







很可惜由于自己的拖延,没赶上task03的datawhale打卡,导致任务已经终止了。不过还是继续把西瓜书读完吧(悲)
4.0信息熵
看了哔站up“致敬大神”的讲解,感觉醍醐灌顶。
4.0.1概念
熵是用来量化不确定性的,例如买西瓜时一个瓜的口感往往好坏参半,这种不确定性就是“熵”。而信息就是用来削弱这种不确定性的,其作用包括a.调整概率b.排除干扰
调整概率
如果在买西瓜时拍了拍,声音清脆,那么好瓜的概率由好坏参半的50%提升到了70%.
排除干扰
根据经验,一个西瓜是否是好瓜与这个西瓜是否包装精美,西瓜店的位置无关,那么就可以排除这些无关紧要的信息,这些无关紧要的信息就称为噪音,而数据中就包括信息和噪音。
4.0.2熵的量化
用抛硬币的不确定性来量化。
一个事情发生概率为1/8,那么就相当于抛3枚硬币,熵就是3bit.
等概率均匀分布
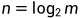
n表示熵,m表示发生的情况数.
如果有10种等可能的情况,那么不确定性就是相当于抛了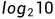 枚硬币,亦即熵为.
枚硬币,亦即熵为.
一般分布
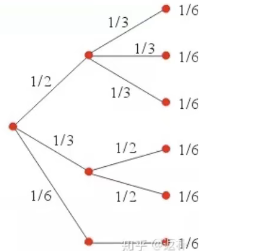
假设三种情况A、B、C发生的概率分别是1/2,1/3,1/6其概率不相同.那么假设A、B、C是由几个概率为1/6的基本事件组成的,那么熵就是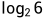 。在A情况下三种情况被归为了一种,相当于减少了
。在A情况下三种情况被归为了一种,相当于减少了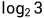 ,即
,即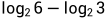 ,再乘上权重1/2,就是
,再乘上权重1/2,就是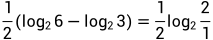 .B和C同理,分别是
.B和C同理,分别是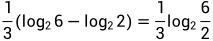 和
和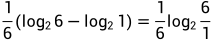
加起来是
4.0.3信息的量化
得知信息前后,熵的差额,就是信息的量(信息增益)
举例,小明有ABCD四个选项,若信息为“C选项有50%的概率为正确选项,50%的概率为错误选项”,则ABCD发生的概率由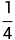 变为了
变为了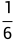
