










爬取猫眼电影榜单信息(翻页)
一. 获取url及headers
首先进入猫眼电影首页: 猫眼电影
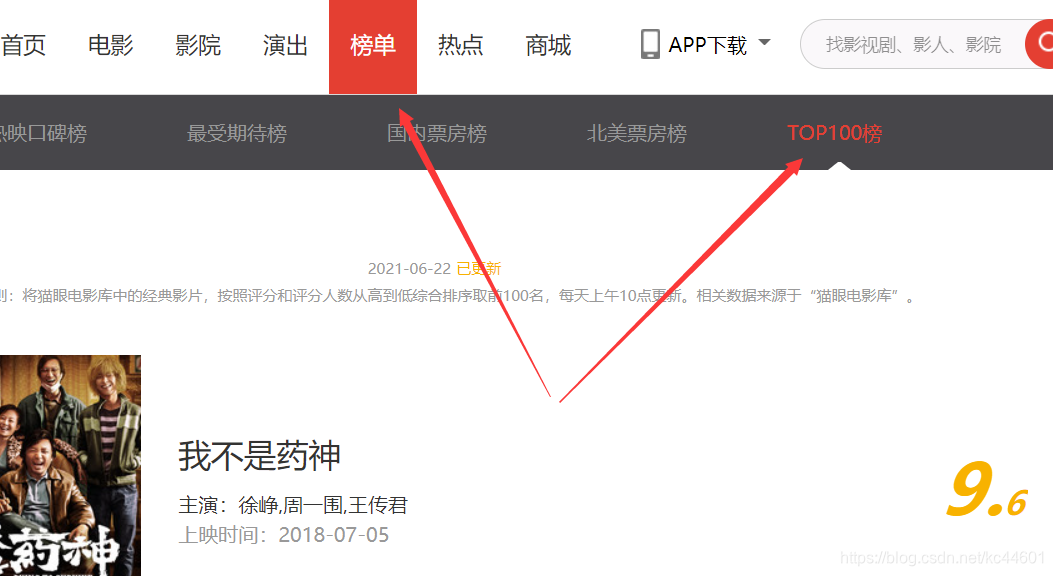
之后点击菜单栏的 榜单 并在下面选择 TOP100榜
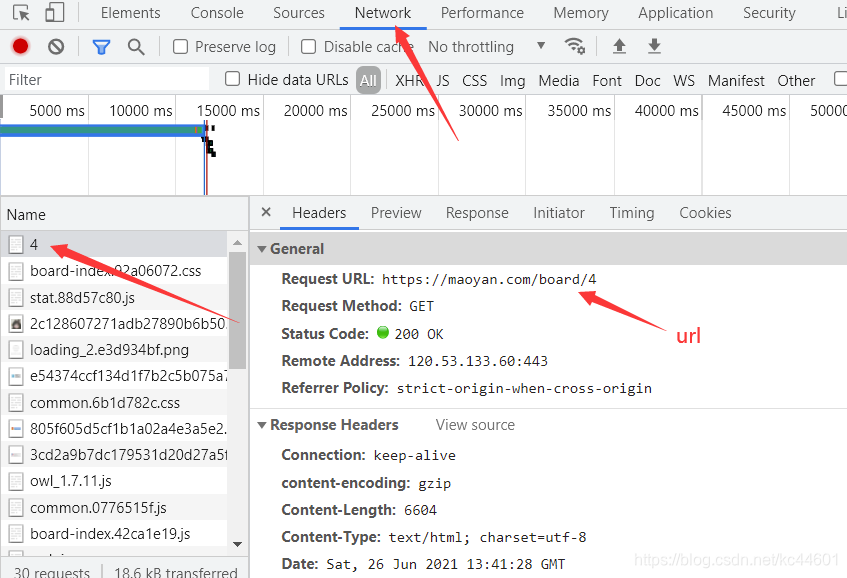
接着右击检查并刷新界面,在Network中找到4的加载文件,并双击打开获取右侧的url以及其他的headers信息
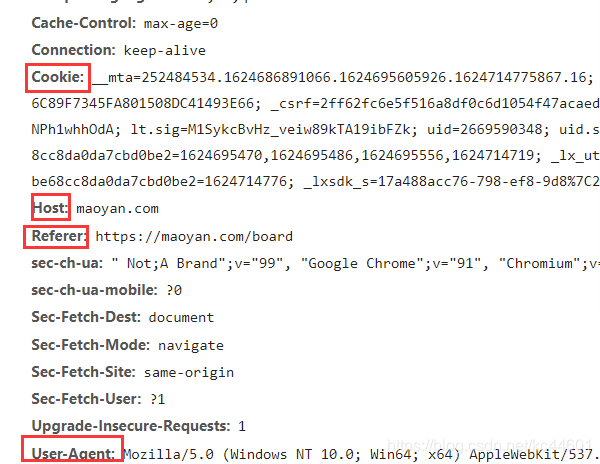
# 获取网页响应内容
def get_html(url):
# 不能证明你是一个完整的浏览器用户
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome'
'/91.0.4472.114 Safari/537.36',
'Cookie': '__mta=252484534.1624686891066.1624687766500.1624687767500.10; uuid_n_v=v1; uuid=051E3230D643'
'11EBAD8677F166774E1C31527601D00A4827A818F22ED6663F50; _csrf=497ac6cb2543d3c99f7fd59acd4badb44'
'51d9e25e35637501cb8be564a0ce589; _lxsdk_cuid=17a46e28f16c8-045656e4dec5c6-6373267-144000-17a46'
'e28f16c8; _lxsdk=051E3230D64311EBAD8677F166774E1C31527601D00A4827A818F22ED6663F50; _lx_utm=utm_'
'source%3DBaidu%26utm_medium%3Dorganic; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1624686891,162468'
'7015,1624687757; __mta=252484534.1624686891066.1624687746239.1624687759636.7; Hm_lpvt_703e94591e'
