







本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习内容,尽在聚客AI学院。
一. 计算机硬件基础
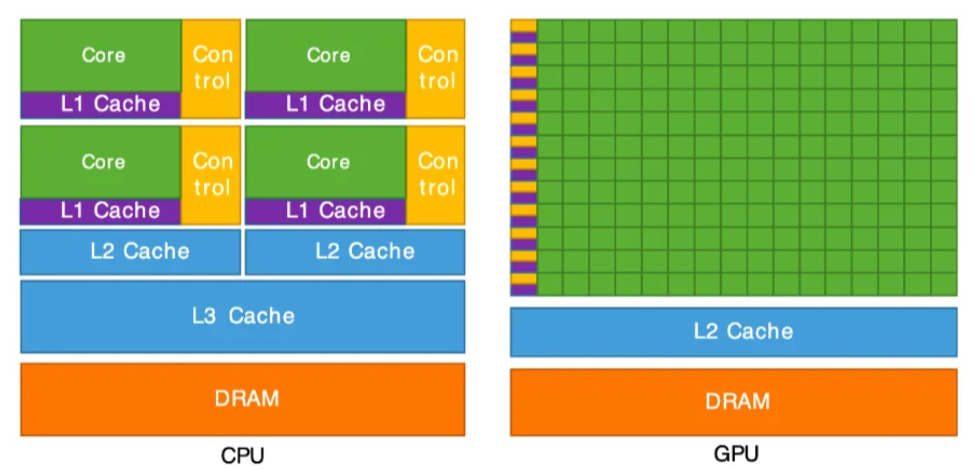
1.1 CPU与GPU的设计哲学
-
CPU(中央处理器):
-
设计目标:强通用性,擅长处理复杂逻辑和串行任务
-
架构特点:少量高性能核心(现代CPU通常4-32核),大缓存(L3缓存可达64MB)
-
典型场景:操作系统调度、数据库事务处理
-
-
GPU(图形处理器):
-
设计目标:高并行计算能力,适合处理简单但大规模并行的任务
-
架构特点:数千个简化核心(NVIDIA A100有6912 CUDA核心),高内存带宽(2TB/s)
-
典型场景:图形渲染、深度学习训练/推理
-
-
二. GPU vs CPU 关键指标对比

三. GPU在大模型推理中的核心优势
3.1 并行计算加速
import torch
# CPU推理测试
model = torch.nn.Transformer().cpu()
input_cpu = torch.randn(1, 512, 512).cpu()
%timeit model(input_cpu) # 输出: 1 loop, best of 5: 2.3 s per loop
# GPU推理测试
model = model.cuda()
input_gpu = input_cpu.cuda()
%timeit model(input_gpu) # 输出: 10 loops, best of 5: 28 ms per loop加速比:约82倍
3.2 专用硬件加速
-
Tensor Core:支持混合精度计算(FP16/FP32),A100的TF32性能达156 TFLOPS
-
NVLink:多卡互联带宽达600GB/s(比PCIe 4.0快5倍)
四. 硬件信息查看实战
4.1 Python查看GPU信息
import torch
from pynvml import *
# 基础信息
print(f"PyTorch版本: {torch.__version__}")
print(f"CUDA可用: {torch.cuda.is_available()}")
print(f"GPU数量: {torch.cuda.device_count()}")
# 详细参数
nvmlInit()
handle = nvmlDeviceGetHandleByIndex(0)
info = nvmlDeviceGetMemoryInfo(handle)
print(f"设备名称: {nvmlDeviceGetName(handle)}")
print(f"显存总量: {info.total/1024**3:.2f} GB")
print(f"计算能力: {nvmlDeviceGetCudaComputeCapability(handle)}")输出示例:
PyTorch版本: 2.0.1
CUDA可用: True
GPU数量: 8
设备名称: b'NVIDIA A100-SXM4-80GB'
显存总量: 81.92 GB
计算能力: (8, 0)4.2 关键性能指标解析
-
FP16算力:影响混合精度训练速度
-
显存带宽:决定数据传输效率
-
TDP功耗:影响散热和电费成本
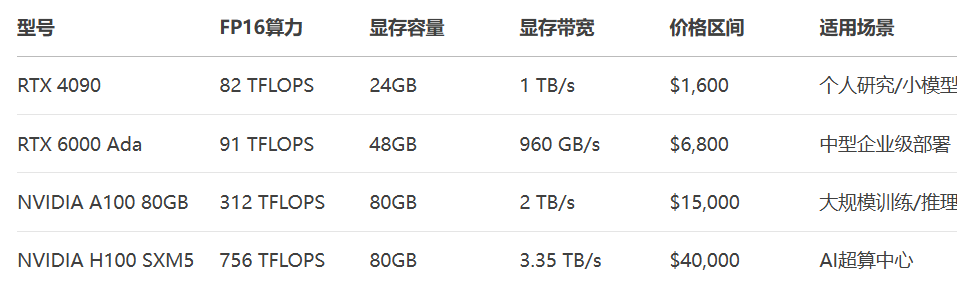
五. GPU选型策略与实战指南
5.1 选型决策树
预算 < \$5k → RTX 4090(24GB)
预算 \$5k-\$20k → RTX 6000 Ada(48GB)
预算 > \$20k → H100/A100(80GB)5.2 主流GPU对比表
六. 大模型推理硬件配置案例
6.1 LLaMA-2 70B配置建议
-
单卡场景:
-
至少80GB显存(A100/H100)
-
启用量化(4-bit)可将显存需求降至35GB
-
-
多卡场景:
-
4×RTX 4090通过NVLink互联
-
使用DeepSpeed ZeRO-3优化显存
-
代码示例:多卡推理
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-70b-chat-hf",
device_map="auto", # 自动分配多卡
torch_dtype=torch.float16
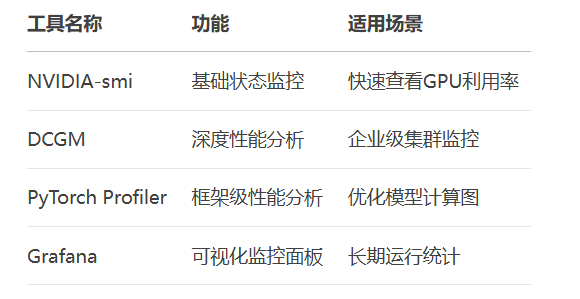
)附:硬件监控工具推荐
注:本文代码需安装以下依赖:
pip install torch pynvml transformers更多AI大模型应用开发学习内容,尽在聚客AI学院。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











