







介绍
深度学习未兴起时,传统矩阵分解(Matrix Factorization)是推荐领域中的一种经典方法,基本做法是:
- 把用户和商品映射到隐向量空间,用向量表示。
- 通过内积,来表示向量之间的相似性。
作者认为,通过内积来表示向量相似性的做法过于简单,有时候会出现错误,限制了模型的泛化能力。文中的一个例子:
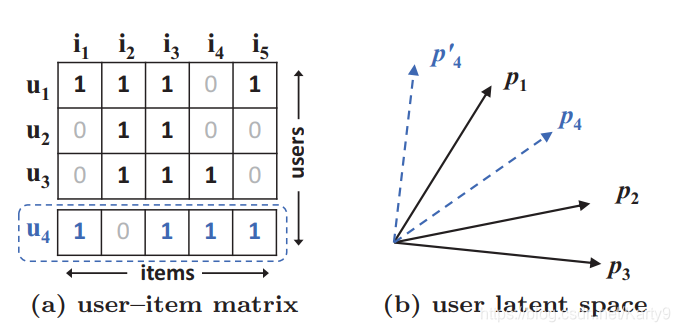
对于(a)中的交互矩阵,用
s
s
s表示用户之间的相似度,可以明显得看出
s
23
(
0.66
)
>
s
12
(
0.5
)
>
s
13
(
0.4
)
s_{23}(0.66) > s_{12}(0.5) > s_{13}(0.4)
s23(0.66)>s12(0.5)>s13(0.4)
这也体现在(b)中
p
1
、
p
2
、
p
3
p_1、p_2、p_3
p1、p2、p3的夹角大小。当你在
(
a
)
(a)
(a)中把
u
4
u_4
u4考虑进去时,会得到:
s
41
(
0.6
)
>
s
43
(
0.4
)
>
s
42
(
0.2
)
s_{41}(0.6) > s_{43}(0.4) > s_{42}(0.2)
s41(0.6)>s43(0.4)>s42(0.2)
这时候你会发现, u 4 u_4 u4和 u 1 u_1 u1的距离最近, u 4 u_4 u4和 u 3 u_3 u3次之, u 4 u_4 u4和 u 2 u_2 u2的距离最远,但是反映在 ( b ) (b) (b)中,不管怎么画 p 4 p_4 p4(虚线), p 4 p_4 p4总是与 p 2 p_2 p2更接近。这就导致在模型学习的过程中,造成较大的loss,增加学习难度。
本质原因呢?就是Matrix Factorization的setting过于简单,无法处理稍微复杂的场景。NCF的出发点就是引入深层神经网络(DNNs),以解决上述问题。
在当时的时代背景下,Deep Learning正在兴起,DNNs已经在CV、NLP等领域取得飞跃性进展。所以作者指出,应该把DNNs引入推荐领域,让DNNs来自动完成特征交叉,代替传统的矩阵分解(MF)方法。
所以,本篇文章的主要贡献是用DNNs搭建了超越传统MF的模型——Neural Collaborative Filtering(NCF)。并且作者证明,传统矩阵分解可以看作NCF的一种特例。
补充知识
- 隐式反馈:购买商品,点击商品,观看视频等,没有显性地表达用户的喜好,存在噪声。
- 显式反馈:对商品的评分、评论等。
可以看出,隐式反馈的建模难度更大,因为用户的行为存在一定的随机性,导致隐式反馈注定会存在噪声。NCF专注于解决推荐领域中的隐式反馈建模。
解决方案
作者提出了两个模型,分别是:
-
用DNNs实现的通用协同过滤模型(Neural collaborative filtering framework)
-
