







 本文详细探讨了Guava Cache的LRU实现,解释了其内部如何通过LocalCache和Segment进行数据存储及移除。此外,还讨论了缓存穿透的情况,指出Guava Cache在单个key失效时不会造成批量穿透,确保了并发安全性。最后,介绍了失效key的处理机制以及如何查看和优化缓存命中率。
本文详细探讨了Guava Cache的LRU实现,解释了其内部如何通过LocalCache和Segment进行数据存储及移除。此外,还讨论了缓存穿透的情况,指出Guava Cache在单个key失效时不会造成批量穿透,确保了并发安全性。最后,介绍了失效key的处理机制以及如何查看和优化缓存命中率。
在日常使用本地缓存的时候,我们经常会选择GuavaCache,使用起来很方便。不过也会有一些疑惑,主要的疑问点有:
- 如何实现的LRU缓存, LFU又是如何实现的
- 单个key失效大量请求会造成雪崩吗
- 失效key的处理是怎么样的
- Cache命中率查看
那么接下来就让我们一起来看看吧。
LRU缓存是如何实现的
一切我们从CacheBuilder看起,因为这个类是我们经常用来构建GuavaCache的入口。
public <K1 extends K, V1 extends V> Cache<K1, V1> build() {
checkWeightWithWeigher();
checkNonLoadingCache();
return new LocalCache.LocalManualCache<K1, V1>(this);
}
我们从这里可以看到,build方法是返回了一个LocalCache。
LocalCache是一个ConcurrentMap的实现,也是通过分段Segment和链表进行存储的数据,这里我们不展开。
找到移除的方法com.google.common.cache.LocalCache.Segment#evictEntries,我们一起理解一下。
void evictEntries(ReferenceEntry<K, V> newest) {
if (!map.evictsBySize()) {
return;
}
drainRecencyQueue();
// If the newest entry by itself is too heavy for the segment, don't bother evicting
// anything else, just that if (newest.getValueReference().getWeight() > maxSegmentWeight) {
if (!removeEntry(newest, newest.getHash(), RemovalCause.SIZE)) {
throw new AssertionError();
}
}
while (totalWeight > maxSegmentWeight) {
ReferenceEntry<K, V> e = getNextEvictable();
if (!removeEntry(e, e.getHash(), RemovalCause.SIZE)) {
throw new AssertionError();
}
}
}
逻辑说明:
- 判断设置了最大容量,如果不是的话直接就返回了。
- 从名称来干,清空可以知晓一二。具体的循环弹出
recencyQueue的元素,如果accessQueue包含这个元素,那么就把这个元素添加到accessQueue的末尾。 - 如果最新添加的这个元素已经超过了
maxSegmentWeight,那么就直接移除它。否则继续向下。 - 获取可移除的元素,进行移除操作,直到
totalWeight小于maxSegmentWeight。我们接下来看一下获取的具体代码。
第一步判断适用的maxWeight,在
LocalCache的构造函数里可以看到即便我们没有直接设置maxWeight,也会进行com.google.common.cache.CacheBuilder#getMaximumWeight的设置。
第二步中 为什么要先判断accessQueue是否包含呢?
首先我们要看一下accessQueue什么时候会添加元素和删除元素,从代码可以看出来,在write和lockRead的时候会添加,在元素的时候也会删除,所以可以认为这里存储当前现有的元素。而recencyQueue什么时候会添加元素和删除元素呢? 只有在读取的时候com.google.common.cache.LocalCache.Segment#recordRead会添加元素,没有删除元素。 基于这两个点我们就很清楚了,如果缓存失效很快,很容易会出现在recencyQueue但是却已经不属于队列的元素了,所以要先判断是否还有效。但这个数据结构怎么能够支持LRU呢?我们接着往下看。
segmentWeight的初始化公式是long maxSegmentWeight = maxWeight / segmentCount + 1,而这里的totalWeight也是每个segment自己管理的,所以使用了这两个进行比较。
接下来我们来一起看一下getNextEvictable方法:
ReferenceEntry<K, V> getNextEvictable() {
for (ReferenceEntry<K, V> e : accessQueue) {
int weight = e.getValueReference().getWeight();
if (weight > 0) {
return e;
}
}
throw new AssertionError();
}
我们看到是在循环accessQueue,如果value的weight大于0,那么就可以被移除。从build的com.google.common.cache.CacheBuilder#getWeigher可以看到,如果不设置,我们会有一个对key设置weight的weigher,默认都是1,所以肯定都可以返回。
但是这里问题就来了,我们前面知道accessQueue会在write的时候添加,并且在drainRecencyQueue的时候还会添加一遍,那么一个元素岂不是可以在这个queue里存在两次,那么移除的也就不是LRU了?
