




GPT/GPT2/GPT3到GPT3.5/GPT4
1 GPT:基于Transformer Decoder预训练 + 微调/Finetune
GPT由OpenAI在2018年通过此论文“Improving Language Understanding by Generative Pre-Training”提出,使用了一个大型的未标记文本语料库来进行生成式预训练(该语料库包含40GB的文本数据,比如互联网上抓取的网页、维基百科、书籍和其他来源的文本)
GPT是“Generative Pre-Training Transformer”的简称,从名字看其含义是指的生成式的预训练,它和BERT都是(自监督)预训练-(有监督)微调模式的典型代表
- 第一阶段,在未标记数据上使用语言建模目标来学习神经网络模型的初始参数
- 第二阶段,针对目标任务使用相应的标记数据对这些参数进行微调
之所以叫微调是因为在这个阶段用的数据量远远小于第一阶段,并且基本没有更改模型架构和引入过多新的参数
1.1 GPT = Multi-Head Attention层 + Feed forward层 + 求和与归一化的前置LN层 + 残差
由于Decoder具备文本生成能力,故作为侧重生成式任务的GPT选择了Transformer Decoder部分作为核心架构。
与原始的Transformer Decoder相比,GPT所用的结构删除了Encoder-Decoder Attention,只保留了多头注意力层Multi-Head Attention层和前馈神经网络Feed forward层(This model applies a multi-headed self-attention operation over theinput context tokens followed by position-wise feedforward layers to produce an output distributionover target tokens),最后再加上求和与归一化的前置LN层 + 残差,且在参数上有以下变化
- 层数从原始Transformer的6层增加到12层,相当于12层的Transformer Decoder
- 输入向量的维度从原始Transformer的512维扩大到768维,且将Attention的头数从8增加到12,从而每个头的维度依然是768/12 = 64维
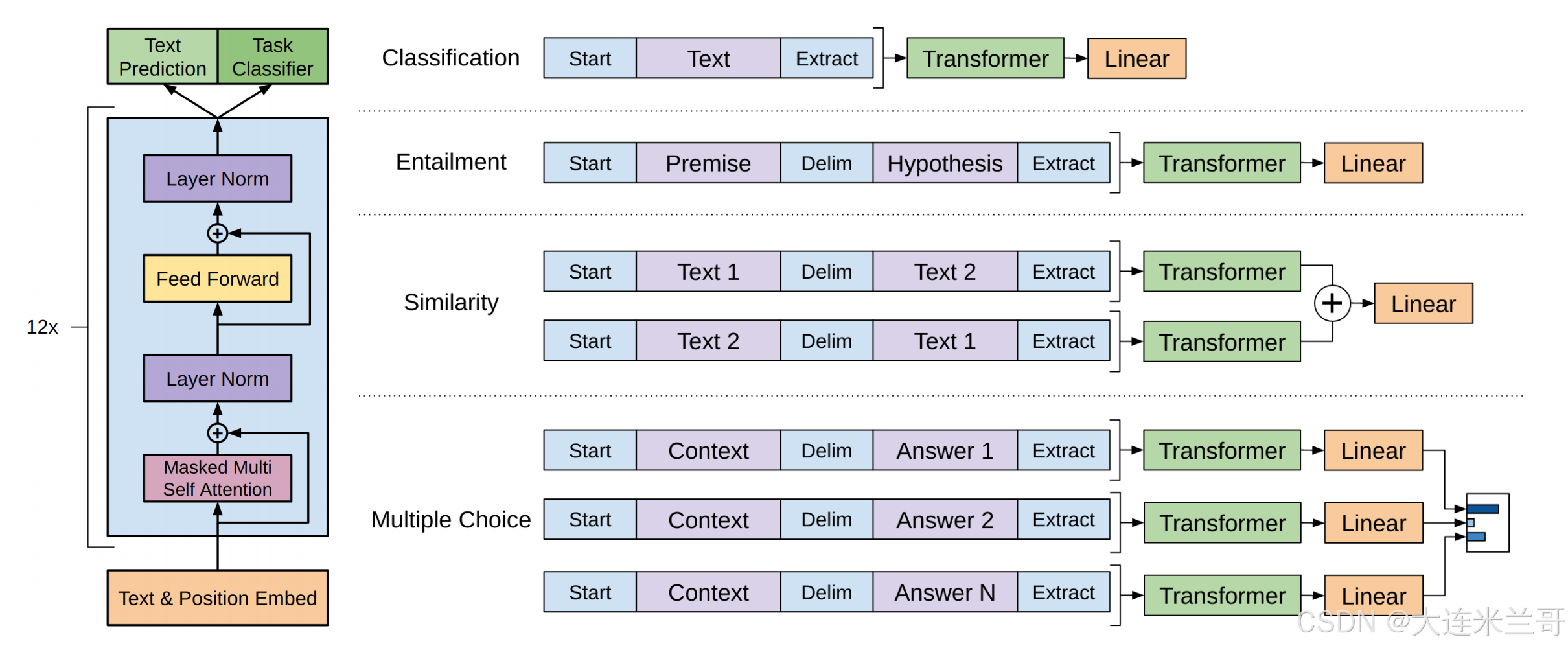
通过这样的结构,GPT便可以利用无标注的自然语言数据进行训练:根据给定的前 i − 1 i−1 i−1个token,预测第 i i i个token,训练过程中使用的是基于最大似然估计的损失函数,即让模型预测的概率分布尽可能接近实际下一个单词的分布.
1.2 Self-Attention与Masked Self-Attention
所谓自注意力,即指当我们需要用到自注意力编码单词 X 1 , X 2 , X 3 , X 4 X_1,X_2,X_3,X_4 X1,X2,X3,X4的时候,会按下面几个步骤依次处理
- 为每个单词路径创建Query、Key、Value,具体做法就是每个单词的表示向量和对应的权重矩阵
(
W
Q
,
W
K
,
W
V
)
(W^Q,W^K,W^V)
(WQ,WK,WV)做矩阵乘法

