









分布式重建缓存的并发冲突问题
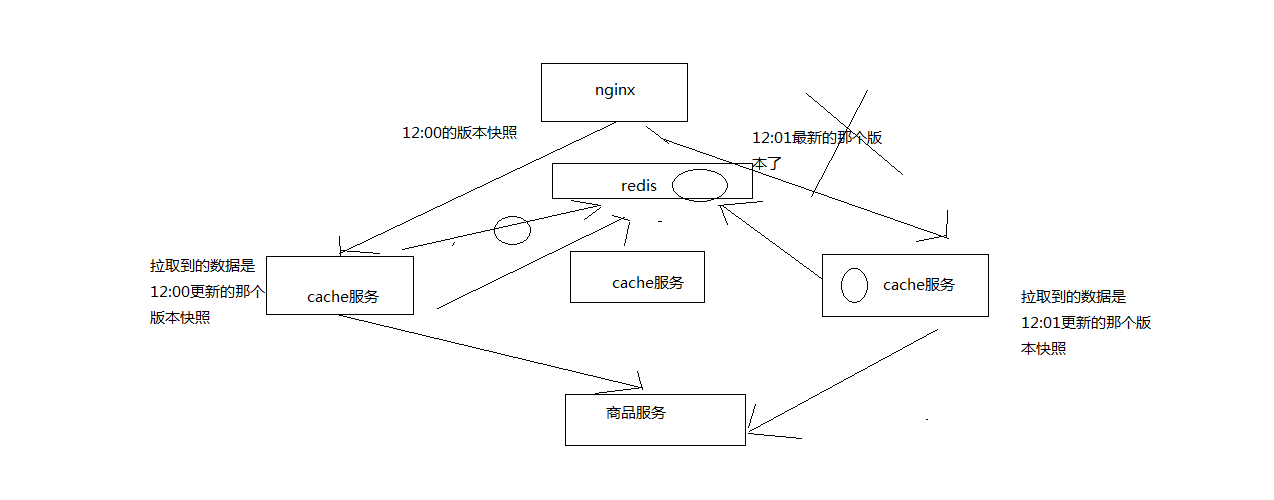
缓存更新和缓存重建在不同机器上的并发冲突问题

基于zookeeper分布式锁的冲突解决方案
比如我们这里,数据在所有的缓存中都不存在了(LRU算法弄掉了),就需要重新查询数据写入缓存,重建缓存
分布式的重建缓存,在不同的机器上,不同的服务实例中,去做上面的事情,就会出现多个机器分布式重建去读取
相同的数据,然后写入缓存中,可能出现分布式重建缓存的并发冲突问题
1.缓存更新和缓存重建在不同机器上的并发冲突问题
2.多个缓存服务实例分布式重建的并发冲突问题
1、流量均匀分布到所有缓存服务实例上
应用层nginx,是将请求流量均匀地打到各个缓存服务实例中的,可能咱们的eshop-cache那个服务,可能会部署多实例在不同的机器上
2、应用层nginx的hash,固定商品id,走固定的缓存服务实例
搞一堆应用层nginx的地址列表,对每个商品id做一个hash,然后对应用nginx数量取模将每个商品的请求
固定分发到同一个应用层nginx上面去
在应用层nginx里,发现自己本地lua shared dict缓存中没有数据的时候,就采取一样的方式,对product id取模,
然后将请求固定分发到同一个缓存服务实例中去
这样的话,就不会出现说多个缓存服务实例分布式的去更新那个缓存了
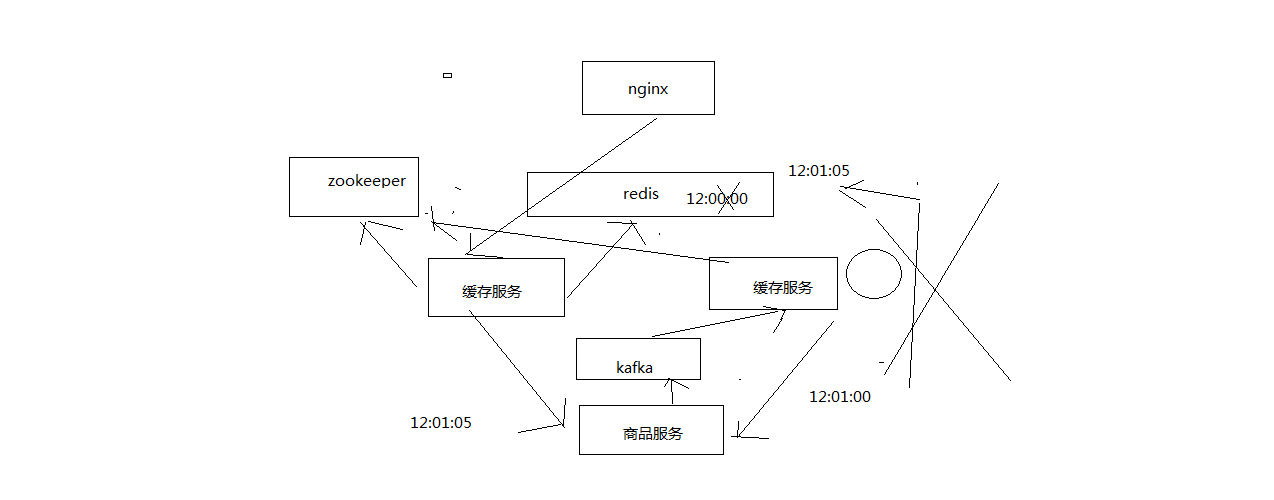
3、源信息服务发送的变更消息,需要按照商品id去分区,固定的商品变更走固定的kafka分区,也就是固定的一个缓存服务实例获取到
缓存服务,是监听kafka topic的,一个缓存服务实例,作为一个kafka consumer,就消费topic中的一个partition
所以你有多个缓存服务实例的话,每个缓存服务实例就消费一个kafka partition
所以这里,一般来说,你的源头信息服务,在发送消息到kafka topic的时候,都需要按照product id去分区