这里其中的奥秘就在于com.google.common.cache.LocalCache.AccessQueue#offer方法。(队列add的方法其实调用的是offer,所以这里覆盖了offer的实现,在调用add的时候就会调到。)
@Override
public boolean offer(ReferenceEntry<K, V> entry) {
// unlink
connectAccessOrder(entry.getPreviousInAccessQueue(), entry.getNextInAccessQueue());
// add to tail
connectAccessOrder(head.getPreviousInAccessQueue(), entry);
connectAccessOrder(entry, head);
return true;
}
我们从代码上可以看到,首先是将元素从原来的链表里删除,让它的前后两个元素连接在一起,之后再添加到队列,这样就不会出现在一个队列里出现两个元素。这么写的方法有点难理解,我简单画了一个图示意一下,基本就是head的pre指针每次都指向最后一个元素,然后再下次再把新的元素连接到最后。
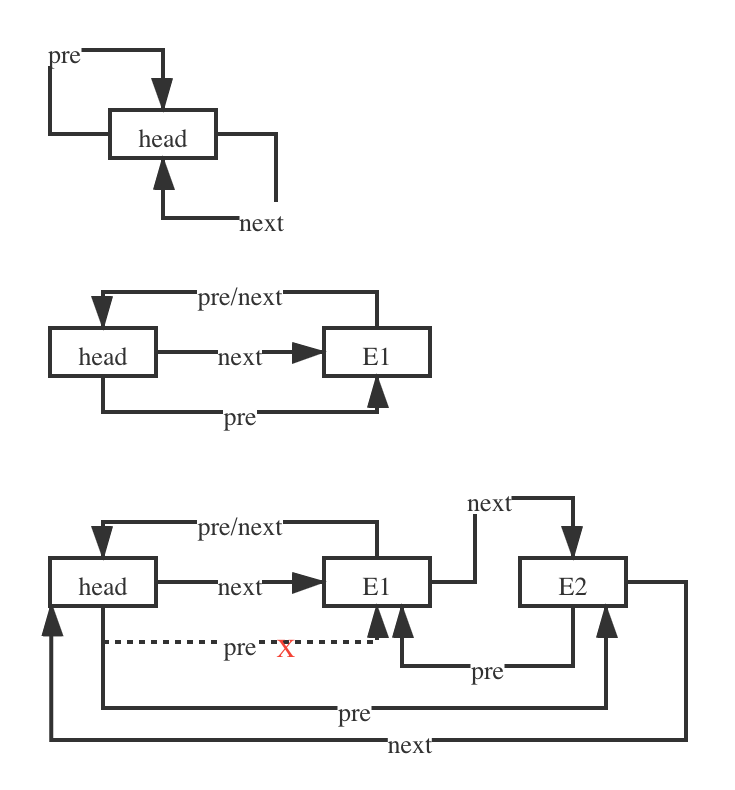
到这里我们基本就能明白了,LRU的实现。简单来说就是一个先入先出的队列,再遇到一个元素时就把这个元素移动到末尾,原来也很简单。
接下来我们来看一下与它关联性很强,由Caffeine代言的Window-TinyLFU又是如何实现的。
我简单画了一下下面的图总结了一下,里面的实现复杂度还是挺高的。

计数通常会被放到一个hashmap里,如果数量变多时,冲突就会变得越来越多。所有就发明了Count-min Sketch算法。这个算法思想是如果单个hash产生的冲突会变多,那么我们是不是可以近似计算,并且在hash冲突的时候通过多次hash组合起来的方式减少冲突?所以在Count-min Sketch算法里就是对key做4次hash,然后将4个hash对应的位置上数字进行操作,在计算热度的时候取最小值,这样可以最接近真实的频率。存储上使用类似于布隆过滤器的位存储,不过因为是数字,所以要多位存储一个数字。
TINY-LFU的稀疏流量是流量不是一下子打进来,而是有一定速度的打进来,因为容量被那些突然而来的热点流量占满了,所以就没有办法积累频率,从而进入不了热点缓存,但在接下来一段时间内并不适用,导致缓存了无用的数据。而这样的情况正好是LRU擅长的,所以Window Tiny-LFU就把两者结合起来,先有1%的LRU,然后通过LRU过期的数据会根据频率进行淘汰。因为LRU只占1%,其实对于LFU的影响很小。
具体来说,新的Item先进入Winodw区,当window区需要淘汰的时候就和probation区的频率做对比,如果满足频率那么就会提交到主缓存,否则就会直接丢掉。probation缓存再有一定次数之后会进入protected区域。protected区域占比80%,probation区域占比20%。
缓存单key失效批量穿透吗?
