






 本文介绍了Kafka中的数据压缩,包括消息的结构、0.11版本的消息格式变更,以及压缩在生产者、Broker和消费者端的工作原理。Kafka支持GZIP、Snappy、LZ4和Zstandard等压缩算法,选择时需要考虑压缩比和吞吐量。
本文介绍了Kafka中的数据压缩,包括消息的结构、0.11版本的消息格式变更,以及压缩在生产者、Broker和消费者端的工作原理。Kafka支持GZIP、Snappy、LZ4和Zstandard等压缩算法,选择时需要考虑压缩比和吞吐量。
背景
数据压缩,是一种用时间换空间的思想,就是说通过cpu使用率的升高,来降低磁盘空间和网络IO,比如在hadoop中通过DEFLATE、LZ4、Snappy,都是用来做数据压缩的降低数大小,使hadoop整体集群存储能力能耗。在kafka中,数据压缩也是用来做相同事情的。
数据的压缩方式
Kafka 的消息分为两个层级:消息集合以及消息。一个消息集合中包含若干条日志项,而日志项才是真正封装消息的地方。Kafka 底层的消息日志由一系列消息集合日志项组成。Kafka 通常不会直接操作具体的一条条消息,它总是在消息集合这个层面上进行写入操作。
在Kafka 0.11.0.0版本的时候,一个重要的升级就是kafka消息格式变更,那么消息变更的目的是什么?0.11版本主要是针对的一些弊端做了修正,其中比较关键的是把消息的公共部分抽取出来放到外层消息集合里面,这样就不用每条消息都保存这些信息了。
原来在 0.11之前的 版本中,每条消息都需要执行 CRC 校验,但有些情况下消息的 CRC 值是会发生变化的。比如在 Broker 端可能会对消息时间戳字段进行更新,那么重新计算之后的 CRC 值也会相应更新;再比如 Broker 端在执行消息格式转换时(主要是为了兼容老版本客户端程序),也会带来 CRC 值的变化。鉴于这些情况,再对每条消息都执行 CRC 校验就有点没必要了,不仅浪费空间还耽误 CPU 时间,因此在 0.11 版本以后,消息的 CRC 校验工作就被移到了消息集合这一层。
压缩
在 Kafka 中,压缩是发生在生产者端和 Broker 端的。
生产者程序中配置 compression.type 参数即表示启用指定类型的压缩算法。
Properties p = new Properties();
.....
// 开启 GZIP 压缩
p.put("compression.type", "gzip");
....
Producer<String, String> producer = new KafkaProducer<>(p);这样 Producer 启动后生产的每个消息都是 GZIP 压缩过的,从而降低了Producer到Broker的网络传输,从而也降低了Broker的数据存储压力。
Broker的配置中也是支持compression.type 的,正常情况下 Broker 从 Producer 端接收到消息后不会对其进行任何修改,但是Broker端如果指定了和Producer不同的压缩算法也会有其它异常的表现。
解压缩
消息解压是发生在消费端的。Consumer 程序请求这部分消息时,Broker 依然原样发送出去,当消息到达 Consumer 端后,由 Consumer 自行解压缩还原成之前的消息。
消息从Producer到Broker在到Consumer会一直携带消息的压缩方式,这样当 Consumer 读取到消息集合时,它自然就知道了这些消息使用的是哪种压缩算法。
有一种特殊情况,0.11对消息进行了升级这样就导致一个kafka集群中如果保存了多个版本的数据,数据在Broker内部会做消息的版本转换,在该过程中如果生产者使用了数据压缩,Broker会对数据进行重新压缩和解压缩来保证兼容性。
各种压缩算法对比
Kafka 支持 3 种压缩算法:GZIP、Snappy 、LZ4、Zstandard。(每个版本之间会有差异)
压缩算法的重要指标:
压缩比,原先占 100 份空间的东西经压缩之后变成了占 20 份空间,那么压缩比就是 5,显然压缩比越高越好。
压缩 / 解压缩吞吐量,比如每秒能压缩或解压缩多少 MB 的数据。同样地,吞吐量也是越高越好。
Facebook Zstandard 官网提供的一份压缩算法 benchmark 比较结果:
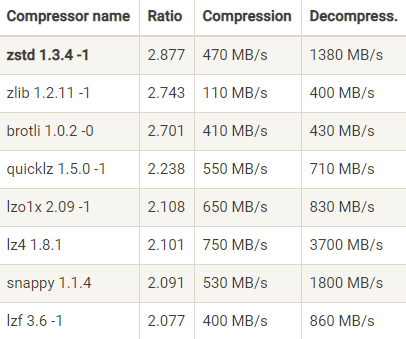
上图中我们可以发现 zstd 算法有着最高的压缩比,但是吞吐量非常一般。 LZ4 ,它在吞吐量方面都有非常明显的优势。
在实际使用中还需要根据业务情况选择合适的压缩算法。比如是否要开启压缩,当集群带宽和存储都非常充足的情况,但是CPU已经接近80%这时候在开启压缩必然是不太适合。
国内最大最权威的 Kafka中文社区 ,在这里你可以结交各大互联网Kafka大佬以及近2000+Kafka爱好者,一起实现知识共享,实时掌控最新行业资讯,免费加入中~


















 874
874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









