







FPGA vs. ASIC
专用芯片ASIC的开发流程是:设计、验证、流片、封装、测试;
而FPGA已经是做好的芯片,所以不需要流片、封装、测试。这样,可以至少节省四个月的时间。
另外ASIC还有可能多次流片才能成功,同步的软件开发也需要芯片做好才能完成大部分功能,这些也是时间成本。
在量小的时候,FPGA的成本低,量大了之后,ASIC的成本低。
FPGA的功耗比ASIC高,因为有很多多余的逻辑,不过比CPU省电,毕竟CPU的多余逻辑更多。
相比ASIC,FPGA的调试比较方便,可以直接烧到FPGA执行,也可以用调试工具抓取芯片里面的信号查看状态。
FPGA需要跑多快?
跟Intel CPU相比,FPGA的主频差一个数量级,一般FPGA芯片时钟频率300MHz左右,而Intel CPU可以到3GHz,就是说CPU 1秒能做30亿次计算,而FPGA只能做3亿次,差了10倍。
另外FPGA用作可重构计算是来加速CPU的,如果和CPU跑一样快就没意思了,所以一般要比CPU快5倍才行。
FPGA的开发周期是比较久的,1年甚至2年很正常,在这个过程中,CPU上的软件算法还在不断升级,所以有可能FPGA算法设计的比CPU快,等开发完,却发现CPU上的软件算法快速迭代,已经超过FPGA算法了。这种事还是比较常见的,不只是软件算法升级,CPU自己也会升级,这些都有可能让FPGA加速器做了无用功。比如用FPGA做一个数据压缩卡,可是CPU可能就自己带了一个数据压缩功能,成本还比FPGA卡低,开发FPGA的人白干一场。阿呆以前就遇到过这种问题,在FPGA里面做了一个AI算法,架构设计的牛逼了点,大家又干的慢了点,两年完工,再去跟做AI的人一交流,发现这套算法已经是旧的框架了。。。
所以,正常来说,FPGA算法加速性能设计的时候要比CPU快5-10倍才能保证最终做出来的产品是可以实现硬件加速的目标。
影响FPGA计算性能的几大因素
1. 数据并行性
对FPGA计算来说,同时处理大量的数据,同时数据之间没有相互依赖是最好的。这样,可以有几百上千个并行计算单元独立处理几百上千个数据,如果数据之间有依赖,比如有很多的if else,就并发不起来,A必须要等B完成才能执行。就跟步骑兵混合军团出征,如果将军下令大家要同步进军,步兵要和骑兵一起冲,骑兵不能跑太快,要等步兵一起走,那这个仗就没法打了,只能被敌人包饺子。
2. 数据大小和计算复杂度
FPGA并行计算是很多个计算并行执行,如果每个计算单元要处理的数据太多,同时计算逻辑太复杂,那么占用的FPGA计算资源就变多了,这样总的并行单元数量相应减少,性能下降。而且,老司机都知道,计算逻辑太复杂,在电路上消耗的时间变多,还会导致每个模块的延迟变长,这样时钟频率也会下降,也会影响到性能。
3. 流水线