缓存穿透查询,这个对应在Guava中是LoadingCache,所以我们看一下com.google.common.cache.LocalCache#get(K, com.google.common.cache.CacheLoader<? super K,V>)方法。
V get(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException {
checkNotNull(key);
checkNotNull(loader);
try {
// count是当前segement中元素的数量
if (count != 0) { // read-volatile
// don't call getLiveEntry, which would ignore loading values
ReferenceEntry<K, V> e = getEntry(key, hash);
if (e != null) {
long now = map.ticker.read();
V value = getLiveValue(e, now);
if (value != null) {
recordRead(e, now);
statsCounter.recordHits(1);
// 判断是否有设置刷新并且已经需要刷新,如果是的话就异步load返回旧值 否则返回新值
return scheduleRefresh(e, key, hash, value, now, loader);
}
ValueReference<K, V> valueReference = e.getValueReference();
//
if (valueReference.isLoading()) {
return waitForLoadingValue(e, key, valueReference);
}
}
}
// 用锁的方式去获取key
return lockedGetOrLoad(key, hash, loader);
} catch (ExecutionException ee) {
...
}
从这里我们看到了三个去load的场景:
- value不为null,那么按scheduleRefresh的方式去获取
- 否则value正在加载中,那么就waitForLoadingValue方式去获取
- 如果segement中没有存活的元素,那么就按lockedGetOrLoad方式去获取
接下来就让我们分别来看一下这三种都是如何获取的。
scheduleRefresh异步刷新获取
if (map.refreshes()
&& (now - entry.getWriteTime() > map.refreshNanos)
&& !entry.getValueReference().isLoading()) {
V newValue = refresh(key, hash, loader, true);
if (newValue != null) {
return newValue;
}
}
return oldValue;
首先判断map是否设置了刷新,此Entry是否需要刷新,此Entry不在loading中,那么就会执行refresh获取。
V refresh(K key, int hash, CacheLoader<? super K, V> loader, boolean checkTime) {
final LoadingValueReference<K, V> loadingValueReference =
insertLoadingValueReference(key, hash, checkTime);
if (loadingValueReference == null) {
return null;
}
ListenableFuture<V> result = loadAsync(key, hash, loadingValueReference, loader);
if (result.isDone()) {
try {
return Uninterruptibles.getUninterruptibly(result);
} catch (Throwable t) {
// don't let refresh exceptions propagate; error was already logged
}
}
return null;
}
在refresh的开始就会先锁的方式设置loadingReference,如果发现此时已经其他线程已经开始load了,那么就会返回null。对于scheduleRefresh方法来说就会返回旧值。注意此时loadAsync方法中穿透时使用了线程池。
结论: 不会造成多个穿透,每一个Entry过期后只会有一个线程进行load的状态,其他返回旧值。
waitForLoadingValue的方式获取
前提条件: 如果是当前Entry存在,并且value是null,并且是在加载过程中。我们一起来看一下waitForLoadingValue的具体实现。
V waitForLoadingValue(ReferenceEntry<K, V> e, K key, ValueReference<K, V> valueReference)
throws ExecutionException {
if (!valueReference.isLoading()) {
throw new AssertionError();
}
checkState(!Thread.holdsLock(e), "Recursive load of: %s", key);
// don't consider expiration as we're concurrent with loading
try {
V value = valueReference.waitForValue();
if (value == null) {
throw new InvalidCacheLoadException("CacheLoader returned null for key " + key + ".");
}
// re-read ticker now that loading has completed
long now = map.ticker.read();
recordRead(e, now);
return value;
} finally {
statsCounter.recordMisses(1);
}
}