也就时说,同一个product id变更的消息一定是到同一个kafka partition中去的,也就是说同一个product id的变更消息,
一定是同一个缓存服务实例消费到的
实现:kafka producer api,里面send message的时候,多加一个参数就可以了,product id传递进去,就可以了
4、自己写的简易的hash分发,与kafka的分区,可能并不一致
我们自己写的简易的hash分发策略,是按照crc32去取hash值,然后再取模的
关键你又不知道你的kafka producer的hash策略是什么,很可能说跟我们的策略是不一样的
那就可能导致,数据变更的消息所到的缓存服务实例,跟我们的应用层nginx分发到的那个
缓存服务实例也许就不在一台机器上了,这样的话,在高并发,极端的情况下,可能就会出现冲突
5、分布式的缓存重建并发冲突问题发生解决:
分布式锁,如果你有多个机器在访问同一个共享资源,那么这个时候,如果你需要加个锁,让多个
分布式的机器在访问共享资源的时候串行起来,那么这个时候,那个锁,多个不同机器上的服务共享的锁,就是分布式锁
分布式锁当然有很多种不同的实现方案,redis分布式锁,zookeeper分布式锁,zk,做分布式协调这一块,还是很流行
的,大数据应用里面,hadoop,storm,都是基于zk去做分布式协调
5.2 zk分布式锁的解决并发冲突的方案
(1)变更缓存重建以及空缓存请求重建,更新redis之前,都需要先获取对应商品id的分布式锁
(2)拿到分布式锁之后,需要根据时间版本去比较一下,如果自己的版本新于redis中的版本,那么就更新,否则就不更新
(3)如果拿不到分布式锁,那么就等待,不断轮询等待,直到自己获取到分布式的锁















 708
708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









