







SVM是最经典的分类算法之一,笔者觉得难度却是机器学习算法中最难的,对于没有数学基础的同学来说更是一头雾水。笔者作为一个初入机器学习的小白,希望能从最简单的视角分享我的学习过程,从零开始一点一滴学习SVM算法。
一、首先,什么是svm,它能够做什么?
它是一种二分类模型,解决是非的问题。
以对图像猫狗分类为例:
- 下载CIFAR数据集,数据集中有10类,我只取两类:猫、狗
- 获取猫狗混合的训练样本集,D={ (x1,y1),(x2,y2),⋯,(xn,yn) }, yiε { −1,+1 }
- 训练样本获取分割超平面
- 正确分开不同类别样本,保存模型
- 输入测试数据,进行预测
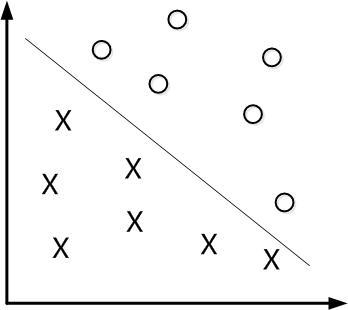
如果是应用,只想把这个算法当作工具那么以上就足够了,可以应用tensorflow、sklearn以及最近很流行,也是令我非常好奇的框架pytorch,输入相关的参数就可以进行训练
如何是对svm有强烈的好奇心,那就继续阅读笔者这个小白学习svm的过程
二、深入研究svm原理
svm最基本的想法就是基于训练集D在样本空间中找到一个划分超平面,将不同的类别样本分开,在样本空间中可以通过线性方程来描述:
wTx+b=0
样本空间中的任意点到超平面的距离为:由点到面的距离公式可知
r=|wTx+b|||w||
补充一下 ||w|| 的含义,对于初学者来说这种公式确实会很头疼,这个专业一点被称作 L2 范式,用来衡量一个向量的长度,
||w||2=∑i=1nx2i−−−−−√
我们需要找到划分超平面对训练样本“正中间”的划分超平面,这样的超平面对样本的局部扰动的容忍性最好,也就是说我们不满足仅仅是划分开两个样本数据,我们要尽可能的使得两个分的最开。
如下图所示:
我们令 :
wTxi+b⩾+1,yi=+1
wTxi+b⩽−1,yi=−1
也就是说样本数据{ xi,yi },输入到
f(x)=wTx+b
如果 f(x)>1,那么我们把标签设置为+1 或者,反之 f(x)<−1标签设置为−1
而且在 wTxi+b=±1面上的点,我们称作为“支持向量”

那么问题来了,为什么是
wTxi+b=±1
,关键不明白那个1,设置成其他的值不行吗?答案是可以,并且可以设置成任意值,但是因为设置成1简单,容易计算。
问题又来了,为什么可以设置成任意值,这样的话超平面还能够唯一吗?答案是可以,我们的超平面为:
wTx+b=0
也就是说任意的放缩w与b都不会影响超平面,因为恒为0啊
假设两条边界线为 wTxi+b=±r ,我们两边同时除以r,得到 wTxir+br=±1 。
样本点到面的距离公式:
距离i=|wTrxi+br|||wr||
令 wTr=w;br=b ,带入上式,这个世界回归平静了,一切都这么安详,一切好像都没有发生过。
“支持向量”到超平面的的距离即分界线到超平面的距离,根据两条线距离的公式可得:
γ=1||w||
它被称作为 “间隔” ,而我们的目标是,找到最大的间隔并且满足
wTxi+b⩾+1,yi=+1
wTxi+b⩽−1,yi=−1
这两条约束条件即:
maxw,b1||w||
s.t.yi(wTxi+b),i=1,2,3…,m.
显然,最大化 1||w|| ,也就是最小化 ||w||2 ,则目标函数可以重写为:
minw,b||w||2
s.t.yi(wTxi+b)⩾1,i=1,2,3…,m.
接下来就是求解带有约束条件的目标函数,那么就要用到大名鼎鼎的拉格朗日乘子算法与KKT条件,到这不要担心,看起来很唬人(其实确实挺难的),我们简单的理解,如果目标函数的约束条件带有等式那就使用拉格朗日乘子算法,这里我引用斯坦福大学机器学习教程吴恩达老师的讲义的公式说明:如果目标函数是仅仅带有等式约束

那么拉格朗日函数的形式如下:

只要对w求偏导等于0,得到 β 的值,带入目标函数即可得到不带有约束条件的目标函数
如果带有不等式约束:

目标函数如下:

由此我们对上面的目标函数的约束进行变形
minw,b||w||2
s.t.yi(1−(wTxi+b))⩽0,i=1,2,3…,m.
应用拉格朗日乘子算法可得:
L(w,b,a)=12||w||2+∑i=1mαi(1−yi(wTxi+b))
对w与b求偏导为零可得
⅁L(w,b,a)⅁w=w−∑i=1mαiyixi=0
⅁L(w,b,a)⅁b=∑i=1mαiyi=0
回代入公式可得目标函数变为:


最后一项在上面的对b求偏导可知结果为0,得到的目标函数为:
maxα∑i=1mαi−12∑i=1m∑j=1mαiαjyiyjxTixj
s.t.∑i=1mαiyi=0
αi⩾0,i=1,2,…,m
哎,我们不是要求极小值吗?这里怎么会是极大值,对你没有看错,是极大值,因为经过拉格朗日子乘子算法得到的函数会形成一个对偶问题,啥是对偶问题?简单的理解就是求大的问题变成求小的问题,求小的问题变成大求大的问题。如果非想死磕对偶问题,斯坦福大学机器学习公开课会给你答案,因为笔者的数学基础也不是很好,对于对偶理论也没有理解的很透彻,不能”鼻子里插葱”。
总结一下我们的约束条件:
αi⩾0
1−yi(wTxi+b)⩽0
αi(1−yi(wTxi+b))=0
不要晕,感叹这些约束条件哪来的?这些约束条件都是我们上面求解过程中得到的,这些约束条件也叫KKT条件,到底什么是kkt条件这么神秘,其实就是一系列定义好的约束,要想获得极值就得满足上述条件,通过联立方程组,得到 w∗,β∗,α∗ ,回带入方程组可得不带有约束的目标函数。到此我们线性分类的问题已经解决,剩下的问题是如何解决线性不可分的情况,以及如何求解目标函数,欲知后事如何请关注后面的文章核函数与SMO算法
参考:
支持向量机SVM(二)
解密SVM系列(一):关于拉格朗日乘子法和KKT条件
支持向量机通俗导论(理解SVM的三层境界)
斯坦福大学公开课 :机器学习课程
机器学习 周志华















 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









