







0.Action-Value Function
Q π ( s t , a t ) = E [ U t ∣ S t = s t , A t = a t ] Q ∗ ( s t , a t ) = max π Q π ( s t , a t ) \begin{aligned} Q_\pi(s_t,a_t)&=E[U_t|S_t=s_t,A_t=a_t] \\Q^*(s_t,a_t)&=\max_\pi Q_\pi(s_t,a_t) \end{aligned} Qπ(st,at)Q∗(st,at)=E[Ut∣St=st,At=at]=πmaxQπ(st,at)
1.Deep Q-Network (DQN)
-
目标:最大化回报
策略:在已知 Q ∗ ( s , a ) Q^*(s,a) Q∗(s,a)的情况下,取动作 a ∗ = arg max a Q ∗ ( s , a ) a^*=\arg\max_aQ^*(s,a) a∗=argmaxaQ∗(s,a),即评价价值最大的动作
问题: Q ∗ ( s , a ) Q^*(s,a) Q∗(s,a)是未知的
解决方法:DQN,通过神经网络(neural network) Q ( s , a ; w ) Q(s,a;w) Q(s,a;w)对 Q ∗ ( s , a ) Q^*(s,a) Q∗(s,a)进行近似,
-
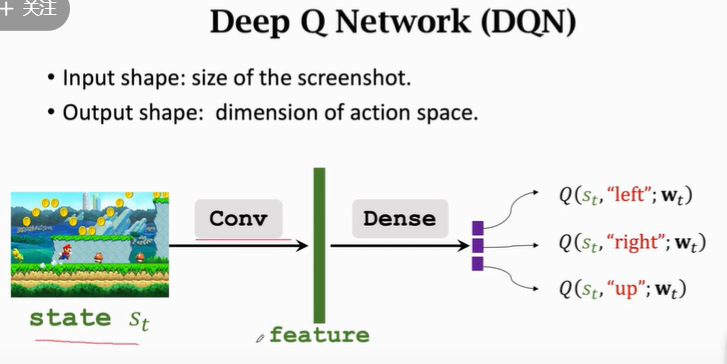
网络输入:状态 s s s
网络输出:对不同动作的打分
w w w:网络参数
2.Apply DQN to Play Game
3.Temporal Difference (TD) Learning
-
算法理解:
预测值(predict)为 q q q,实际值(target)为 y y y
Loss: L = 1 2 ( q − y ) 2 L=\frac{1}{2}(q-y)^2 L=21(q−y)2
Gradient: ∂ L ∂ w = ∂ L ∂ q ⋅ ∂ q ∂ w = ( q − y ) ⋅ ∂ Q ( w ) ∂ w \frac{\partial L}{\partial w}=\frac{\partial L}{\partial q}·\frac{\partial q}{\partial w}=(q-y)·\frac{\partial Q(w)}{\partial w} ∂w∂L=∂q∂L⋅∂w∂q=(q−y)⋅∂w∂Q(w)
Gradient descent: w t + 1 = w t − α ⋅ ∂ L ∂ w ∣ w = w t w_{t+1}=w_t-\alpha·\frac{\partial L}{\partial w}|_{w=w_t} wt+1=wt−α⋅∂w∂L∣w=wt
以上算法需完成整个过程才能完成更新,而如果未完成整个过程,则根据已完成部分和预测值,得到一个新的预测值TD target为 y y y,将 δ = q − y \delta=q-y δ=q−y定义为TD error,则为TD算法。
-
TD Learning for DQN
将TD算法应用于DQN,在未完成整个序列的情况下进行学习。
在TD算法中,有如下的等式:
T A → C ≈ T A → B + T B → C T_{A\rightarrow C}\approx T_{A\rightarrow B}+T_{B\rightarrow C} TA→C≈TA→B+TB→C
其中 T A → C T_{A\rightarrow C} TA→C为需要估计的值, T A → B T_{A\rightarrow B} TA→B为已完成部分的实际值, T B → C T_{B\rightarrow C} TB→C为未完成部分的预测值。而在DQN中有类似的等式:
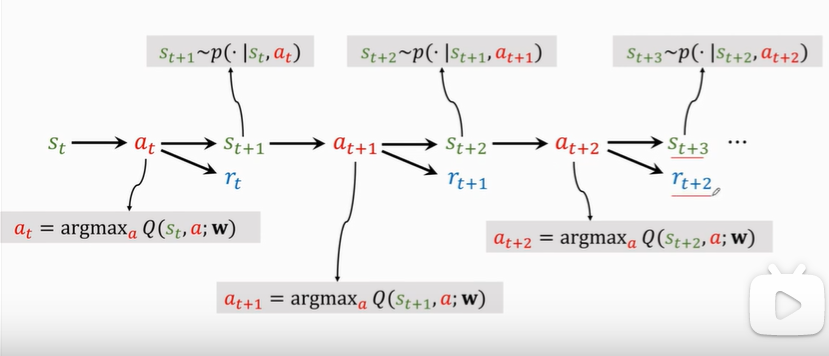
Q ( s t , a t ; w ) = r t + γ Q ( s t + 1 , a t + 1 ; w ) Q(s_t,a_t;w)=r_t+\gamma Q(s_{t+1},a_{t+1};w) Q(st,at;w)=rt+γQ(st+1,at+1;w)
在状态 s t s_t st下,采取动作 a t a_t at,得到状态 a t + 1 a_{t+1} at+1和reward r t r_t rt,再根据 Q Q Q函数的当前预测,计算 Q ( s t + 1 , a t + 1 ; w ) Q(s_{t+1},a_{t+1};w) Q(st+1,at+1;w),可以得到当前状态的TD target。其中, a t + 1 a_{t+1} at+1是根据当前 Q Q Q函数取的最优动作,即
- TD target
y t = r t + γ ⋅ Q ( s t + 1 , a t + 1 ; w t ) = r t + γ ⋅ max a Q ( s t + 1 , a ; w t ) \begin{aligned} y_t&=r_t+\gamma·Q(s_{t+1},a_{t+1};w_t) \\&=r_t+\gamma·\max_a Q(s_{t+1},a;w_t) \end{aligned} yt=rt+γ⋅Q(st+1,at+1;wt)=rt+γ⋅amaxQ(st+1,a;wt)
-
Loss: L t = 1 2 [ Q ( s t , a t ; w ) − y t ] 2 L_t=\frac{1}{2}[Q(s_t,a_t;w)-y_t]^2 Lt=21[Q(st,at;w)−yt]2
-
Gradient descent: w t + 1 = w t − α ⋅ L t w ∣ w = w t w_{t+1}=w_t-\alpha·\frac{L_t}{w}|_{w=w_t} wt+1=wt−α⋅wLt∣w=wt
-
Gradient descent: w t + 1 = w t − α ⋅ L t w ∣ w = w t w_{t+1}=w_t-\alpha·\frac{L_t}{w}|_{w=w_t} wt+1=wt−α⋅wLt∣w=wt
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