用DNNs实现的广义矩阵分解模型(Neural matrix factorization model)
Neural collaborative filtering framework
这个模型和传统协同过滤模型的唯一区别就是使用DNNs来做特征交叉,以替代传统的内积操作。
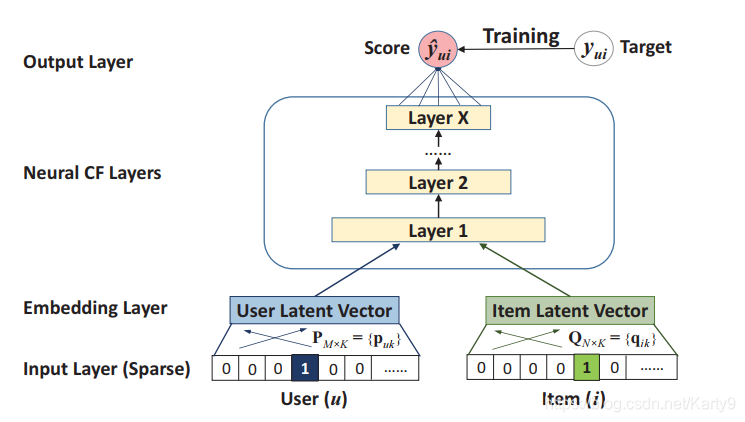
为了模型阐述的简便,Input Layer中输入的是User和Item的ID生成的One-Hot向量。在实际业务场景中,还可以根据其他信息来生成特征向量,比如文章中列举的三种特征:
- context-aware
- content-based
- neighbor-based
在初始化时加入上述向量,还可以有效缓解冷启动问题。
Embedding Layer的主要作用是把稀疏向量稠密化,以输入后续的Neural CF Layers。
Neural CF Layers实际就是多个网络映射层,作用是把多维向量映射到分数(score)。最后一层Layer X的维度决定了模型的表达能力。每一层网络都可以学到用户-商品交互矩阵的一个特定语义。
通过Neural CF Layers,得到的是预测的分数
y
^
u
i
\hat{y}_{ui}
y^ui,怎么去和标签
y
u
i
y_{ui}
yui进行优化呢?这里选择的是直接优化
y
^
u
i
\hat{y}_{ui}
y^ui和
y
u
i
y_{ui}
yui之间的差值。按文中说法,使用Point-wise loss。考虑到推荐场景中标签通常是0或1,如果看作回归问题,用平方损失优化是不太合理的。所以这里使用交叉熵损失(Cross Entropy):
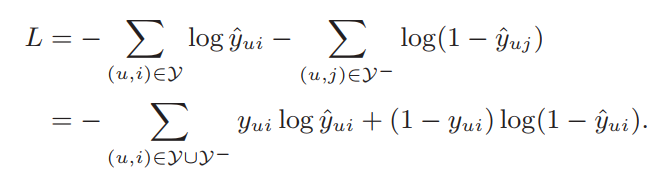
对于负样本
γ
−
γ-
γ−,我们通过负采样比例(sampling ratio)来控制负样本的个数。
Neural matrix factorization model
作者首先提出了一个通用的矩阵分解框架(GMF),然后他做了三件事:
- 证明了传统的矩阵分解是GMF的特例
- 给GMF加入更多非线性操作,可以达到改善传统矩阵分解(MF)的目的
- 引入MLP,加入更多非线性,得到最终模型。
GMF
GMF表达式如下:
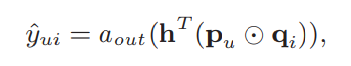
a
o
u
t
a_{out}
aout是激活函数,
h
T
h^T
hT是映射向量,
⊙
⊙
⊙表示点对点乘积(element-wise product)。
作者指出,当 h T h^T hT为全1向量, a o u t a_{out} aout是恒等映射时,上述式子就等价于传统的矩阵分解(MF)。因为,如果 h T h^T hT为全1向量, h T ( p u ⊙ q i ) h^T(p_u⊙q_i) hT(pu⊙qi)实质上等于 p u p_u pu和 q i q_i qi的内积, a o u t a_{out} aout又是恒等映射,向量通过 a o u t a_{out} aout没有发生改变。
