






Solving Linear Inverse Problems Provably via Posterior Sampling with Latent Diffusion Models学习笔记

motivation:
没有利用预训练latent diffusion解决线性逆问题的工作,之前工作(DPS,DDRM)都只在像素空间
contribution:
利用预训练latent diffusion解决线性逆问题
background
SDE(随机微分方程),相当于加噪过程
d
x
=
f
(
x
,
t
)
d
t
+
g
(
t
)
d
w
\mathrm{d}x=f(x,t)\mathrm{d}t+g(t)\mathrm{d}\boldsymbol{w}
dx=f(x,t)dt+g(t)dw
条件反向SDE,通过反向SDE采样
p
0
(
x
0
∣
y
)
p_0(x_0|y)
p0(x0∣y)
d
x
=
(
f
(
x
,
t
)
−
g
2
(
t
)
(
∇
x
t
log
p
t
(
x
t
)
+
∇
x
t
log
p
(
y
∣
x
t
)
)
)
d
t
+
g
(
t
)
d
w
\mathrm{d}x=\left(f(x,t)-g^2(t)\left(\nabla_{x_t}\log p_t(x_t)+\nabla_{x_t}\log p(y|x_t)\right)\right)\mathrm{d}t+g(t)\mathrm{d}\boldsymbol{w}
dx=(f(x,t)−g2(t)(∇xtlogpt(xt)+∇xtlogp(y∣xt)))dt+g(t)dw
问题:
∇
x
t
log
p
(
y
∣
x
t
)
\nabla_{x_t}\log p(y|x_t)
∇xtlogp(y∣xt)难以求得
DPS计算方法:
p
(
y
∣
x
t
)
≈
p
(
y
∣
x
0
=
E
[
x
0
∣
x
t
]
)
=
N
(
y
;
μ
=
A
E
[
x
0
∣
x
t
]
,
Σ
=
σ
y
2
I
)
p(y|x_t)\approx p\left(y|x_0=\mathbb{E}[x_0|x_t]\right)=\mathcal{N}(y;\mu=\mathcal{A}\mathbb{E}[x_0|x_t],\Sigma=\sigma_y^2I)
p(y∣xt)≈p(y∣x0=E[x0∣xt])=N(y;μ=AE[x0∣xt],Σ=σy2I)
DPS用其给定噪声输入的情况下的条件期望
E
[
x
0
∣
x
t
]
\mathbb{E}[x_0|x_t]
E[x0∣xt] 替换未知的干净图像
x
0
x_0
x0 。这种近似下,
p
(
y
∣
x
t
)
p(y|x_t)
p(y∣xt)变得易于处理。
推导过程比较复杂,得到最终结果:
∇
x
t
log
p
(
y
∣
x
t
)
≃
−
ρ
∇
x
t
∥
y
−
A
(
x
0
)
∥
Λ
2
,
\nabla_{\boldsymbol{x}_t}\log p(\boldsymbol{y}|\boldsymbol{x}_t)\simeq-\rho\nabla_{\boldsymbol{x}_t}\|\boldsymbol{y}-\mathcal{A}(\boldsymbol{x}_0)\|_{\boldsymbol{\Lambda}}^2,
∇xtlogp(y∣xt)≃−ρ∇xt∥y−A(x0)∥Λ2,
DPS算法:

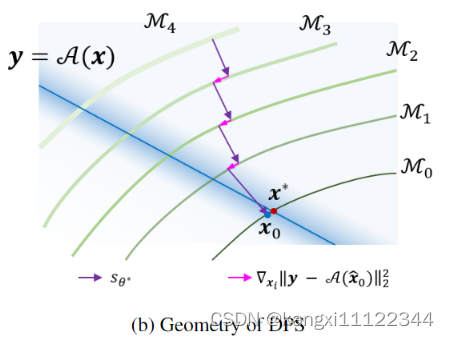
引入
∇
x
i
∥
y
−
A
(
x
^
0
)
∥
2
2
\nabla_{x_i}\|y-\mathcal{A}({\hat{x}}_0)\|_2^2
∇xi∥y−A(x^0)∥22的作用:当测量有噪声时,我们的方法防止样本从生成流形上脱落
method
在latent diffusion中
d
z
=
f
(
z
,
t
)
d
t
+
g
(
t
)
d
w
\mathrm{d}z=f(z,t)\mathrm{d}t+g(t)\mathrm{d}\boldsymbol{w}
dz=f(z,t)dt+g(t)dw
将DPS简单扩展(有问题):
p
(
y
∣
z
t
)
≈
p
(
y
∣
x
0
=
D
(
E
[
z
0
∣
z
t
]
)
)
p(y|z_t)\approx p(y|x_0=\mathcal{D}\left(\mathbb{E}[z_0|z_t]\right))
p(y∣zt)≈p(y∣x0=D(E[z0∣zt]))
这个想法并不奏效,原因:encoder是多对一映射。采用(5)给出的密度梯度可以将
z
t
z_t
zt拉向这些潜伏时间
z
0
z_0
z0中的任何一个,可能在不同的方向上。
为了解决以上问题,提出gluing objective:
DPS简单扩展的理解
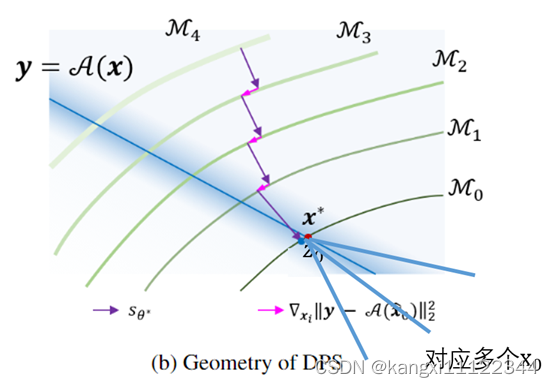
一个
z
0
z_0
z0 对应多个
x
0
x_0
x0
∇
z
t
log
p
(
y
∣
z
t
)
=
∇
z
t
p
(
y
∣
x
0
=
D
(
E
[
z
0
∣
z
t
]
)
)
⏟
D
P
S
v
a
n
i
l
l
a
e
x
t
e
n
s
i
o
n
+
γ
t
∇
z
t
∣
∣
E
[
z
0
∣
z
t
]
−
E
(
A
T
A
x
0
∗
+
(
I
−
A
T
A
)
D
(
E
[
z
0
∣
z
t
]
)
)
∣
∣
2
⏟
“grluing”” of
z
0
.
\begin{aligned} \nabla_{\boldsymbol{z}_{t}}\operatorname{log}p(\boldsymbol{y}|\boldsymbol{z}_{t})& =\underbrace{\nabla_{\boldsymbol{z}_t}p(\boldsymbol{y}|x_0=\mathcal{D}\left(\mathbb{E}[z_0|z_t]\right))}_{\mathrm{DPS~vanilla~extension}} \\ &+\gamma_t\underbrace{\nabla_{z_t}\left|\left|\mathbb{E}[z_0|z_t]-\mathcal{E}(\mathcal{A}^T\mathcal{A}x_0^*+(\boldsymbol{I}-\mathcal{A}^T\mathcal{A})\mathcal{D}(\mathbb{E}[z_0|z_t]))\right|\right|^2}_{\text{“grluing”” of }\boldsymbol{z}_0}. \end{aligned}
∇ztlogp(y∣zt)=DPS vanilla extension
∇ztp(y∣x0=D(E[z0∣zt]))+γt“grluing”” of z0
∇zt
E[z0∣zt]−E(ATAx0∗+(I−ATA)D(E[z0∣zt]))
2.

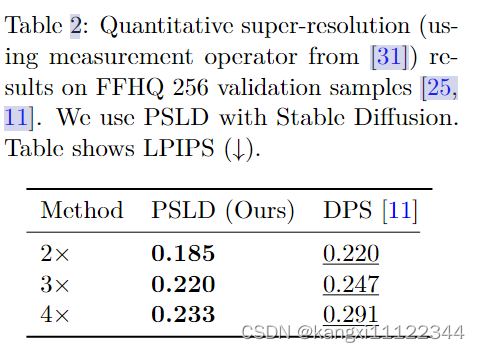
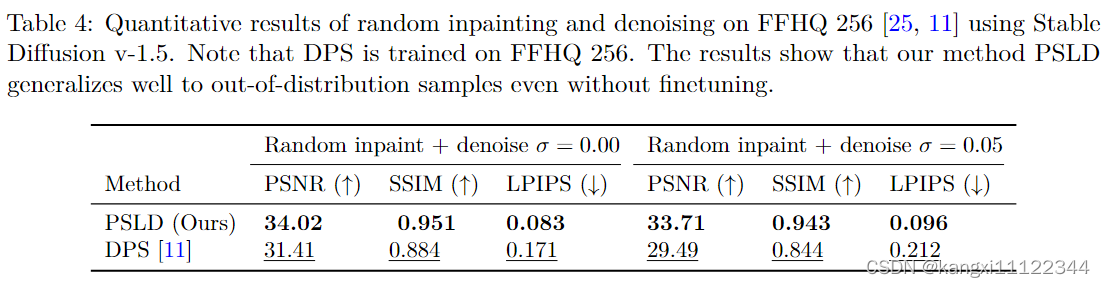
experiments




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









