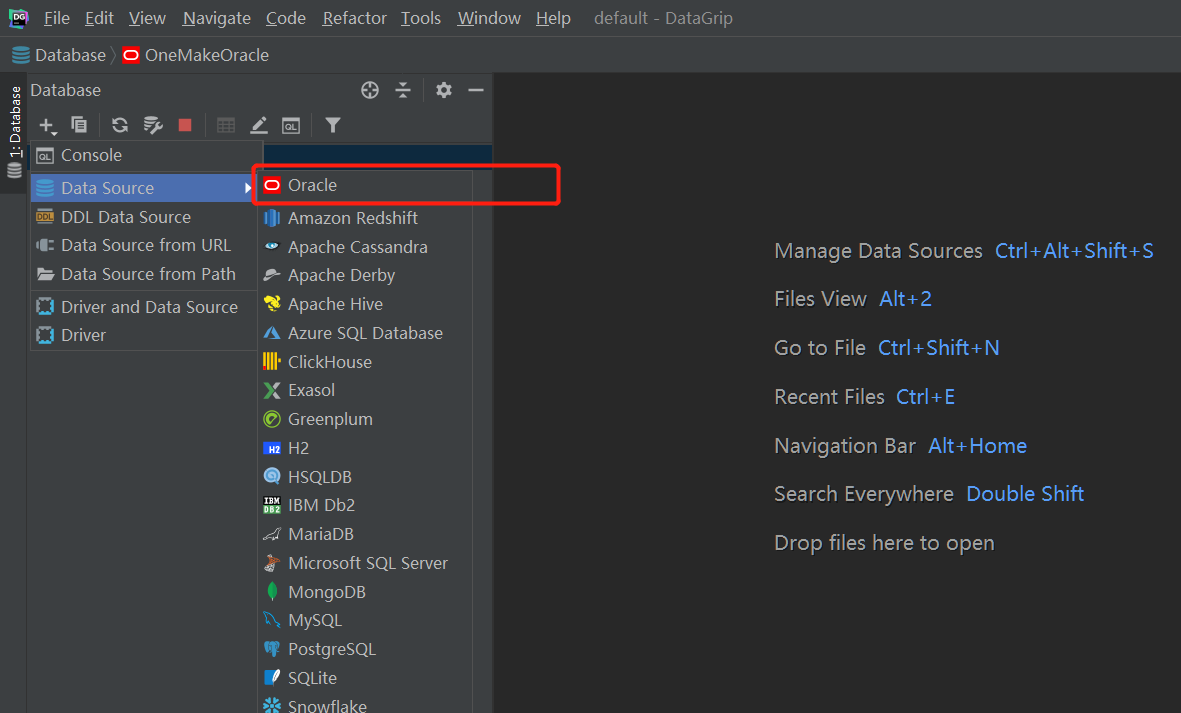

- step3:配置驱动包
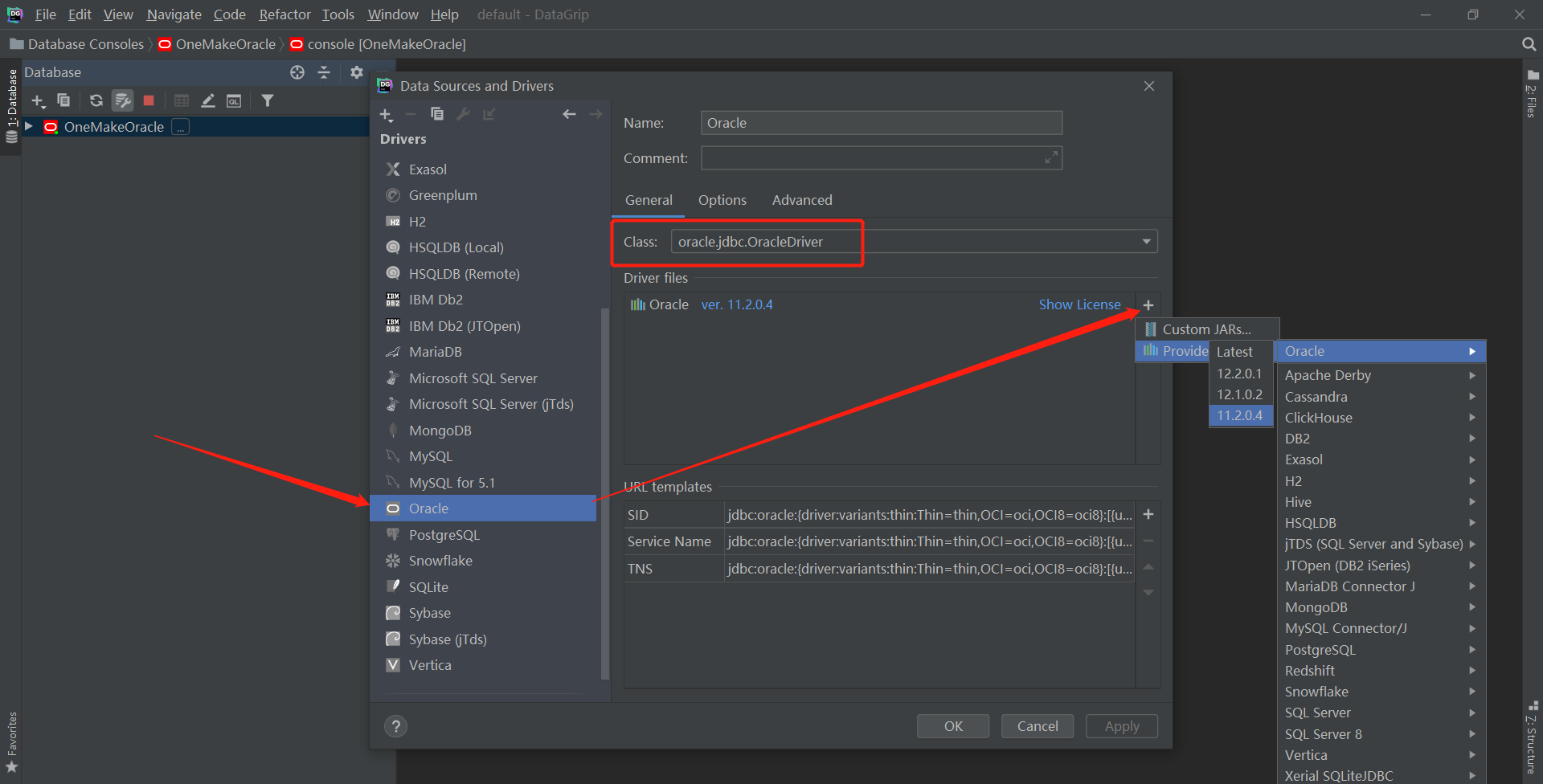
- step4:配置JDK
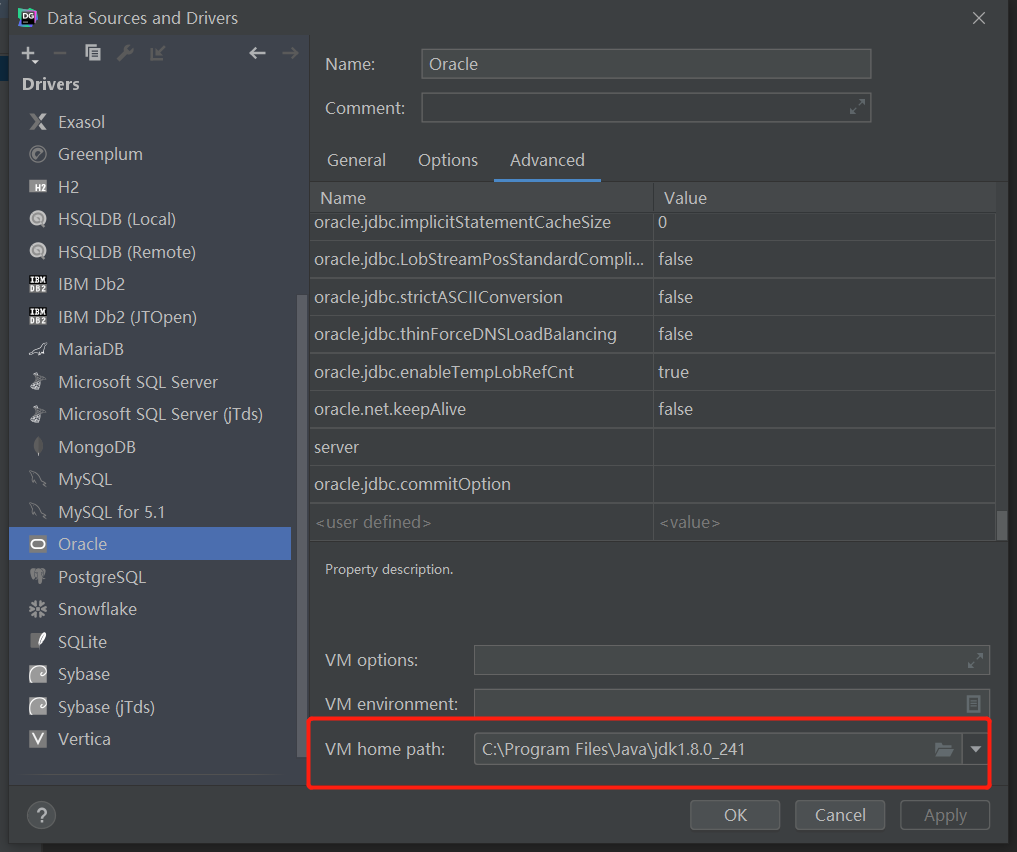
- step5:测试
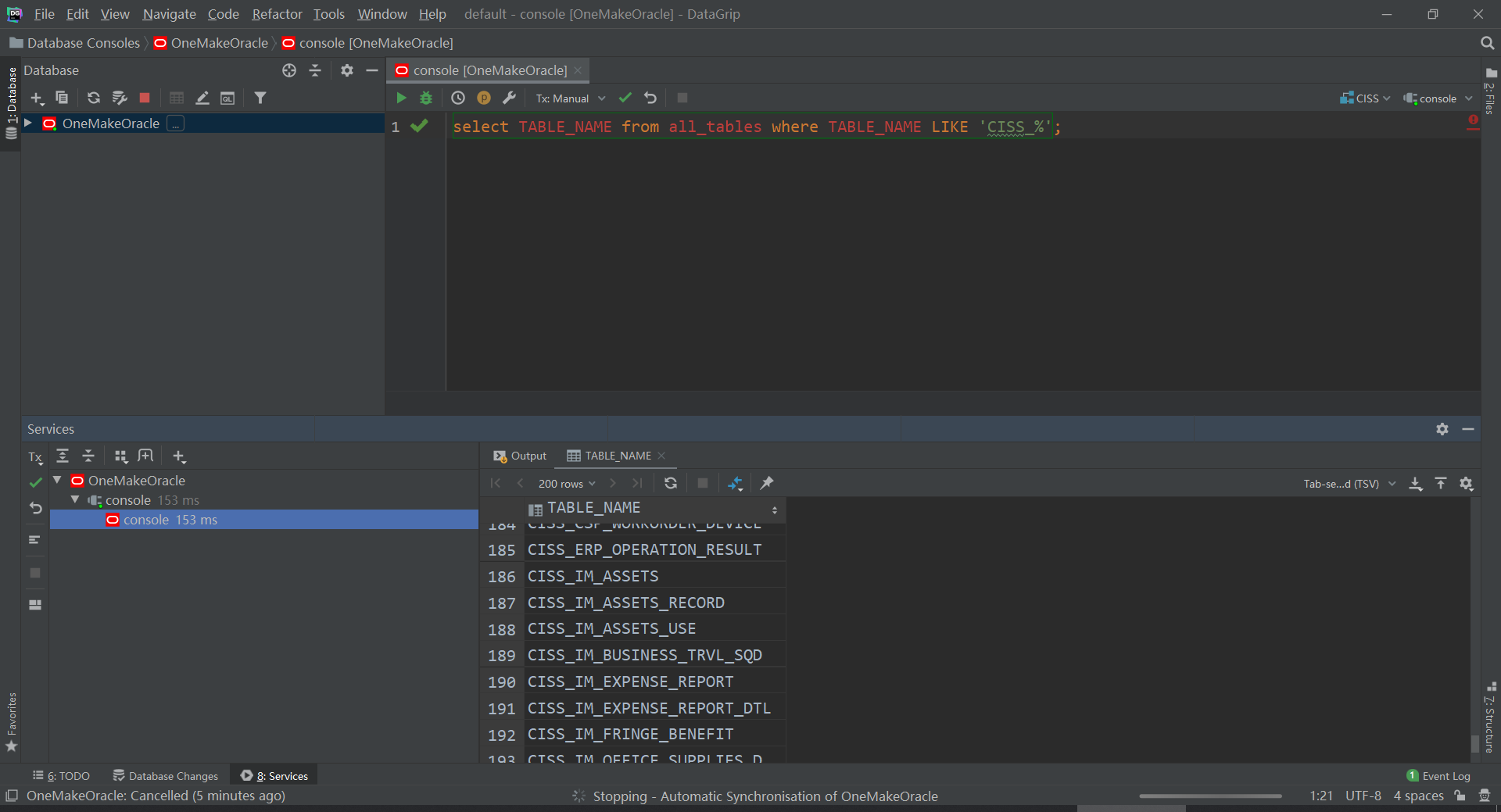
- 关闭
docker stop oracle
-
小结
- 实现项目Oracle环境的测试
14:项目环境测试:MySQL
-
目标:实现项目MySQL环境的测试
-
实施
-
大数据平台中自己管理的MySQL:两台机器
- 存储软件元数据:Hive、Sqoop、Airflow、Oozie、Hue
