






本地缓存是我们在日常开发工作中不可或缺的一种缓存方式,不仅简单易用,而且提供了比远程缓存更高的性能。而本地缓存的使用又以Guava Cache最常见,通常称为Google Guava Cache,是Google提供的一款缓存库,是Guava项目的一部分,Guava Cache专门设计用于帮助开发人员在Java应用程序中管理和优化内存缓存。
1、数据结构
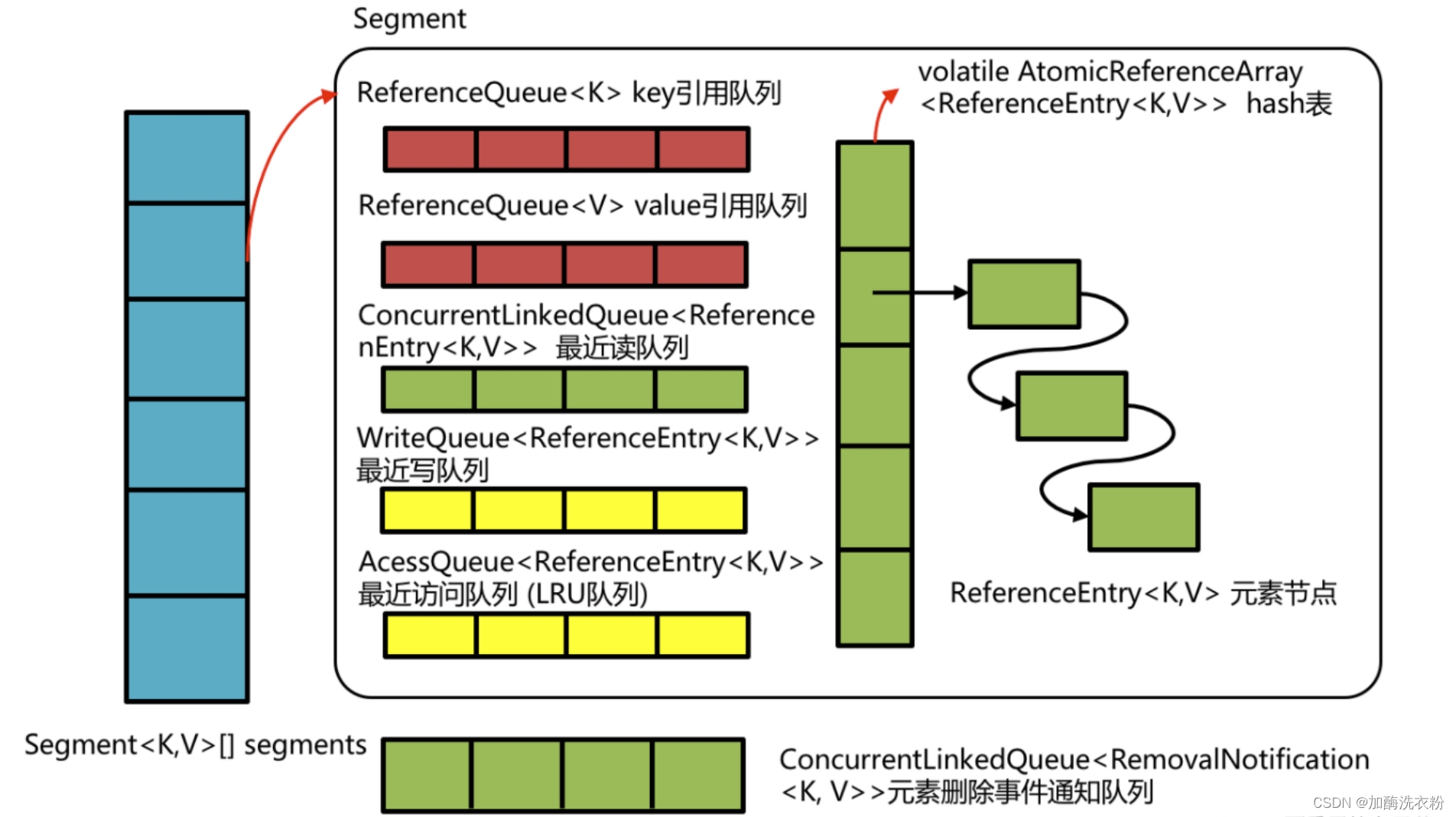
Cache类似于Map,它是存储键值对的集合,然而它和Map不同的是它还需要处理evict,expire,dynamic load等逻辑,需要一些额外信息来实现这些操作。在面向对象思想中,经常使用类对一些关联性比较强的数据做封装,同时把数据相关的操作放到该类中。因而Guava Cache使用ReferenceEntry接口来封装一个键值对,而用ValueReference来封装值值。
Cache的数据结构设计方式采用ConcurrentHashMap的设计方式,在Cache里面自定义了Segment的属性和存储,缓存数据被封装成ReferenceEntry对象,存储在AtomicReferenceArray数组中,整体数据结构如下图所示:
2、使用方式
Guava Cache提供了两种方式构造Cache对象:CacheLoader和Callable。
CacheLoader
构造 LoadingCache 的关键在于实现 load 方法,也就是在需要访问的缓存项不存在的时候 Cache 会自动调用 load 方法将数据加载到 Cache中,除了实现 load 方法之外还可以配置缓存相关的一些性质,比如过期加载策略、刷新策略 。
public static final LoadingCache<String, String> CACHE = CacheBuilder
.newBuilder()
// 最大容量为 100 超过容量有对应的淘汰机制,下文详述
.maximumSize(100)
// 缓存项写入后多久过期,下文详述
.expireAfterWrite(60 * 5, TimeUnit.SECONDS)
// 缓存写入后多久自动刷新一次,下文详述
.refreshAfterWrite(60, TimeUnit.SECONDS)
// 创建一个 CacheLoader,load 表示缓存不存在的时候加载到缓存并返回
.build(new CacheLoader<String, String>() {
// 加载缓存数据的方法
@Override
public String load(String key) {
return "cache [" + key + "]";
}
});Callable
除了在构造 Cache 对象的时候指定 load 方法来加载缓存外,我们亦可以在获取缓存项时指定载入缓存的方法。通过get方法当缓存不存在的时候,加载缓存数据到缓存中。
//构造Cache对象
public static final Cache<String, String> SIMPLE_CACHE = CacheBuilder
.newBuilder()
.build();
//通过KEY获取缓存数据
public String get(String key) {
return SIMPLE_CACHE.get(key, ()->{
//此处省略部分为加载缓存的操作,当key获取不到值的时候会执行
}
);
}
Callable的方式相比CacheLoader来说更加灵活一点,可以针对每一个key设置不同的记载机制。
3、缓存回收
缓存的大小需要有限制,不可能无限扩张,特别是进程内的缓存。Guava Cache为我们提供了三种缓存回收的机制。
基于容量的回收
在构建Cache对象的时候我们可以设置可容纳的最大缓存数量,当超过一定最大数量的时候,Cache会淘汰一部分已有的数据,这里采用的是LRU淘汰策略,即访问频率最低的被淘汰。
使用案例:
@GuardedBy("this")