接下来,我们可以让 h T h^T hT不再受限于全1向量,而是可以学习的向量; a o u t a_{out} aout不再是恒等映射,而是改成了激活函数。这样,我们就得到了作者提出的GMF,比传统的矩阵分解(MF)模型表达能力更强。
a o u t a_{out} aout的选择,文中使用了 S i g m o i d Sigmoid Sigmoid函数,目的是让分数限制在(0,1)之间。
MLP
上面我们是通过在用户向量 p u p_u pu和商品向量 q i q_i qi的互操作上引入更多的非线性,让网络自动完成特征交叉。其实还有一种通用的做法,在深度学习领域也比较流行,就是不需要定义任何的互操作,而是把特征学习完全交给网络层。
文中也采用了这种框架作为GMF的补充,首先把用户向量 p u p_u pu和商品向量 q i q_i qi拼接在一起,然后通过多个网络层去自动地学习特征交叉。
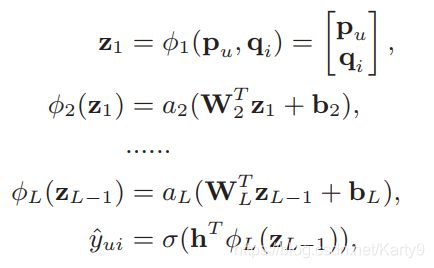
激活函数选择了RELU,原因有二:
- Sigmoid、Tanh都有梯度消失的问题,而ReLU没有
- ReLU更容易使得参数变得稀疏,符合推荐场景的稀疏性。
最终模型
通过把GMF和MLP进行合并,就得到了我们最终的模型(NCF):
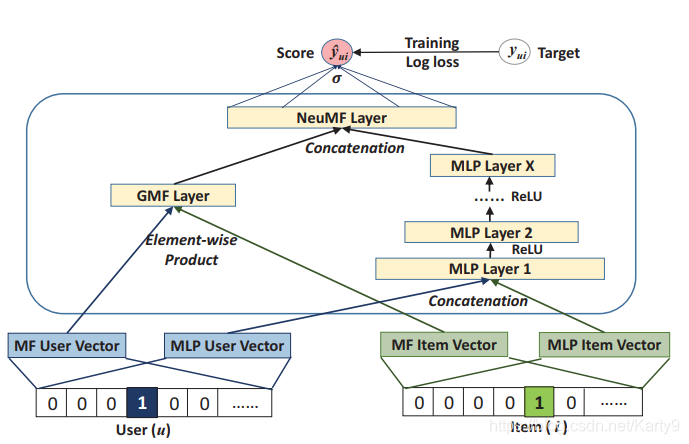
一个值得商榷的点是:GMF和MLP到底应不应该共享同一套Embedding?
这里作者选择了不共享。两者分别训练自己的用户Embedding和商品Embedding,并且给出了解释:
- 使用同一套Embedding会对Embedding size的设置更为严格,要同时找到对于GMF和MLP来说最优的Embedding size比较困难,这无疑会削弱网络的学习能力。
这里说一下我的理解,其实GMF和MLP可以看作是特征学习的两条路径,通过这两条路径所更新的Embedding是有区别的,所以,为了保留这两者的差异性,把它们分隔开是符合常理的。如果两者共享一套Embedding,那么无疑会抵消两者的差异性。
预训练
这里作者还提出了预训练的方法,其实从实验上看提升也不是很大。预训练的策略也很简单,让GMF和MLP两者单独训练,唯一的变动就是在输出层上,设置了一个超参数
α
α
α,来控制最终的输出向量的组成:
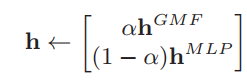
总结
NCF使用DNNs验证并扩展了传统的协同过滤模型,取得了非常好的效果。它的主要思想:
- 引入更多样化的向量互操作
- 用网络层来自动完成特征交叉
也成为后续推荐领域模型发展的潮流。














 1604
1604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