'87be68cc8da0da7cbd0be2=1624687767; _lxsdk_s=17a46e28f16-29d-098-66d%7C%7C36',
'Host': 'maoyan.com',
'Referer': 'https://maoyan.com/board/2',
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
print("请求成功")
return response.text
return None
二. 利用正则获取电影信息
首先我们点击Elements查看网页信息,并在其中找到相对应的电影信息
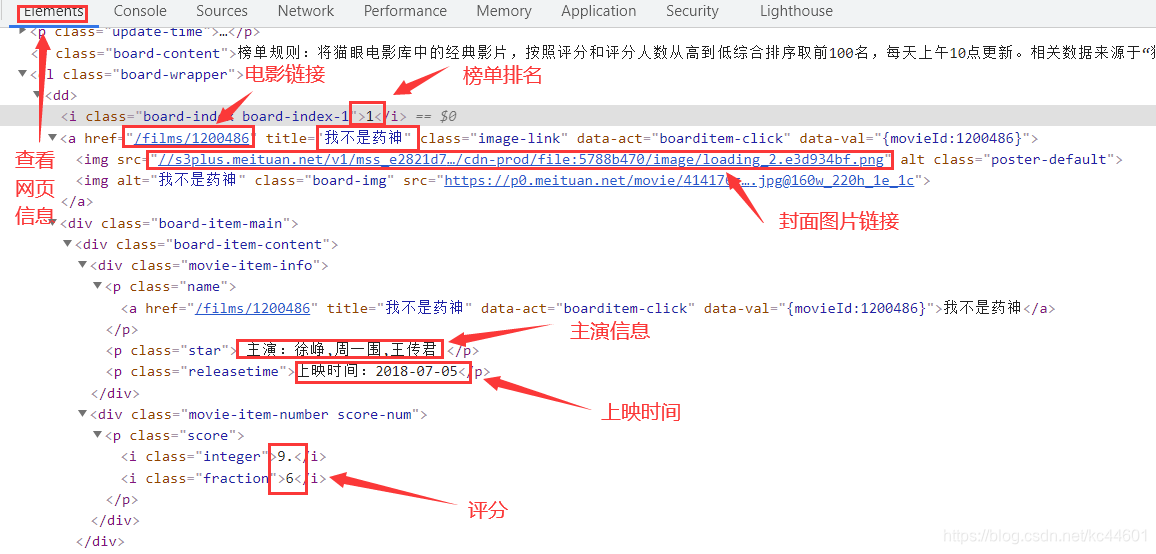
之后利用正则分组匹配匹配出各个需要的信息
z = '<dd.*?board-index.*?">(.*?)</i>.*?href="(.*?)".*?title="(.*?)".*?>.*?<img.*?data-src="(.*?)".*?alt.*?/>' \
'.*?<div.*?class="movie-item-info">.*?<p.*?class="star">(.*?)</p>.*?class="releasetime">(.*?)</p>' \
'.*?"integer">(.*?)</i>.*?"fraction">(.*?)</i>.*?</dd>'
之后在把各个信息提取出来
def parse_html():
z = '<dd.*?board-index.*?">(.*?)</i>.*?href="(.*?)".*?title="(.*?)".*?>.*?<img.*?data-src="(.*?)".*?alt.*?/>' \
'.*?<div.*?class="movie-item-info">.*?<p.*?class="star">(.*?)</p>.*?class="releasetime">(.*?)</p>' \
'.*?"integer">(.*?)</i>.*?"fraction">(.*?)</i>.*?</dd>'
html = get_html(url.format(i * 10)) # 此处为下面的翻页处理