void evictEntries(ReferenceEntry<K, V> newest) {
if (!map.evictsBySize()) {
return;
}
drainRecencyQueue();
if (newest.getValueReference().getWeight() > maxSegmentWeight) {
if (!removeEntry(newest, newest.getHash(), RemovalCause.SIZE)) {
throw new AssertionError();
}
}
//容量超过最大值开始执行淘汰策略,一直到容量满足要求
while (totalWeight > maxSegmentWeight) {
ReferenceEntry<K, V> e = getNextEvictable();
if (!removeEntry(e, e.getHash(), RemovalCause.SIZE)) {
throw new AssertionError();
}
}
}
//从访问队列头部开始遍历,找到权重大于0
@GuardedBy("this")
ReferenceEntry<K, V> getNextEvictable() {
for (ReferenceEntry<K, V> e : accessQueue) {
int weight = e.getValueReference().getWeight();
if (weight > 0) {
return e;
}
}
throw new AssertionError();
}基于超时时间回收
CacheBuilder提供两种定时回收的方法:
-
expireAfterAccess(long, TimeUnit):缓存项在给定时间内没有被读/写访问,则回收。请注意这种缓存的回收顺序和基于大小回收一样。
-
expireAfterWrite(long, TimeUnit):缓存项在给定时间内没有被写操作(创建或覆盖),则回收。如果认为缓存数据总是在固定时候后变得陈旧不可用,这种回收方式是可取的。
这里要注意一点,针对上面这个回收机制Cache不是通过开启异步线程进行定时去执行的,而是跟我们的缓存get和put操作同步去执行的。在put的时候一定会去检查元素的这两个时间,在get的时候如果发现获取到的值过期了才会去进行检查。
过期检查的方式是expireEntries,会涉及到WriteQueue和AccessQueue两个队列,在执行put和get操作的时候,会去维护这两个队列的数据。可以看到这里Cache执行过期策略并没有去遍历整个数据,只对有操作过的数据做策略应用。
@GuardedBy("this")
void expireEntries(long now) {
drainRecencyQueue();
ReferenceEntry<K, V> e;
//从写队列中获取数据,看写数据是否有过期
while ((e = writeQueue.peek()) != null && map.isExpired(e, now)) {
if (!removeEntry(e, e.getHash(), RemovalCause.EXPIRED)) {
throw new AssertionError();
}
}
//从访问队列中后去数据,看访问时间是否过期
while ((e = accessQueue.peek()) != null && map.isExpired(e, now)) {
if (!removeEntry(e, e.getHash(), RemovalCause.EXPIRED)) {
throw new AssertionError();
}
}
}基于引用的回收
从开头部分Cache的数据结构中我们可以知道Segment里面存储的是引用对象RefrenceEntry,通过weakKeys和weakValues方法指定Cache只保存对缓存记录key和value的弱引用。这样当没有其他强引用指向key和value时,key和value对象就会被垃圾回收器回收。