计算复杂的时候,延迟会变长,如果要求计算任务在一个时钟周期里完成,那么时钟周期就变长了,相应的频率降低,性能下降。所以为了提高时钟频率,FPGA会采用流水线技术,把复杂的计算分解成几段,放到几个时钟周期里完成。这样做的后果就是,计算需要的时间变长了,但是总的性能却提高了。为什么?阿呆来举例说明。
蛋蛋本来1个小时造1个玩具,一天8小时造8个。后来造玩具改成蛋蛋、小蛋蛋、蛋妈三个人干,任务分解成三段,每人半小时,1个半小时才能造出玩具,看起来造玩具的时间变长了。可是三个人一天工作总时间3*8=24小时,一天生产24/1.5=16个玩具,产量翻番了。
这就叫三个臭皮匠,赛过一个诸葛亮。


4. 静态控制逻辑
我们写软件程序的时候,习惯了给函数很多参数作为条件,根据参数内容执行函数的操作。FPGA做计算就不希望靠参数内容确定怎么计算,而是希望一开始就定好。比如在软件里面,算个位数的平方和二位数的平方差不多,可是到FPGA里面,个位数需要的计算资源少,二位数占用的多,一个计算单元要同时支持个位数和二位数平方计算就会很占资源,最好是一开始就确定好算哪一种,不要动态确定。
存储和计算的关系
1. 数据密集型和计算密集型
我们的计算有数据密集型和计算密集型两种,如果计算的次数多,就是计算密集型,反之,就是IO密集型。比如n×n矩阵乘法,每个数据读和写都认为是一次IO,读两个矩阵的数据,写入结果矩阵的数据,需要3n2次IO,而计算的次数是n3,所以是计算密集型。但是n×n矩阵加法,同样需要3n2次IO,不过计算的的次数只有n2,属于IO密集型。
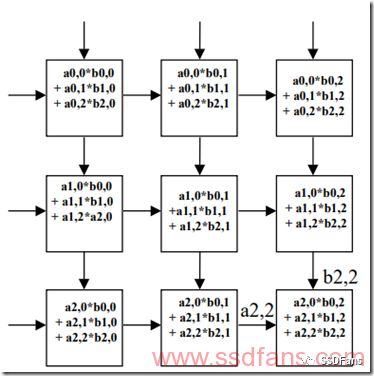
2. 脉动阵列结构
AI的计算往往涉及到矩阵乘法和向量乘法等,所以IO这边的存储往往成了性能瓶颈,我们经常会看到,为了解决“存储墙”问题,AI芯片里面(例如Google TPU)会采用脉动阵列结构,尽量做到IO进来的数据重用,把IO密集型转化为计算密集型。如下图,左侧和上方都有数据进来,就跟心跳一样,不断有血液流进来,但是内部有计算阵列,不会浪费中间产生的数据,所有的计算单元都在并行工作,产生可怕的计算性能。
3. AI计算的“存储墙”问题
AI计算需要读大量的数据,如果依赖于AI芯片外部的存储器,比如DDR DRAM等,延迟和性能都会受到影响,DDR占用管脚多,能耗高,只能接一两个,最多4个,没办法满足很多并行计算单元的IO需求。所以,需要预先在芯片里面放置大量的SRAM和寄存器等作为片内高速缓存,通过很多个小容量片内RAM,实现大量的并发IO,提供给成百上千个并行计算引擎。
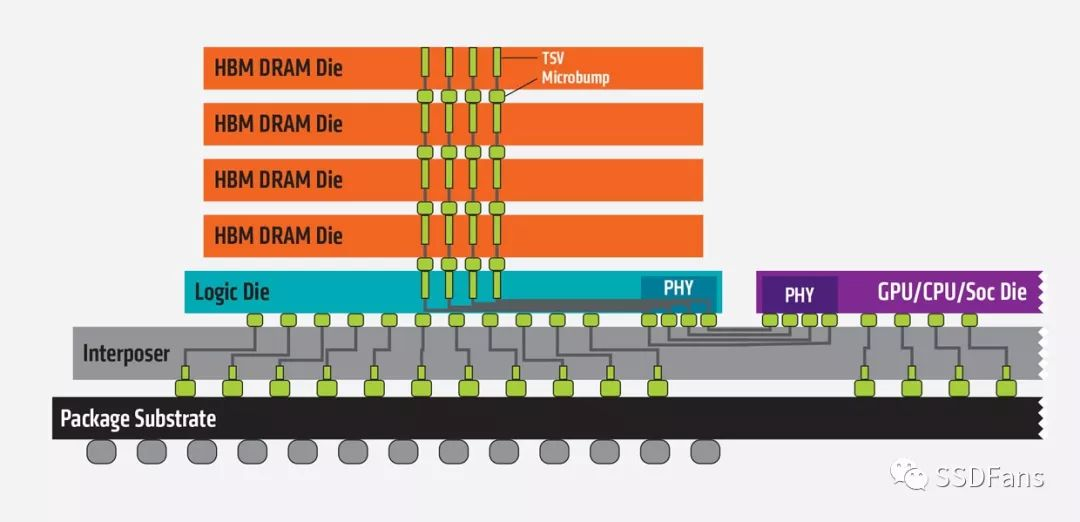
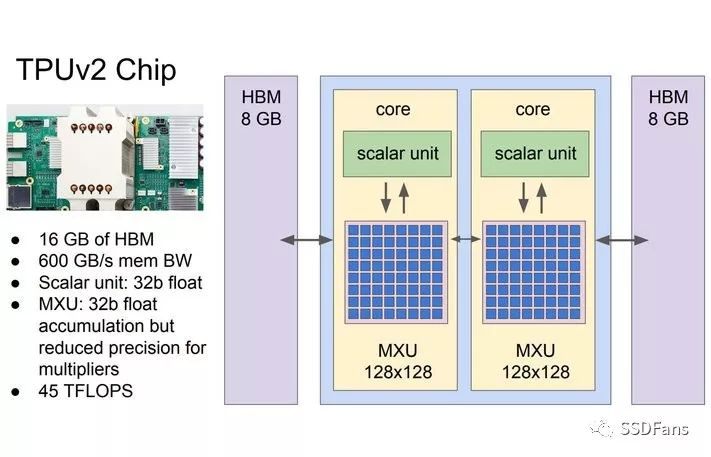
为了解决存储墙问题,有两种路径:
(1) 基于HBM(High-bandwidth Memory)技术的3D堆叠,很多存储芯片和AI芯片封装在一起。AMD和NVIDIA的Vega和Volta GPU都集成了16GB的HBM2。而其他公司的一些最新的AI芯片架构,也都集成了3D堆叠存储,比如Intel Nervana也用3D HBM,而Wave Computing用的是美光(Micron)的HMC,另外一种形式的3D堆叠存储。Google的TPU 2.0也是每个核用了8GB的HBM。
(2) 计算存储一体化。用RRAM等新型掉电不丢失数据的存储介质和AI计算引擎集成在一颗芯片内,数据一直存在AI芯片里面,不需要从外部加载,减少了数据搬移,效率和性能都很高。例如加州大学谢源教授团队把神经网络计算和RRAM放到一颗芯片里面,功耗可以降低20倍,速度提高50倍。IBM在《自然》也发了一篇文章,宣布在相变存储器上实现了同样的针对AI应用的神经网络计算。
我们用FPGA做计算,有一个很重要的概念,叫做Domain Specific Computing,是UCLA的丛京生教授提出来的,就是针对某一个领域的计算任务,在硬件算法上做特殊优化,主要是性能提升和算法压缩,实现高性能、低成本。
FPGA做计算第一板斧:化动为静
前面说过,FPGA如果按照某个参数去执行不同的计算任务,就很浪费资源,因为每一种计算引擎都要用硬件计算资源实现,等用户来用。如果我们知道一段时间里面计算任务是固定的,就可以把FPGA配置成只有某一个计算任务,节省资源,增强计算能力。
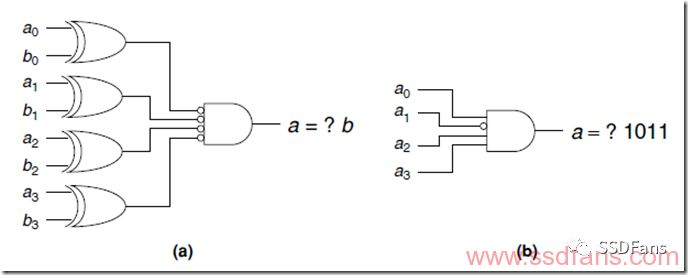
另一种情况叫做常数折叠,如果我们发现一段时间内某个变量其实不会变化,就可以当成常数,不用占用计算逻辑。如下图,本来是两个4bit数a和b比较器,但是已知b是1011,就可以直接用a来输出结果了,省了4个逻辑门。
FPGA做计算第二板斧:实时重配置
现在的FPGA支持里面的计算逻辑实时重配置,可以整个FPGA重新配置成新逻辑,比如上一毫秒是aPU,下一毫秒配成bPU。更实用的是部分逻辑实时重配置,因为FPGA里面很多逻辑是控制用的,不需要经常改,但是计算的那部分要根据使用情况经常换,所以支持某个分区的实时重配置。
FPGA做计算第三板斧:位宽压缩
我们写软件程序,习惯了两个32位或64位变量加减乘除,因为大家共享一个CPU计算单元,不浪费资源。可是到FPGA里面,是一种并行计算,每一个程序都是占用计算资源的,所以能省则省。比如,两个32位数相乘,如果我们已经知道某个数只会有两个bit是有效数据,就只需要用2个bit表示它,然后最后的结果做个移位就可以了。
归根结底,我们只要明白FPGA计算快的两大优点就是并行和流水线,但是必须时刻有并行计算的思想,尽量压缩算法占用的资源,这样才能用有限的FPGA计算资源实现最强大的并行计算能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