result = re.findall(z, html, re.S)
# print(result)
for i in result:
movies_ranking = i[0] # 电影排名
movies_link = "https://maoyan.com" + i[1] # 电影链接
movies_name = i[2] # 电影名称
img_url = i[3].split('@')[0] # 图片链接
name = i[4].strip() # 主演信息
movies_time = i[5] # 上映时间
movies_score = i[6] + i[7] # 电影评分
三. 处理翻页部分
首先这里我们选出五页的url进行比对分析
https://maoyan.com/board/4? # 第一页
https://maoyan.com/board/4?offset=10 # 第二页
https://maoyan.com/board/4?offset=20 # 第三页
https://maoyan.com/board/4?offset=30 # 第四页
https://maoyan.com/board/4?offset=40 # 第五页
通过比较五个页面的url我们可以发现在参数offset值上从0开始每页递增10,虽然第一页没有显示参数,但是将参数添加进去后在打开网页,我们发现依旧是第一页,所以规律成立
所以在构建url时我们将参数部分用花括号{}先代替,之后再循环加入
url = 'https://maoyan.com/board/4?offset={}'
for i in range(10):
print("正在爬取第{}页".format(i + 1)) # 提示信息
...
html = get_html(url.format(i * 10)) # 翻页处理
四. 数据的保存
这里我们将数据保存到excel里面
from openpyxl import workbook
wb = workbook.Workbook() # 创建excel对象
ws = wb.active # 激活当前excel对象
ws.append(['排名', '电影链接', '电影名', '图片链接', '主演信息', '上映时间', '评分'])
...