- 存储统计分析结果
-
注意:MySQL没有使用Docker容器部署,直接部署在当前node1宿主机器上
-
启动/关闭:默认开启自启动
-
连接:使用命令行客户端、Navicat、DG都可以
- 用户名:root
- 密码:123456
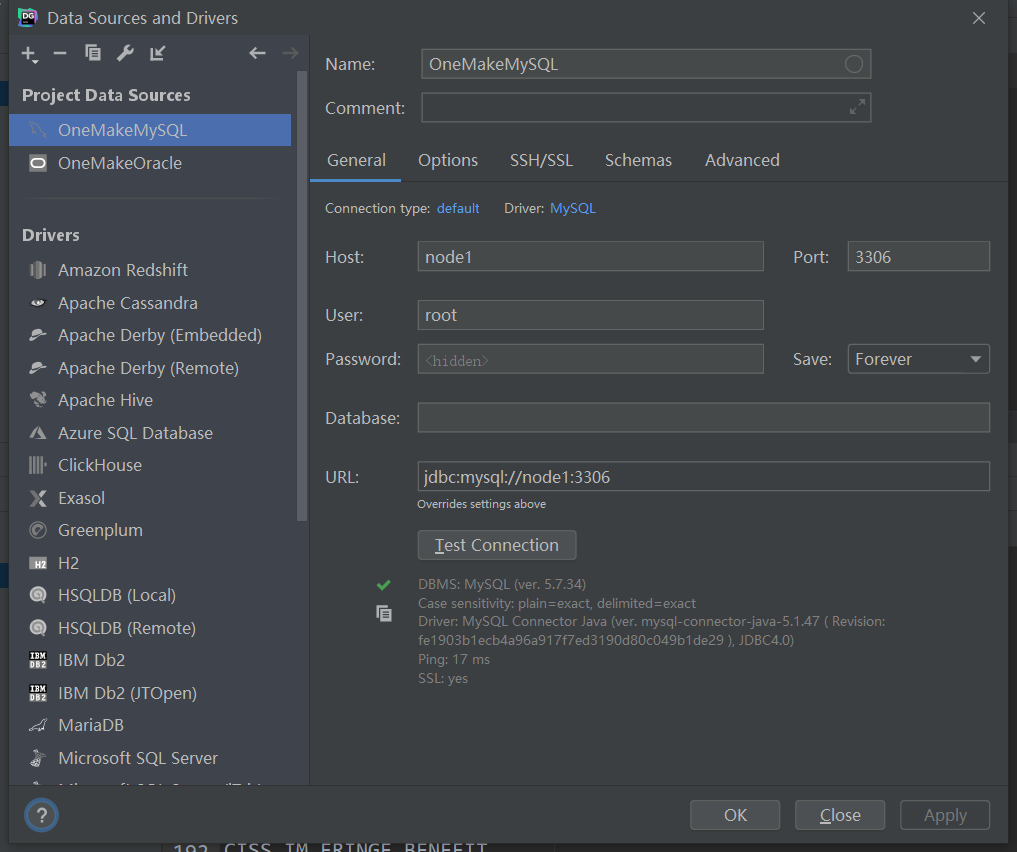
- 查看
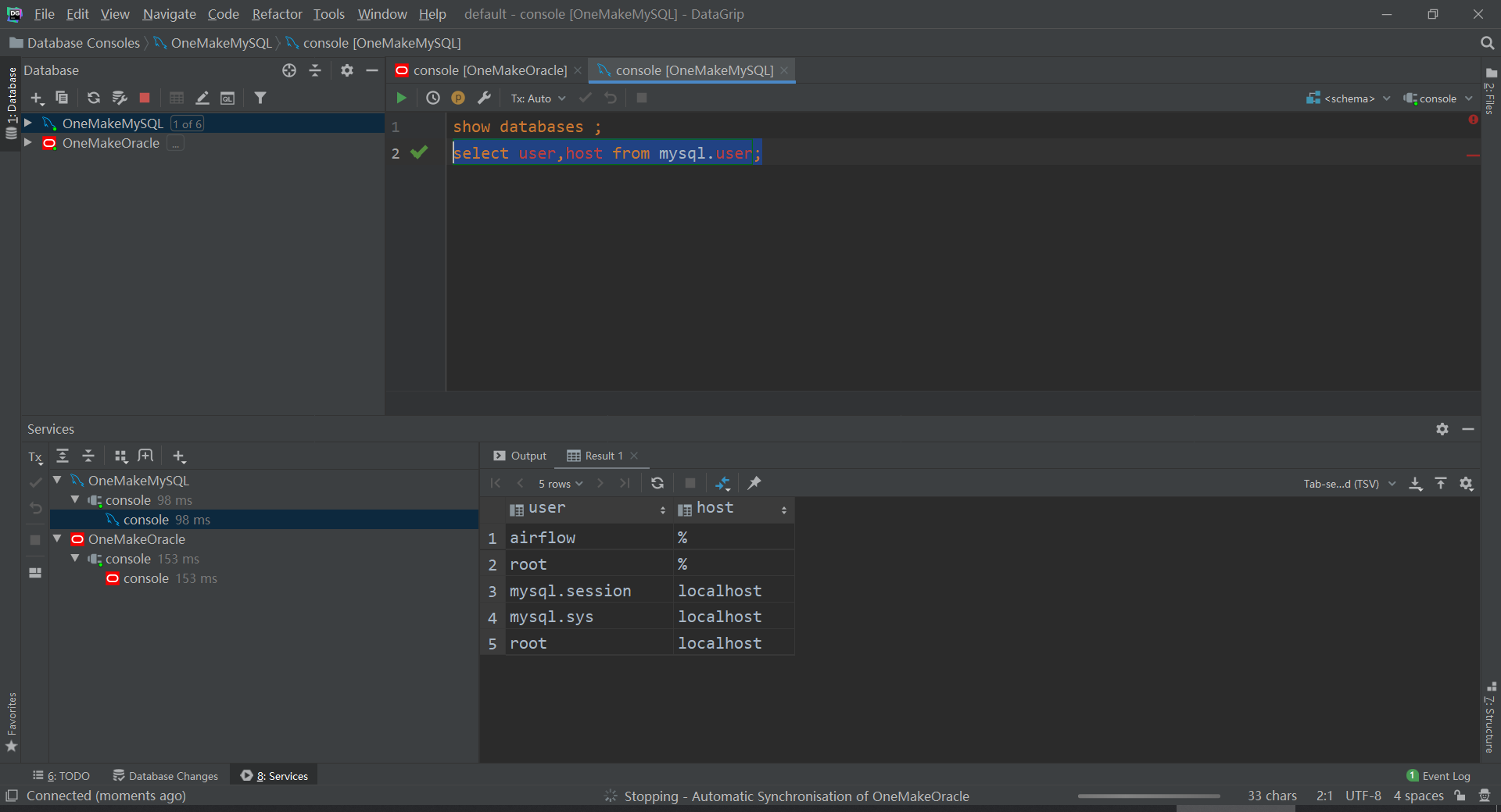
-
-
小结
- 实现项目MySQL环境的测试
15:项目环境测试:Hadoop
-
目标:实现项目Hadoop环境的测试
-
实施
- 启动
docker start hadoop- 进入
docker exec -it hadoop bash- 查看进程
jps- 启动进程