- 对于每个输入token,使用其Query向量对其他所有的token的Key向量进行评分,获得注意力分数,比如通过
X
1
X_1
X1的
q
1
q_1
q1向量,分别与
X
1
,
X
2
,
X
3
,
X
4
X_1,X_2,X_3,X_4
X1,X2,X3,X4的向量分别做点乘,最终得到
X
1
X_1
X1在各个单词
X
1
,
X
2
,
X
3
,
X
4
X_1,X_2,X_3,X_4
X1,X2,X3,X4上的注意力分数:20% 10% 50% 20%

- 将Value向量乘以上一步得到的注意力分数(相当于对当下单词而言,不同单词重要性的权重),之后加起来,从而获得所有token的加权和

之后对每个token都进行上述同样的三步操作,最终会得到每个token新的表示向量,新向量中包含该token的上下文信息,之后再将这些数据传给Transformer组件的下一个子层:前馈神经网络

至于所谓Masked Self-Attention就是在处理当前词的时候看不到后面的词。举个例子,处理“it”的时候,注意力机制看不到“it”后面的词(通过将“it”后面的词的权重设置为一个非常大的负数,进一步softmax之后变为0,从而屏蔽掉),但会关注到“it”前面词中的“a robot”,继而注意力会计算三个词“it”、“a”、“robot”的向量及其attention分数的加权和

2 GPT2承1启3:基于prompt尝试舍弃微调 直接Zero-shot Learning
GPT2相比GPT1的变动主要体现在两方面,一方面是模型结构上,一方面是推理模式上
在模型结构上
- LN层被放置在self-attention层和feed forward层之前,可称为pre-norm(毕竟GPT1和原始transformer是先self-attention再LN,或先feed forward再LN,可称为post-norm),并在最后一层transformer Block后新增LN层,值得一提的是,自GPT2起,之后的大部分模型基本都用的pre-norm(当然,也有用post-norm的改进版post deepNorm的,比如GLM)