wb.save('猫眼.xlsx')
五.全部代码及效果展示
import requests
import re
from openpyxl import workbook
wb = workbook.Workbook() # 创建excel对象
ws = wb.active # 激活当前excel对象
ws.append(['排名', '电影链接', '电影名', '图片链接', '主演信息', '上映时间', '评分'])
def get_html(url):
# 不能证明你是一个完整的浏览器用户
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome'
'/91.0.4472.114 Safari/537.36',
'Cookie': '__mta=252484534.1624686891066.1624687766500.1624687767500.10; uuid_n_v=v1; uuid=051E3230D643'
'11EBAD8677F166774E1C31527601D00A4827A818F22ED6663F50; _csrf=497ac6cb2543d3c99f7fd59acd4badb44'
'51d9e25e35637501cb8be564a0ce589; _lxsdk_cuid=17a46e28f16c8-045656e4dec5c6-6373267-144000-17a46'
'e28f16c8; _lxsdk=051E3230D64311EBAD8677F166774E1C31527601D00A4827A818F22ED6663F50; _lx_utm=utm_'
'source%3DBaidu%26utm_medium%3Dorganic; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1624686891,162468'
'7015,1624687757; __mta=252484534.1624686891066.1624687746239.1624687759636.7; Hm_lpvt_703e94591e'
'87be68cc8da0da7cbd0be2=1624687767; _lxsdk_s=17a46e28f16-29d-098-66d%7C%7C36',
'Host': 'maoyan.com',
'Referer': 'https://maoyan.com/board/2',
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
print("请求成功")
return response.text
return None
def parse_html():
for i in range(10):
print("正在爬取第{}页".format(i + 1))
z = '<dd.*?board-index.*?">(.*?)</i>.*?href="(.*?)".*?title="(.*?)".*?>.*?<img.*?data-src="(.*?)".*?alt.*?/>' \
'.*?<div.*?class="movie-item-info">.*?<p.*?class="star">(.*?)</p>.*?class="releasetime">(.*?)</p>' \
'.*?"integer">(.*?)</i>.*?"fraction">(.*?)</i>.*?</dd>'
html = get_html(url.format(i * 10))
result = re.findall(z, html, re.S)
# print(result)
for i in result:
movies_ranking = i[0] # 电影排名
movies_link = "https://maoyan.com" + i[1] # 电影链接
movies_name = i[2] # 电影名称
img_url = i[3].split('@')[0] # 图片链接
name = i[4].strip() # 主演信息
movies_time = i[5] # 上映时间
movies_score = i[6] + i[7] # 电影评分
print("电影排名:" + movies_ranking)
print("电影链接:" + movies_link)
print("电影名称:" + movies_name)
print("图片链接:" + img_url)
print("主演信息:" + name)
print("上映时间:" + movies_time)
print("电影评分:" + movies_score)
my_list = [movies_ranking, movies_link, movies_name, img_url, name, movies_time, movies_score]
ws.append(my_list)
if __name__ == '__main__':
url = 'https://maoyan.com/board/4?offset={}'
parse_html()
wb.save('猫眼.xlsx')
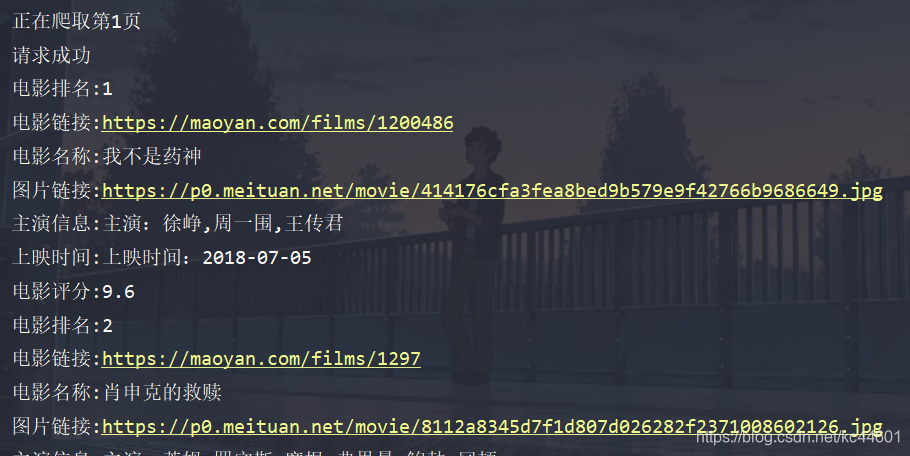
结果展示:















 623
623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









