







1、任务及数据集描述
实现利用bert预训练模型进行中文新闻分类,共10类,使用的数据集情况:

其中,train.txt, dev.txt, test.txt内容格式为每一行为“内容 Tab 标签”:

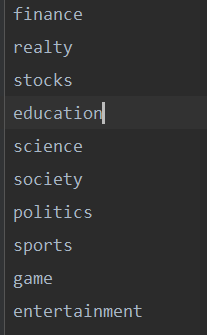
class.txt内容为10类的新闻标签,如上面的0就代表finance这一类。
2、bert模型准备
(1)下载bert中文预训练模型chinese_L-12_H-768_A-12,解压后里面包含5个文件:模型、配置文件与词典。
(2)去github上下载bert源码:https://github.com/google-research/bert.git
3、修改源码实现文本分类
我们只需要将我们的数据输入处理成标准的结构输入就可以了,在run_classifier.py文件中,有一个DataProcessor基类:
class DataProcessor(object):
"""Base class for data converters for sequence classification data sets."""
def get_train_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the train set."""
raise NotImplementedError()
def get_dev_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the dev set."""
raise NotImplementedError()
def get_test_examples(self, data_dir):
"""Gets a collection of `InputExample`s for prediction."""
raise NotImplementedError()
def get_labels(self):
"""Gets the list of labels for this data set."""
raise NotImplementedError()
@classmethod
def _read_tsv(cls, input_file, quotechar=None):
"""Reads a tab separated value file."""
with tf.gfile.Open 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