- 修改初始化的残差层权重,缩放为原来的 1 N \frac{1}{\sqrt{N}} N1,其中 N N N是残差层的数量.
- transformer block的层数从12层扩大到48层(相当于transformer 6层 →GPT1 12层 → GPT2 48层)
- 特征向量维度从GPT1的768维扩大到1600维(相当于transformer 512维 →GPT1 768维 →GPT2 1600维)
在推理模式上,虽然GPT1的预训练加微调的范式仅需要少量的微调即可,但能不能有一种模型完全不需要对下游任务进行适配就可以表现优异?GPT2便是在往这个方向努力:不微调但给模型一定的参考样例以帮助模型推断如何根据任务输入生成相应的任务输出
最终,针对小样本/零样本的N-shot Learning应运而生,分为如下三种:
- Zero-shot Learning (零样本学习),是指在没有任何样本/示例情况下,让预训练语言模型完成特定任务
相当于不再使用二阶段训练模式(预训练+微调),而是彻底放弃了微调阶段,仅通过大规模多领域的数据预训练,让模型在Zero-shot Learning的设置下自己学会解决多任务的问题,而且效果还不错(虽然GPT2通过Zero-shot Learning在有些任务的表现上尚且还不如SOTA模型,但基本超越了一些简单模型,说明潜力巨大),你说神不神奇? - One shot Learning (单样本学习),顾名思义,是指在只有一个样本/示例的情况下,预训练语言模型完成特定任务
- Few-shot Learning (少样本或小样本学习),类似的,是指在只有少量样本/示例的情况下,预训练语言模型完成特定任务.
此外,只需将自然语言的任务示例和提示信息作为上下文输入给GPT-2,它就可以在小样本的情况下执行任何NLP任务,包括所谓的完形填空任务,比如
假如我要判断“我喜欢这个电影" 这句话的情感(“正面" 或者 “负面”),原有的任务形式是把他看成一个分类问题
输入:我喜欢这个电影
输出:“正面" 或者 “负面”
而如果用GPT2去解决的话,任务可以变成“完形填空",
输入:我喜欢这个电影,整体上来看,这是一个 __ 的电影
输出:“有趣的" 或者 “无聊的”
加的这句提示“整体上来看,这是一个 __ 的电影” 对于让模型输出人类期望的输出有很大的帮助。
这个所谓的提示用NLP的术语表达就是prompt,即给预训练语言模型的一个线索/提示,帮助它可以更好的理解人类的问题
例如有人忘记了某篇古诗,我们给予特定的提示,他就可以想起来,例如当有人说:
白日依山尽
大家自然而然地会想起来下一句诗:黄河入海流
3 GPT3:In-context learning正式开启prompt新范式(小样本学习)
3.1 GPT3在0样本、单样本、小样本下的突出能力
GPT3简单来说,就是参数规模大(有钱)、训练数据规模大(多金)、效果出奇好,具体而言
- 它最大规模版本的参数规模达到了1750亿,层数达到了96层,输入维度则达到了12888维(设置了96个注意力头,故每个头的维度为12888/96 = 128维,类比原始transformer中:输入维度为512维,设置8个头,每个头的维度为512/8 = 64维)

- 并且使用45TB数据进行训练(当然,GPT3论文中说道:constituting 45TB of compressed plaintext before filtering and 570GB after filtering, roughly equivalent to 400 billion byte-pair-encoded tokens),至于数据组成上,则包括Common Crawl、WebText2、Books1/2、Wikipedia的数据