CacheBuilder.weakKeys():使用弱引用存储键。当键没有其它(强或软)引用时,缓存项可以被垃圾回收。因为垃圾回收仅依赖恒等式(==),使用弱引用键的缓存用==而不是equals比较键。
CacheBuilder.weakValues():使用弱引用存储值。当值没有其它(强或软)引用时,缓存项可以被垃圾回收。因为垃圾回收仅依赖恒等式(==),使用弱引用值的缓存用==而不是equals比较值。
CacheBuilder.softValues():使用软引用存储值。软引用只有在响应内存需要时,才按照全局最近最少使用的顺序回收。使用软引用值的缓存同样用==而不是equals比较值。
4、源码解析
Cache的核心类是LocalCache,先整体看下 Cache 的类结构,下面的这些子类表示了不同的创建方式本质还都是 LocalCache:

源码这部分核心梳理一下get的操作流程,主要的操作流程也是在这里,下面先看一下get操作的流程图,可以结合后续的源码进行理解:
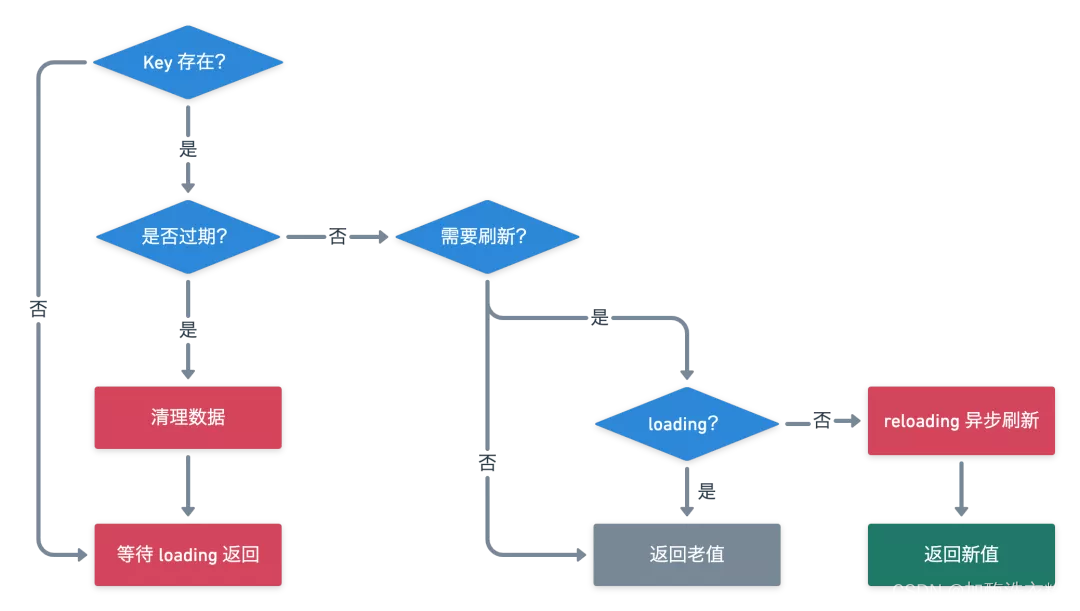
LocalCache#get
V get(K key, CacheLoader<? super K, V> loader) throws ExecutionException {
// 根据key计算hash值得到segment的位置
int hash = hash(checkNotNull(key));
return segmentFor(hash).get(key, hash, loader);
}Segment#get
V get(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException {
checkNotNull(key);
checkNotNull(loader);
try {
if (count != 0) {
// 获取 segment 中的元素 (ReferenceEntry) 包含正在 load 的数据
ReferenceEntry<K, V> e = getEntry(key, hash);
if (e != null) {
long now = map.ticker.read();
//判断值是否过期,这里如果有过期值会走淘汰逻辑,把过期数据清理一遍
V value = getLiveValue(e, now);
if (value != null) {
// 记录访问时间
recordRead(e, now);
// 访问次数+1
statsCounter.recordHits(1);
// 刷新缓存并返回
return scheduleRefresh(e, key, hash, value, now, loader);
}
ValueReference<K, V> valueReference = e.getValueReference();
// 如果数据不存在但是有其他线程在加载,那么就等待其他线程加载完直接返回结果
if (valueReference.isLoading()) {
return waitForLoadingValue(e, key, valueReference);
}
}
}
// 到这里说明key没有对应的值,那么就直接去加载
return lockedGetOrLoad(key, hash, loader);
} catch (ExecutionException ee) {
Throwable cause = ee.getCause();
if (cause instanceof Error) {
throw new ExecutionError((Error) cause);
} else if (cause instanceof RuntimeException) {
throw new UncheckedExecutionException(cause);