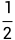 。则得知信息前熵为
。则得知信息前熵为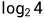 ,得知信息后熵为
,得知信息后熵为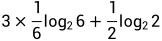
4.1 ID3算法
ID3算法就是根据信息增益构建决策树:
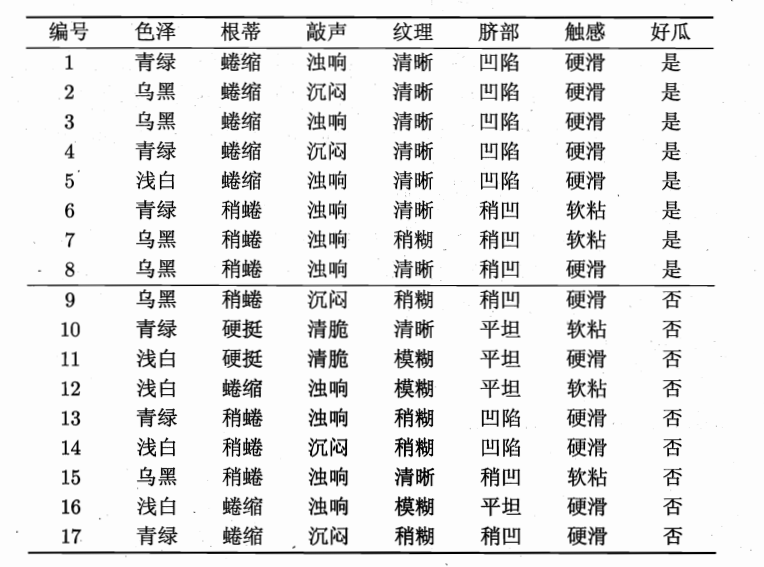
首先根据正反例的占比,计算熵为0.998,然后分别按色泽、根蒂等属性计算信息增益,选择信息增益最大的作为分支属性,建立这样的决策树:
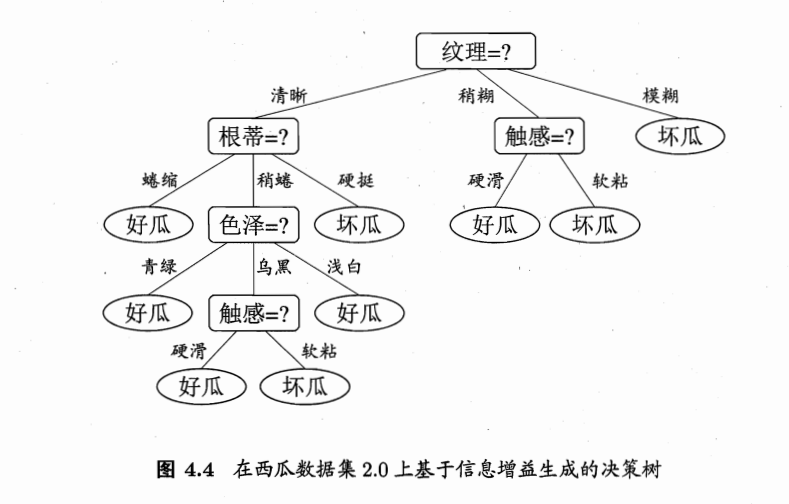
4.2 C4.5算法
在ID3的基础上,引入信息增益率的概念,定义如下:
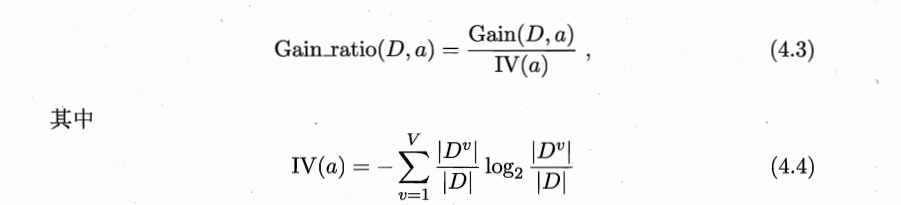
在选择最优属性时,先根据信息增益确定范围(例如前五名的属性),再从中选择增益率最高的。
分裂信息项阻碍选择值为均匀分布的属性。例如,考虑一个含有n个样例的集合被属性A彻底分割(译注:分成n组,即一个样例一组)。这时分裂信息的值为log2n。相反,一个布尔属性B分割同样的n个实例,如果恰好平分两半,那么分裂信息是1。如果属性A和B产生同样的信息增益,那么根据增益比率度量,明显B会得分更高。
4.3 CART(classification and regression tree)
CART决策树使用基尼指数划分属性:
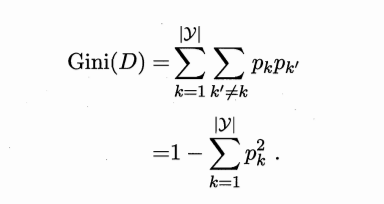
例如按照瓜的好坏进行分类,那么就有8/17的好瓜和9/17的坏瓜,基尼指数就是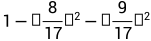 ,样本被分割得越均匀(接近1:1),基尼指数越小,说明纯度越高。
,样本被分割得越均匀(接近1:1),基尼指数越小,说明纯度越高。
4.4剪枝
在一棵决策树生成后,容易出现过拟合现象,剪枝就是减掉不必要的分支,使其具备更好的泛化性能。
4.4.1预剪枝
预剪枝就是自根节点开始,每生成一个分支后,就检测该分支是否能够提高模型在验证集上预测的准确率,能就不剪枝,不能就剪枝。
这样做的优点是能够剪去不必要的分支,解决过拟合问题。缺点是容易欠拟合,理由是当前分支可能不会提高准确率,但是该分支的下级分支还有可能会提高准确率,却因剪枝没有机会再分支了。
4.4.2后剪枝
在生成了一棵完整的决策树之后,再自底向上进行剪枝。复杂度更高,但效果更好。















 183
183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