为方便大家更好理解,举个例子说明下,比如对于410B大小的CC数据集(在一开始的整个数据集大小499B中占比82.1%),其采样比例是60%
但实际训练时 整个数据集最终变成了是300B,然后CC数据集采样了300B的60% = 180,而180的数据在CC 410的数据中 相当于训了180/410 = 0.44个epoch
- 其预训练任务就是“句子接龙”,给定前文持续预测下一个字,而且更为关键的是,当模型参数规模和训练数据的规模都很大的时候,面对小样本时,其性能表现一度超越SOTA模型
一方面,单样本也好 小样本也好,更多只是作为例子去提示模型,模型不利用样本做训练,即不做模型参数的任何更新
二方面,人们一度惊讶于其在0样本下如此强大的学习能力,使得很多人去研究背后的In Context Learning
毕竟,我们知道普通模型微调的原理:拿一些例子当作微调阶段的训练数据,利用反向传播去修正LLM的模型参数,而修正模型参数这个动作,确实体现了LLM从这些例子学习的过程
但是,In Context Learning只是拿出例子让LLM看了一眼,并没有根据例子,用反向传播去修正LLM模型参数的动作,就要求它去预测新例子
此举意味着什么呢?
- 既然没有修正模型参数,这意味着LLM并未经历一个修正过程,相当于所有的举一反三和推理/推断的能力在上一阶段预训练中便已具备(或许此举也导致参数规模越来越大),才使得模型在面对下游任务时 不用微调、不做梯度更新或参数更新,且换个角度讲,如此巨大规模的模型想微调参数其门槛也太高了
- 预训练中 好的预训练数据非常重要,就好比让模型在0样本下翻译英语到法语,那预训练数据中 必然有大量英语、法语的文本数据
- 抓什么样的数据 多大规模 怎么喂给模型等等一系列工程细节,这块是导致很多模型效果有差距的重要原因之一
3.2 In Context Learning(ICL)背后的玄机:隐式微调?
零样本下 模型没法通过样本去学习/修正,但即便是少样本下,也有工作试图证明In Context Learning并没有从样本中学习,比如“Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?”,它发现了:
- 在提供给LLM的样本示例 < x i , y i > <x_i,y_i> <xi,yi>中, y i y_i yi是否是 x i x_i xi对应的正确答案其实并不重要,如果我们把正确答案替换成随机的另外一个答案 ,这并不影响In Context Learning的效果
比如下图中,无论是分类任务(图中上部分),还是多项选择任务(图中下部分),随机标注设置下(红)模型表现均和正确标注(黄)表现相当,且明显超过没有in-context样本的zero-shot设置(蓝)

这起码说明了一点:In Context Learning并没有提供给LLM那个从
x
x
x映射到
y
y
y 的映射函数信息:
y
=
f
(
x
)
y=f(x)
y=f(x)
否则的话你乱换正确标签,肯定会扰乱这个
y
=
f
(
x
)
y=f(x)
y=f(x)映射函数,也就是说,In Context Learning并未学习这个输入空间到输出空间的映射过程.
2. 真正对In Context Learning影响比较大的是:
x
x
x和
y
y
y的分布,也就是输入文本
x
x
x的分布和候选答案
y
y
y有哪些,如果你改变这两个分布,比如把
y
y
y替换成候选答案之外的内容,则In Context Learning效果急剧下降
总之,这个工作证明了In Context Learning并未学习映射函数,但是输入和输出的分布很重要,这两个不能乱改
然而,有些工作认为LLM还是从给出的示例学习了这个映射函数 y = f ( x ) y=f(x) y=f(x),不过是种隐式地学习
- 比如“What learning algorithm is in-context learning? Investigations with linear models”认为Transformer能够隐式地从示例中学习 到 的映射过程,它的激活函数中包含了一些简单映射函数,而LLM通过示例能够激发对应的那一个
- 再比如“Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers(此为该论文的解读之一)”这篇文章则将ICL看作是一种隐式的Fine-tuning
文章中提出,关键在于 LLM 中的注意力层(attention layers),在推理过程实现了一个隐式的参数优化过程,这和fine-tuning的时候通过梯度下降法显式优化参数的过程是类似的,更多可以看下原论文.
4 Prompt技术的升级与创新:指令微调技术(IFT)与思维链技术(CoT)
4.1 Google提出FLAN大模型:基于指令微调技术Instruction Fine-Tuning (IFT)
OpenAI的GPT3虽然不再微调模型(pre-training + prompt),但Google依然坚持预训练 + 微调的模式
2021年9月,谷歌的研究者们在此篇论文中《Finetuned Language Models Are Zero-Shot Learners》提出了基于Instruction Fine-Tuning(指令微调,简称IFT)的FLAN大模型(参数规模为137B),极大地提升了大语言模型的理解能力与多任务能力,且其在评估的25个数据集中有20个数据集的零样本学习能力超过175B版本的GPT3(毕竟指令微调的目标之一即是致力于improving zero-shot generalization to tasks that where not seen in training),最终达到的效果就是:遵循人类指令,举一反三地完成任务
有两点值得注意的是:
- 根据论文中的这句话:“FLAN is the instruction-tuned version of LaMDA-PT”,可知指令微调的是LaMDA,而LaMDA是Google在21年5月对外宣布内部正在研发的对话模型(不过,LaMDA的论文直到22年1月才发布)
- 论文中也解释了取名为FLAN的缘由
We take a pretrained language model of 137B parameters and perform instruction tuning—finetuning the model on a mixture of more than 60 NLP datasets expressed via natural language instructions.We refer to this resulting model as FLAN, for Finetuned Language Net
至于IFT的数据通常是由人工手写指令和语言模型引导的指令实例的集合,这些指令数据由三个主要组成部分组成:指令、输入和输出,对于给定的指令,可以有多个输入和输出实例