start-dfs.sh start-yarn.sh mr-jobhistory-daemon.sh start historyserver-
访问页面
- node1:50070
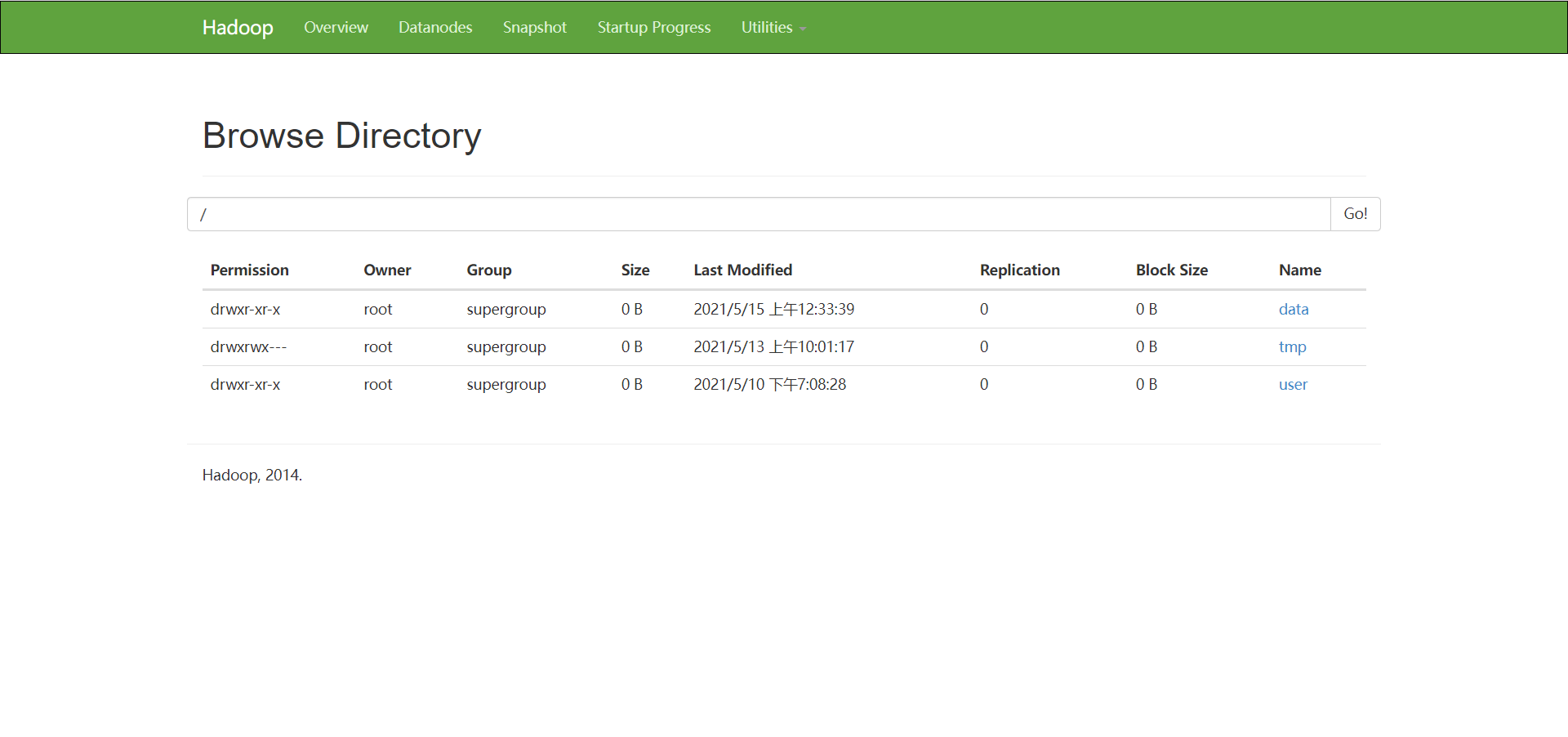
- node1:8088
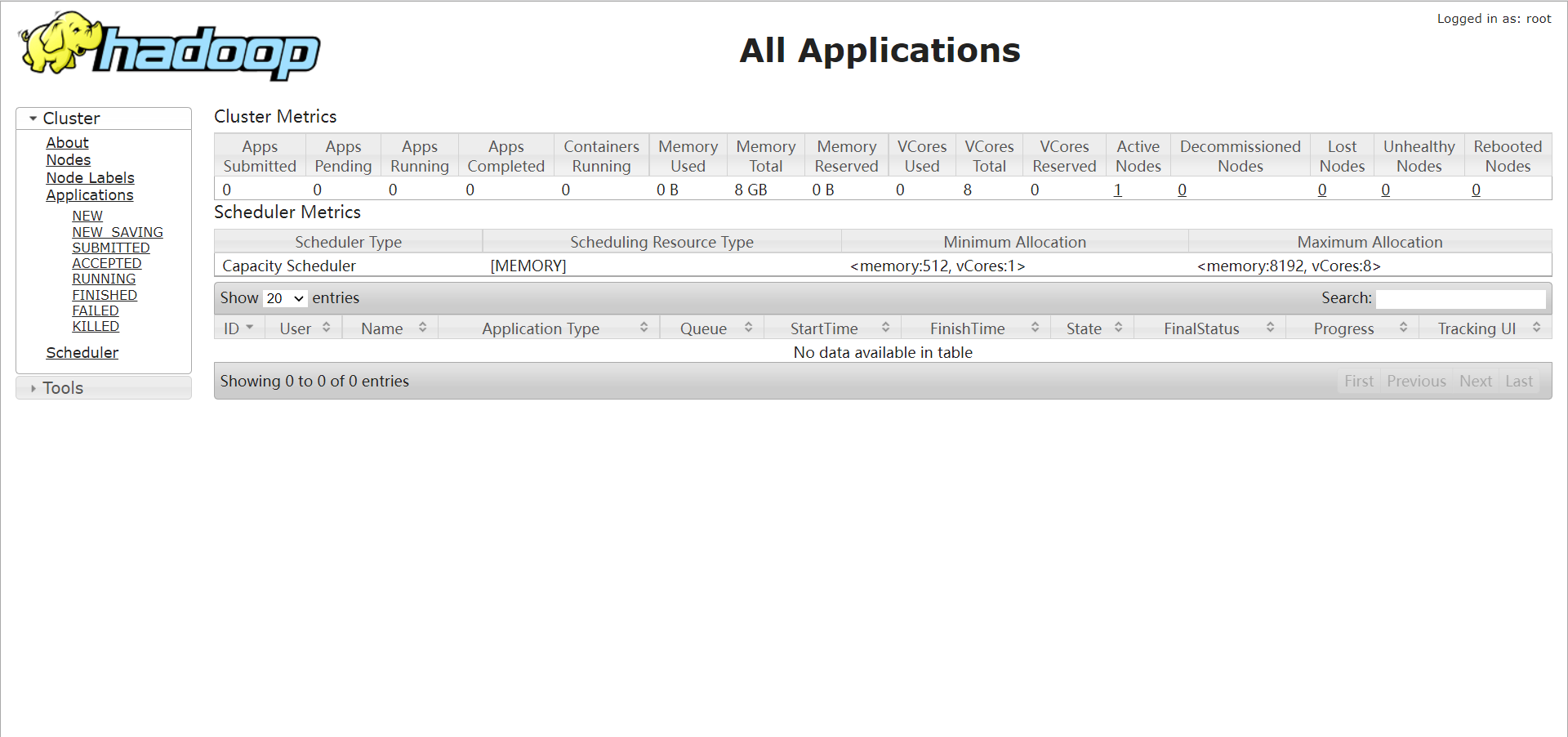
- node1:19888
-
退出
exit- 关闭
docker stop hadoop -
小结
- 实现项目Hadoop环境的测试
16:项目环境测试:Hive
-
目标:实现项目Hive环境的测试
-
实施
- 启动Hive容器
docker start hive- 进入Hive容器
docker exec -it hive bash source /etc/profile- 连接
