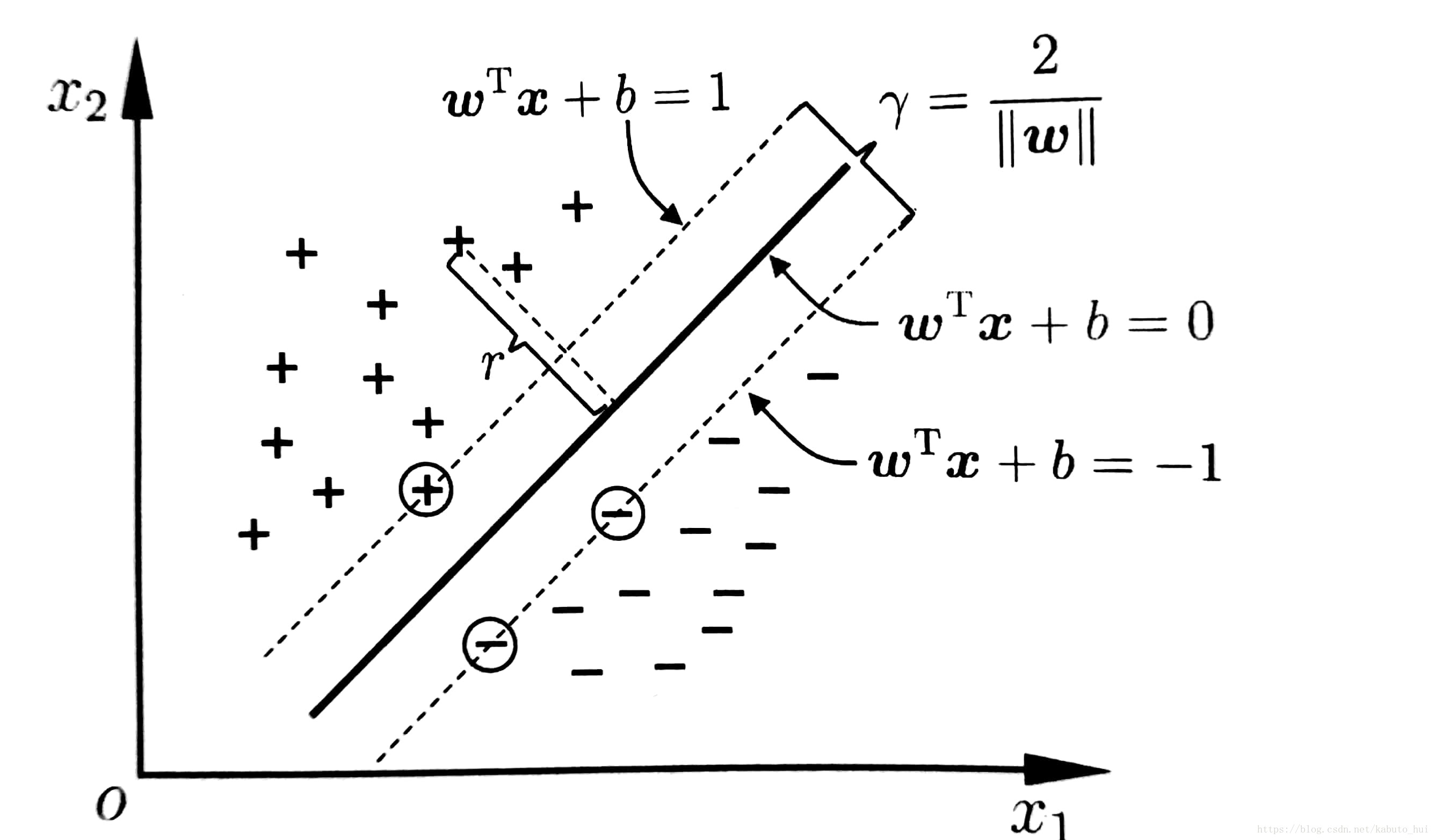
maxw,b2||w||s.t.yi(wTxi+b)≥1,i=1,2,3...,m
max
w
,
b
2
|
|
w
|
|
s
.
t
.
y
i
(
w
T
x
i
+
b
)
≥
1
,
i
=
1
,
2
,
3...
,
m
于是可以转化为求其等价问题:
minw,b12||w||2s.t.yi(wTxi+b)≥1,i=1,2,3...,m
min
w
,
b
1
2
|
|
w
|
|
2
s
.
t
.
y
i
(
w
T
x
i
+
b
)
≥
1
,
i
=
1
,
2
,
3...
,
m
我们使用拉格朗日乘子法,给每一个约束条件都添加一个拉格朗日乘子
αi≥0
α
i
≥
0
,所以其拉格朗日函数可以写为:
L(w,b,α)=12||w||2+∑i=1mαi(1−yi(wTx+b))
L
(
w
,
b
,
α
)
=
1
2
|
|
w
|
|
2
+
∑
i
=
1
m
α
i
(
1
−
y
i
(
w
T
x
+
b
)
)
分别让L对w,b求偏导数并使其等于0可以得到:
w=∑i=1mαiyixi0=∑i=1mαiyi
w
=
∑
i
=
1
m
α
i
y
i
x
i
0
=
∑
i
=
1
m
α
i
y
i
把上述两式带回拉格朗日函数中可以得到最终的一个对偶问题:
minα12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)−∑i=1Nαis.t.∑i=1Nαiyi=0αi≥0,i=1,2,…,N
min
α
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
(
x
i
⋅
x
j
)
−
∑
i
=
1
N
α
i
s
.
t
.
