









HA (高可用)
一、Hadoop 2.0的新特性

三、HDFS的高可用架构的搭建
(一) 集群的规划

(二)创建虚拟机

(三)编辑虚拟机配置



(四)安装centos7.9
此过程可见 Hadoop高手之路–01–集群搭建
(五)配置虚拟机
1、配置网络

2、配置主机名

3、免密登录


4.创建目录

(六)克隆虚拟机

(七)配置克隆的虚拟机
1、配置网络


2、配置主机名


(八)配置各虚拟机ip地址和主机之间的映射关系
1、centos下

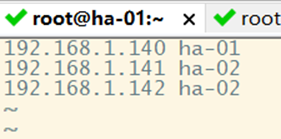
2、分发/etc/hosts


3、windows下




(九)虚拟机之间的免密登录



(十)关闭防火墙
三台虚拟机都需要关闭防火墙

(十一)安装小工具Irzsz和wget


(十二)安装配置jdk
1、解压

2、配置环境变量


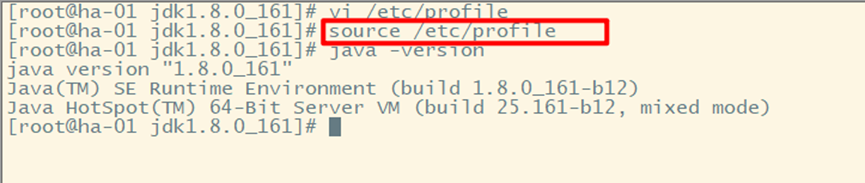
3.分发jdk到其他节点


4.分发环境变量配置文件

5、使环境变量起作用



6、测试java是否安装配置成功


(十三)安装配置Hadoop
1、下载上传Hadoop安装包
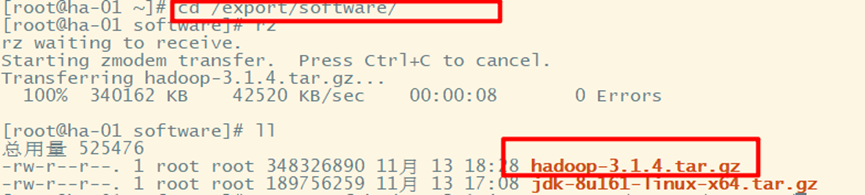
2、解压

3、配置环境变量

使配置文件起作用

验证是否配置成功

4、HA集群配置


(1)core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!--指定HDFS的nameservice名称 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!--指定hadoop的临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop/tmp</value>
</property>
<!--指定zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>ha-01:2181,ha-02:2181,ha-03:2181</value>
</property>
</configuration>

(2)hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!--设置副本的个数 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--指定name目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/export/data/hadoop/name</value>
</property>
<!--指定data目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/export/data/hadoop/data</value>
</property>
<!--开启webHDFS-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--指定nameservice为ns1-->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!--指定ns1下面有两个namenode,nn1和nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!--指定nn1的rpc地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>ha-01:9000</value>
</property>
<!--指定nn1的http地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>ha-01:50070</value>
</property>
<!--指定nn2的rpc地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>ha-02:9000</value>
</property>
<!--指定nn2的http地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>ha-02:50070</value>
</property>
<!--指定nm的元数据在journalnode上的存放位置-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://ha-01:8485;ha-02:8485;ha-03:8485/ns1</value>
</property>
<!--指定nn2的http地址 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/export/data/hadoop/journaldata</value>
</property>
<!--开启namenode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--配置namenode失败自动切换的实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--配置隔离机制的方法-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!--开启sshfence隔离的免登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--开启sshfence隔离的超时时间-->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>

(3)Mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>

(4)Yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- Site specific YARN configuration properties -->
<!--启用resourcemanager ha-->
<!--是否开启RM ha,默认是开启的-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>ha-01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>ha-02</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>ha-01:2181,ha-02:2181,ha-03:2181</value>
</property>
<!--启用自动恢复,当任务进行一半,rm坏掉,就要启动自动恢复,默认是false-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群,默认是存放在FileSystem里面。-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>

(5)Workers
(6)Hadoop-env.sh

5.分发Hadoop


6.使环境变量起作用并检验是否成功
分发配置文件

使配置文件起作用



验证是否配置成功



(十四)安装配置zookeeper
1、上传安装包

2、解压

3、配置环境变量


4、配置zookeeper

5、创建myid文件


6、分发zookeeper


7、分发profile

8、使环境变量起作用



9.在其他节点创建myid文件,内容分别为2、3


(十五)启动Hadoop高可用HA集群
1、启动zookeeper



2、启动JournalNode,用于监控管理日志


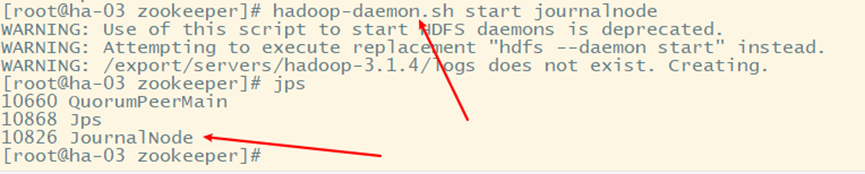
3、=在ha-01上格式化namenode,并分到到ha-02=
注意这一步一定要在ha-01上操作
注意这一步一定要在ha-01上操作
注意这一步一定要在ha-01上操作


分发到ha-02

4、在ha-01上格式化ZKFC

5、启动Hadoop

出现报错,修改hadoop-env.sh
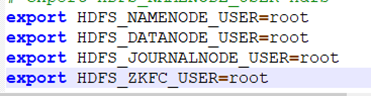
修改后再次启动



6、启动yarn

出现错误,修改hadoop-env.sh文件

修改后再次启动




在ha-02上杀掉rm进程,模拟服务器宕机

查看yarn运行状态


(十六)webui查看状态





杀死ha-01的namenode进程,模拟服务器挂机

查看集群工作状态


可以看到ha-02自动成为激活状态,集群工作正常















 872
872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