beeline !connect jdbc:hive2://hive.bigdata.cn:10000 账号为root,密码为123456- SQL测试
select count(1);- Shuffle【分区、排序、分组】三种场景 - 重分区:repartition:分区个数由小变大 * 调用分区器对所有数据进行重新分区 * rdd1 + part0:1 2 3 + part1: 4 5 6 * rdd2:调用分区器【只有shuffle阶段才能调用分区器】 + part0:0 6 + part1:1 4 + part2:2 5 * 全局排序:sortBy + part0:1 2 5 + part1: 4 3 6 + 方案:将所有数据放入磁盘 + 实现:对数据做了范围分区:将所有数据做了采样:4 - part0:6 5 4 - part1:3 2 1 * 全局分组:groupBy,reduceByKey- 关闭Hive容器
docker stop hive -
小结
- 实现项目Hive环境的测试
17:项目环境测试:Spark
-
目标:实现项目Spark环境的测试
-
实施
- 启动Spark容器
docker start spark- 进入Spark容器
docker exec -it spark bash source /etc/profile- 启动Thrift Server【默认已经启动】
start-thriftserver.sh \ --name sparksql-thrift-server \ --master yarn \ --deploy-mode client \ --driver-memory 1g \ --hiveconf hive.server2.thrift.http.port=10001 \ --num-executors 3 \ --executor-memory 1g \ --conf spark.sql.shuffle.partitions=2
- 测试
beeline -u jdbc:hive2://spark.bigdata.cn:10001 -n root -p 123456 select count(1);- 关闭Spark容器
docker stop spark -
小结
- 实现项目Spark环境的测试
18:项目环境测试:Sqoop
-
目标:实现项目Sqoop环境的测试
-
实施
- 启动Sqoop容器
docker start sqoop- 进入Sqoop容器
docker exec -it sqoop bash source /etc/profile- 测试
sqoop list-databases \ --connect jdbc:oracle:thin:@oracle.bigdata.cn:1521:helowin \ --username ciss \ --password 123456
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
18:项目环境测试:Sqoop
-
目标:实现项目Sqoop环境的测试
-
实施
- 启动Sqoop容器
docker start sqoop- 进入Sqoop容器
docker exec -it sqoop bash source /etc/profile- 测试
sqoop list-databases \ --connect jdbc:oracle:thin:@oracle.bigdata.cn:1521:helowin \ --username ciss \ --password 123456
[外链图片转存中…(img-OFF9N6cK-1715021939474)]
[外链图片转存中…(img-v8y8ixse-1715021939475)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 3171
3171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