}
throw ee;
} finally {
postReadCleanup();
}
}
Segment#scheduleRefresh
V scheduleRefresh(
ReferenceEntry<K, V> entry,
K key,
int hash,
V oldValue,
long now,
CacheLoader<? super K, V> loader)
// 如果配置了刷新策略并且刷新的时间到了
if (map.refreshes()
&& (now - entry.getWriteTime() > map.refreshNanos)
&& !entry.getValueReference().isLoading()) {
// 刷新缓存值,并且返回
V newValue = refresh(key, hash, loader, true);
if (newValue != null) {
return newValue;
}
}
return oldValue;
}
可以看到Cache的刷新的操作也是跟着get方法一起执行的,并没有后台单独启动线程去处理。这里注意一点就是没有过期的情况下再去看刷新配置,所以如果refreshAfterWrite > expireAfterWrite就永远不会刷新。
Segment#lockedGetOrLoad
当get操作发现值不存在的时候就会去执行load操作,这个时候如果有多个线程一起并发操作最终只有一个线程在load,其他线程都在等待,具体的实现就在这个lockedGetOrLoad方法里。
V lockedGetOrLoad(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException {
ReferenceEntry<K, V> e;
ValueReference<K, V> valueReference = null;
LoadingValueReference<K, V> loadingValueReference = null;
boolean createNewEntry = true;
// 获取锁,保证只有一个线程可以执行load
lock();
try {
// re-read ticker once inside the lock
long now = map.ticker.read();
preWriteCleanup(now);
int newCount = this.count - 1;
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
for (e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash
&& entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
valueReference = e.getValueReference();
// 判断是否有已经在Loading的任务
if (valueReference.isLoading()) {
createNewEntry = false;
} else {
V value = valueReference.get();
if (value == null) {
enqueueNotification(
entryKey, hash, value, valueReference.getWeight(), RemovalCause.COLLECTED);
} else if (map.isExpired(e, now)) {
// This is a duplicate check, as preWriteCleanup already purged expired
// entries, but let's accommodate an incorrect expiration queue.