相比于GPT-3,且区别在于Finetune,FLAN的核心思想是,当面对给定的任务A时,首先将模型在大量的其他不同类型的任务比如B、C、D…上进行微调,微调的方式是将任务的指令与数据进行拼接(可以理解为一种Prompt),随后给出任务A的指令,直接进行推断,如下图所示

例如,我们的最终目标是推理任务
- FLAN首先讲语言模型在其他任务上进行微调,包括给定任务指令的翻译、常识推理、情感分类等
在面对翻译任务时可以给出指令“请把这句话翻译成西班牙语”
在面对常识推理任务时可以给出指令“请预测下面可能发生的情况” - 而当模型根据这些“指令”完成了微调阶段的各种任务后(将指令拼接在微调数据的前面),在面对从未见过的自然语言推理任务的指令比如:“这段话能从假设中推导出来吗?” 时,就能更好地调动出已有的知识回答问题

相当于通过指令微调之后,模型可以更好的做之前预训练时没见过的新任务且降低了对prompt的敏感度(某些场景下不一定非得设计特定prompt才能激发模型更好的回答)
这或许也启发了OpenAI重新注意到了微调这一模式(毕竟如上文所述,原本GPT3在预训练之后已彻底放弃再微调模型),从而在InstructGPT中针对GPT3做Supervised fine-tuning(简称SFT)
4.2 关于PL的进一步总结:到底如何理解prompt learning
自此,总结一下,关于「prompt learning」最简单粗暴的理解,其实就是让模型逐步学会人类的各种自然指令或人话,而不用根据下游任务去微调模型或更改模型的参数,直接根据人类的指令直接干活,这个指令就是prompt,而设计好的prompt很关键 也需要很多技巧,是一个不算特别小的工程,所以叫prompt engineering,再进一步,对于技术侧 这里面还有一些细微的细节.
- GPT3 出来之前(2020年之前),模型基本都是预训练 + 微调,比如GPT1和BERT
- GPT3刚出来的时候,可以只预训练 不微调,让模型直接学习人类指令直接干活 即prompt learning,之所以可以做到如此 是因为GPT3 当时具备了零样本或少样本学习能力
当然,说是说只预训练 不微调,我个人觉得还是微调了的,只是如上文所说的某种隐式微调而已- 2021年,Google发现微调下GPT3后 比OpenAI不微调GPT3在零样本上的学习能力更加强大
从而现在又重新回归:预训练之后 再根据下游任务微调的模式,最后封装给用户,客户去prompt模型所以现在的prompt learning更多针对的是 去提示/prompt:已具备零样本学习能力的且还做了进一步微调的GPT3.5/GPT4
(怎么微调呢,比如很快下文你会看到的SFT和RLHF,当然 也可以不做微调,比如后来Meta发布的类ChatGPT模型LLaMA本身便没咋做微调,虽它刚发布时比不上GPT3.5/4之类的,但其核心意义在于13B通过更多数据训练之后 在很多任务上可以强过175B的GPT3)
再之后,就出来了很多个基于LLaMA微调的各种开源模型(这块可以查看本文开头所列的:类ChatGPT的部署与微调系列文章)
4.3 基于思维链(Chain-of-thought)技术下的prompt
为让大语言模型进一步具备解决数学推理问题的能力,22年1月,谷歌大脑团队的Jason Wei、Xuezhi Wang等人提出了最新的Prompting机制——Chain of Thought(简称CoT),简言之就是给模型推理步骤的prompt,让其学习人类如何一步步思考/推理,从而让模型具备基本的推理能力,最终可以求解一些简单甚至相对复杂的数学推理能力
以下是一个示例(下图左侧为standard prompting,下图右侧为基于Cot的prompt,高亮部分为chain-of-thought),模型在引入基于Cot技术的prompt的引导下,一步一步算出了正确答案,有没有一种眼前一亮的感觉?相当于模型具备了逻辑推理能力