∑
i
=
1
N
α
i
y
i
=
0
α
i
≥
0
,
i
=
1
,
2
,
…
,
N
最后求得最优解
α∗
α
∗
。
再根据α∗
α
∗
可以求出w与b:
w∗=∑i=1mα∗iyixib∗=yj−wTx=yj−∑i=1mα∗iyi(xi⋅xj)
w
∗
=
∑
i
=
1
m
α
i
∗
y
i
x
i
b
∗
=
y
j
−
w
T
x
=
y
j
−
∑
i
=
1
m
α
i
∗
y
i
(
x
i
⋅
x
j
)
特别说明:
在计算α
α
时,我们可以写出其KKT条件如下:
⎧⎩⎨αi≥0yif(xi)−1≥0αi(yif(xi)−1)=0
{
α
i
≥
0
y
i
f
(
x
i
)
−
1
≥
0
α
i
(
y
i
f
(
x
i
)
−
1
)
=
0
当
(xi,yi)
(
x
i
,
y
i
)
不是支持向量的时候,一定有
yif(xi)−1≥0
y
i
f
(
x
i
)
−
1
≥
0
成立,那么根据第三个条件可以得出
αi=0
α
i
=
0
。所以这也解释了
支持向量机的最终模型仅与支持向量有关。
2.线性不可分支持向量机
若o若数据线性不可分,则增加松弛因子ξi≥0
ξ
i
≥
0
,使函数间隔加上松弛变量大于等于1。这样,约束条件变成:
yi(w⋅xi+b)≥1−ξi
y
i
(
w
⋅
x
i
+
b
)
≥
1
−
ξ
i
目标函数则变为:
minw,b12∥w∥2+C∑i=1mξi
min
w
,
b
1
2
‖
w
‖
2
+
C
∑
i
=
1
m
ξ
i
所以原来的优化问题就变为:
minw,b,ξ12∥w∥2+C∑i=1mξis.t.yi(w⋅xi+b)≥1−ξi,i=1,2,⋯mξi≥0,i=1,2,⋯m
min
w
,
b
,
ξ
1
2
‖
w
‖
2
+
C
∑
i
=
1
m
ξ
i
s
.
t
.
y
i
(
w
⋅
x
i
+
b
)
≥
1
−
ξ
i
,
i
=
1
,
2
,
⋯
m
ξ
i
≥
0
,
i
=
1
,
2
,
⋯
m
此时,拉格朗日函数为:
L(w,b,ξ,α,μ)≡12∥w∥2+C∑i=1mξi−∑i=1mαi(yi(w⋅xi+b)−1+ξi)−∑i=1mμiξi
L
(
w
,
b
,
ξ
,
α
,
μ
)
≡
1
2
‖
w
‖
2
+
C
∑
i
=
1
m
ξ
i
−
∑
i
=
1
m
α
i
(
y
i
(
w
⋅
x
i
+
b
)
−
1
+
ξ
i
)
−
∑
i
=
1
m
μ
i
ξ
i
对w,b,ξ求偏导:
∂L∂w=0⇒w=∑i=1mαiyixi∂L∂b=0⇒∑i=0mαiyi=0C−αi−μi=0
∂
L
∂
w
=
0
⇒
w
=
∑
i
=
1
m
α
i
y
i
x
i
∂
L
∂
b
=
0
⇒
∑
i
=
0
m
α
i
y
i
=
0
C
−
α
i
−
μ
i
=
0
带入L中得到:
minw,b,ξL(w,b,ξ,α,μ)=−12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)+∑i=1Nαi
min
w
,
b
,
ξ
L
(
w
,
b
,
ξ
,
α
,
μ
)
=
−
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
(
x
i
⋅
x
j
)
+
∑
i
=
1
N
α
i
对上式关于
α
α
求极大,并求其对偶问题:
minα12∑i=1m∑j=1mαiαjyiyj(xi⋅xj)−∑i=1mαis.t.∑i=1mαiyi=00≤αi≤C,i=1,2,…,m
min
α
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
(
x
i
⋅
x
j
)
−
∑
i
=
1
m
α
i
s
.
t
.
∑
i
=
1
m
α
i
y
i
=
0
0
≤
α
i
≤
C
,
i
=
1
,
2
,
…
,
m
求得最优解α*,计算w与b:
w∗=∑i=1mα∗iyixib∗=yj−∑i=1mα∗iyi(xi⋅xj)
w
∗
=
∑
i
=
1
m
α
i
∗
y
i
x
i
b
∗
=
y
j
−
∑
i
=
1
m
α
i
∗
y
i
(
x
i
⋅
x
j
)
1995年,苏联的弗拉基米尔·瓦普尼克(Vladimir N. Vapnik)在Machine Learning上发表了最初的SVM文章。传统的统计模式识别方法只有在样本趋向无穷大时,其性能才有理论的保证。统计学习理论(STL)研究有限样本情况下的机器学习问题。SVM的理论基础就是统计学习理论。 SVM以训练误差作为优化问题的约束条件,以置信范围值最小化作为优化目标,即SVM是一种基于结...
























 2057
2057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









