Spark编程2
接2.Spark架构及编程
五、Spark核心编程
5.6 累加器
5.6.1 累加器基本介绍
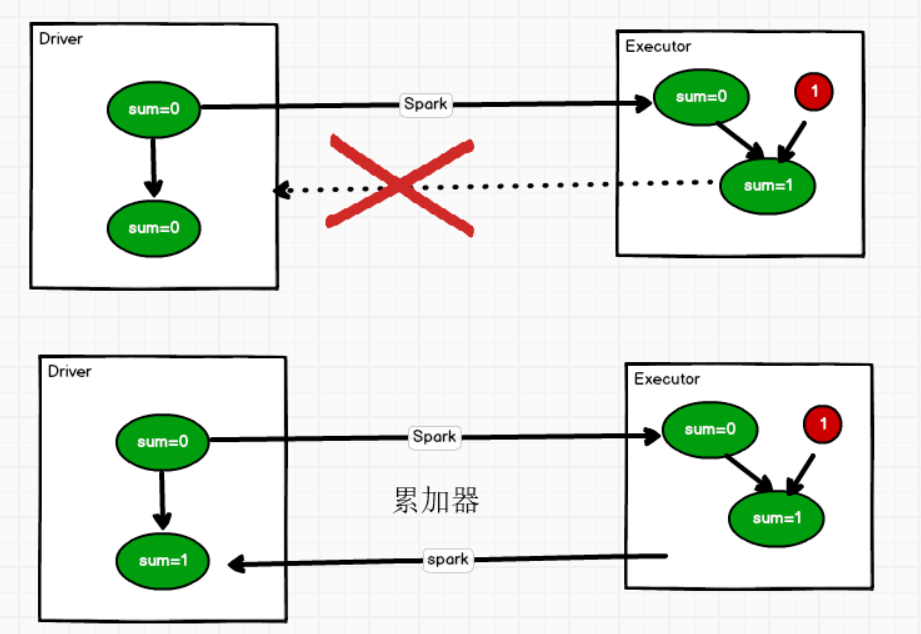
分布式共享只写变量,使用累加器完成数据的累加。
1. 分布式:每一个executor都拥有这个累加器
2. 共享:Driver中的变量原封不动的被executor拥有一份副本
3. 只写:同一个executor中可以对这个变量进行改值,其他的executor不能读取。
累加器用来把Executor端变量信息聚合到Driver端。在Driver程序中定义的变量,在Executor端的每个Task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回Driver端进行merge
所谓累加器,一般作用就是累加(可以是数值的累加,也可以是数据的累加)
5.6.2 累加器的使用
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4),2)
val sum: LongAccumulator = sc.longAccumulator("sum")
rdd.foreach(num =>{
sum.add(num)
})
println(sum.value)
longAccumulator 、doubleAccumulator()、collectionAccumulator()
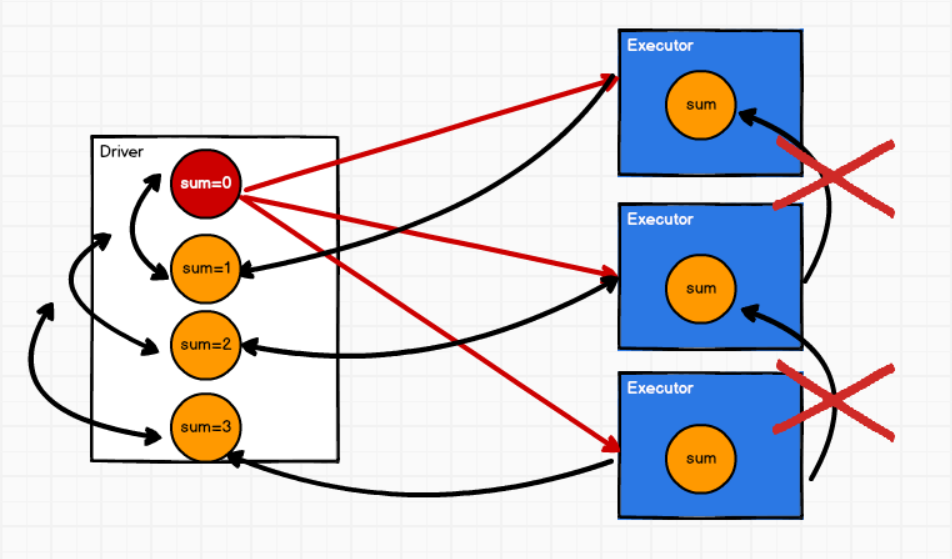
5.6.3 累加器的具体流程
1. 将累加器变量注册到spark中
2. 执行计算时,spark会将累加器发送到executor执行计算
3. 计算完毕后,executor会将累加器的计算结果返回到driver端。
4. driver端获取到多个累加器的结果,然后两两合并。最后得到累加器的执行结果
5.6.4 自定累加器
1. 自定义累加器类,继承extends AccumulatorV2[IN, OUT]
2. IN:累加器输入数据的类型
OUT:累加器返回值的数据类型
需指定如上两个参数的数据类型
3. 重写AccumulatorV2中6个方法
override def isZero: Boolean = ???
override def copy(): AccumulatorV2[String, mutable.Map[String, Int]] = ???
override def reset








 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