那效果如何呢,作者对比了标准prompting、基于Cot技术的prompting分别在这三个大语言模型LaMDA、GPT、PaLM(除了GPT由OpenAI发布,另外两个均由Google发布)上的测试结果,测试发现:具有540B参数的PaLM模型可以在一个代表小学水平的数学推理问题集GSM8K(GSM8K最初由OpenAI于2021年10月提出)上的准确率达到了60.1%左右

5 GPT3到GPT3.5:从InstructGPT到ChatGPT初版的迭代过程
据OpenAI官网对GPT3.5的介绍,GPT3.5从2021年第四季度开始就混合使用文本和代码进行训练,我们来看下GPT3.5的各个系列模型及其各自的发展演变脉络图.
基于GPT3的发展路线:一条是侧重代码/推理的Codex,一条侧重理解人类的instructGPT
- 第一条线:为了具备代码/推理能力:GPT3 + 代码训练 = Codex
- 第二条线:为了更好理解人类:GPT3 + 指令学习 + RLHF = instructGPT
基于GPT3.5的发展路线:增强代码/推理能力且更懂人类终于迭代出ChatGPT
- 首先,融合代码/推理与理解人类的能力,且基于code-cushman-002迭代出text-davinci-002
- 其次,为了进一步理解人类:text-davinci-002 + RLHF = text-davinci-003/ChatGPT
6 ChatGPT初版与InstructGPT的差别:基于GPT3还是GPT3.5微调
通过OpenAI公布的ChatGPT训练图可知,ChatGPT的训练流程与InstructGPT是一致的,差异只在于
- InstructGPT(有1.3B 6B 175B参数的版本,这个细节你马上会再看到的),是在GPT-3(原始的GPT3有1.3B 2.7B 6.7B 13B 175B等8个参数大小的版本)上做Fine-Tune
- 22年11月份的初版ChatGPT是在GPT-3.5上做Fine-Tune
7 基于GPT4的ChatGPT改进版:新增多模态技术能力
23年3月14日(国内3.15凌晨),OpenAI正式对外发布自从22年8月份便开始训练的GPT4,之前订阅ChatGPT plus版的可以直接体验GPT4.
根据OpenAI官网发布的《GPT-4 Technical Report》可知
- gpt-4 has a context length of 8,192 tokens
- GPT-4经过预训练之后,再通过RLHF的方法微调
- RLHF之外,为了进一步让模型输出安全的回答,过程中还提出了基于规则的奖励模型RBRMs(rule-based reward models),奖励规则由人编写
RBRMs相当于是零样本下GPT-4的决策依据或者分类器
这些分类器在RLHF微调期间为GPT-4策略模型提供了额外的奖励信号,以生成正确回答为目标,从而拒绝生成有害内容,说白了,额外增加RBRMs就是为了让模型的输出更安全(且合理拒答的同时避免误杀。 - 经过测试,GPT4在遵循人类指令上表现的更好(同样指令下,输出更符合人类预期的回答),且在常识性推理、解题等多项任务上的表现均超过GPT3和对应的SOTA
此外,通过GPT4的技术报告第60页可知,其训练方式和基于GPT3的instructGPT或基于GPT3.5的ChatGPT初版的训练方式如出一辙
先收集数据
- 一部分是人工标注问题-答案对:We collect demonstration data (given an input, demonstrating how the model should respond)
- 一部分是基于人类偏好对模型输出的多个答案进行排序的数据:ranking data on outputs from our models (given an input and several outputs, rank the outputs from best to worst) from human trainers
接下来三个步骤(具体下文第三部分详述)
- 通过人工标注的数据(问题-答案对)监督微调GPT4
We use the demonstration data to finetune GPT-4 using supervised learning (SFT) to imitate the behavior in the demonstrations.- 通过对模型多个回答进行人工排序的数据训练一个奖励模型,这个奖励模型相当于是模型输出好坏的裁判
We use the ranking data to train a reward model (RM), which predicts the average labeler’s preference for a given output- 通过最大化奖励函数的目标下,通过PPO算法继续微调GPT4模型
and use this signal as a reward to fine-tune the GPT-4 SFT model using reinforcement learning (specifically, the PPO algorithm)


















 7019
7019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











