







动机
在广告推荐领域,工程师可利用的初始输入非常多。如何从海量特征中制作高质量的特征,在当时成为一个迫切问题。虽然有经验的工程师可以手工制作高质量的特征,但是,在大数据规模的业务场景下,手工制作特征的可行性很低。能不能让网络自己从初始输入中学习到高质量的特征呢?这就是Deep Crossing解决的问题——完整地解决了从特征工程、稀疏向量稠密化、多层神经网络进行优化目标的整个流程。
特征的预处理
特征类别
论文中提到的数目繁多的特征中,主要有三种特征
- 数值型特征,如点击率,也称为计数型特征
- 样例特征,如广告计划、点击样例等,样例特征是多种特征的组合,需要进一步处理
- 类别型特征,如用户搜索词、广告关键词等,可以转换为One-hot和Multi-hot向量
细节
一、当类别过多,比如样例特征中的样例id通常有百万个,这时候进行分类就会有问题。Deep Crossing的做法是筛选出点击率Top10000的样例id,然后把剩余的其他id看作一个id。
二、上述提到的特征都是互相独立的单一特征,其实还存在另外一种特征:组合特征。组合特征虽然能反映两个特征之间的共性,但是组合特征的维度通常比较大。所以Deep Crossing没有采用组合特征,都是采用单一特征。
模型
Deep Crossing的模型主要有4个部分
- Embedding层
- Stacking层
- Multiple Residual层
- Scoring层
Embedding层
主要作用是稀疏的Multi-Hot或者One-Hot向量转化为稠密的特征向量。需要注意的是,Embedding层的参数极大影响了整个模型的参数量,这也是为什么不用组合特征的原因。
Embedding层的主要构成是一层线性网络层,通过映射将维度缩减,并使稀疏向量稠密化:
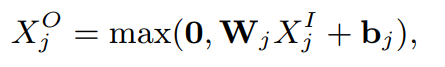
初始输入,维度小于等于256维的,不通过Embedding层,直接进入Stacking层。
Stacking层
Stacking层的作用比较简单,就是把特征进行拼接(concatenated)。
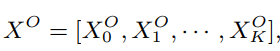
Multiple Residual层
这一层主要是借鉴了ResNet的思想,引入了残差连接,改善了深层网络在训练过程中的网络退化问题。并且使用了ReLU函数,防止梯度消失,函数表达式为:
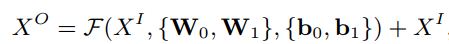
网络结构图为:

引入残差层的好处是网络层参数
F
(
⋅
)
F(·)
F(⋅)拟合的是输出与输出的残差
X
o
−
X
i
X_o-X_i
Xo−Xi,学习难度比较低,有利于防止网络退化。
Scoring层
这一层作为输出层,就是为了拟合优化目标而存在。
- CTR这类二分类问题,Scoring层采用的是逻辑回归模型。
- 图像分类问题,Scoring层采用softmax模型。
目标函数是:
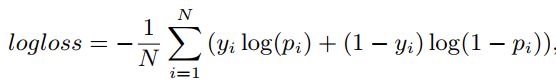
总结
以现在的眼光来看,Deep Crossing的模型架构非常简单,只是Embedding层 + 网络层的组合。但是,它提供了从特征工程到目标优化的整个流程。














 2434
2434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