首先判断了不是当前线程在Loading,否则就抛出一个异常,异常信息是递归加载这个key。之所以这么写,还是需要结合getLiveValue一起来分析,在loading的时候会返回null, 所以在loading的线程,按道理肯定不会进入这里,而是会进入到scheduleRefresh或者lockedGetOrLoad。
然后调用valueReference.waitForValue()方法,在这个方法里是等待同一个com.google.common.cache.LocalCache.LoadingValueReference#futureValue返回。
结论: 如果value正在loading的,会进入循环等待获取之前进入Loading线程返回的值。
lockedGetOrLoad获取
前提条件: Entry不存在 或者 Entry存在但是value已经失效。
V lockedGetOrLoad(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException {
ReferenceEntry<K, V> e;
ValueReference<K, V> valueReference = null;
LoadingValueReference<K, V> loadingValueReference = null;
boolean createNewEntry = true;
lock();
try {
int newCount = this.count - 1;
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
for (e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash
&& entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
valueReference = e.getValueReference();
if (valueReference.isLoading()) {
createNewEntry = false;
} else {
V value = valueReference.get();
...
return value;
...
}
break;
}
}
if (createNewEntry) {
loadingValueReference = new LoadingValueReference<K, V>();
if (e == null) {
e = newEntry(key, hash, first);
e.setValueReference(loadingValueReference);
table.set(index, e);
} else {
e.setValueReference(loadingValueReference);
}
}
}
...
if (createNewEntry) {
...
synchronized (e) {
return loadSync(key, hash, loadingValueReference, loader);
}
...
} else {
// The entry already exists. Wait for loading.
return waitForLoadingValue(e, key, valueReference);
}
}
重点说明:
- 会先加载,没有获取到锁的就会等待
- 是否已经在loading中,如果是的话就会等待loading value的返回
- 否则就会同步加载,返回value
结论: 使用了锁,不会造成单个key不存在多个线程同时load的情况。
看了三个穿透场景,我们就可以下结论了,这里不可能出现单个key需要穿透,而多个线程一起穿透的情况。
但有一点要注意的是,refresh不是按time去refresh的,而是access的时候触发的。
失效key的处理是怎么样的
一般来想,我们都会想到失效key是立即就不存在了。但是如果熟悉Redis失效机制的同学就会知道,这个事情并不能每次都做,最好的方式是先逻辑失效再清理空间,guava也采用的是这种方式。关键的代码在com.google.common.cache.LocalCache.Segment#getLiveEntry中。
ReferenceEntry<K, V> e = getEntry(key, hash);
if (e == null) {
return null;
} else if (map.isExpired(e, now)) {
tryExpireEntries(now);
return null;
}
return e;
}
代码也比较简单,获取这个Entry的时候回判断是否已经失效了,如果是的话就会在不在清理中,如果不在就会进行清理,然后返回null,否则会直接返回null。
Cache命中率查看
当我们想使用一个JVM本地内存优化时,命中率的指标相当关键,根据命中率我们会调整我们设置的最大容量或者失效时间。那么如何能够查看命中率呢?其实也比较简单。我们当时的做法是在在Cache的build过程中开启recordStats,然后将cache放入到集合中,压测的时候通过Controller的方式定时查看。
代码如下:
public BaseCache(long maxSize, long duration, TimeUnit timeUtil, ExecutorService executorService)
{
cache = CacheBuilder.newBuilder()
.maximumSize(maxSize)
.refreshAfterWrite(duration, timeUtil)
.recordStats()
.build(CacheLoader.asyncReloading(new CacheLoader<K, V>() {
@Override
public V load(K k) {
return loadData(k);
}
}, executorService));
}
当然这种方式比较low。如果能主动将这些缓存命中的信息,甚至key的信息上报,那么是不是就可以做更多的事情了,现在很多的自我调整缓存就是这样的思路,比如JD-hotkey。

















 4946
4946

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