enqueueNotification(
entryKey, hash, value, valueReference.getWeight(), RemovalCause.EXPIRED);
} else {
recordLockedRead(e, now);
statsCounter.recordHits(1);
// we were concurrent with loading; don't consider refresh
return value;
}
writeQueue.remove(e);
accessQueue.remove(e);
this.count = newCount; // write-volatile
}
break;
}
}
// 没有任务就创建一个loading任务,其他线程下次来获取的时候就会取到这个任务,然后判断发现在loading中就会等待
if (createNewEntry) {
loadingValueReference = new LoadingValueReference<>();
if (e == null) {
e = newEntry(key, hash, first);
e.setValueReference(loadingValueReference);
table.set(index, e);
} else {
e.setValueReference(loadingValueReference);
}
}
} finally {
unlock();
postWriteCleanup();
}
// 执行load操作
if (createNewEntry) {
try {
synchronized (e) {
return loadSync(key, hash, loadingValueReference, loader);
}
} finally {
statsCounter.recordMisses(1);
}
} else {
// 如果发现已经有loading中的,就等待,下面我们看下如何执行的等待
return waitForLoadingValue(e, key, valueReference);
}
}V waitForLoadingValue(ReferenceEntry<K, V> e, K key, ValueReference<K, V> valueReference)
throws ExecutionException
{
if (!valueReference.isLoading()) {
throw new AssertionError();
}
checkState(!Thread.holdsLock(e), "Recursive load of: %s", key);
try {
// 线程等待的关键在这一行,执行的是LoadingValueReference里面的等待方法
V value = valueReference.waitForValue();
if (value == null) {
throw new InvalidCacheLoadException("CacheLoader returned null for key " + key + ".");
}
long now = map.ticker.read();
recordRead(e, now);
return value;
} finally {
statsCounter.recordMisses(1);
}
}LoadingValueReference#waitForValue
@Override
public V waitForValue() throws ExecutionException {
return getUninterruptibly(futureValue);
}LoadingValueReference中有个future用来接受异步完成的值:
final SettableFuture<V> futureValue = SettableFuture.create();
线程等待就是通过该future来实现
public static <V extends @Nullable Object> V getUninterruptibly(Future<V> future)
throws ExecutionException {
boolean interrupted = false;
try {
// 循环获取futere的值
while (true) {
try {
// future get方法阻塞
return future.get();
} catch (InterruptedException e) {
interrupted = true;
}
}
} finally {
if (interrupted) {
Thread.currentThread().interrupt();
}
}
}5、总结
到这里关于Guava Cache相关的内容差不多都介绍完了,了解流程再加上源码的阅读可以更好的让我们理解框架的设计思路,这里我们自己也可以想下如果自己开发一个进程内缓存需要从哪些方面考虑:
-
数据结构:数据结构决定了我们使用的便利性和效率问题,所以第一步是要把数据结构确定好,用数据、链表还是字典来存储。
-
缓存限制:既然是进程内的缓存,那肯定有容量的限制,当容量达到上线的时候,我们该如何处理,采用那种淘汰方式。
-
并发访问:不管是数据结构还是加载数据,或者刷新数据等,我们都要考虑并发的情况。
-
数据有效性:虽说使用本地缓存的场景不要求强一致性,但是长时间的脏数据对用户体验也不好,关于数据的有效性主要是过期和刷新机制。














 907
907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









