







版权声明:本文为博主原创文章,未经博主允许不得转载。
从硬件角度分析,支持CUDA的NVIDIA 显卡,都是由多个multiprocessors 组成。每个 multiprocessor 里包含了8个stream processors,其组成是四个四个一组,也就是两组4D的处理器。每个 multiprocessor 还具有 很多个(比如8192个)寄存器,一定的(比如16KB) share memory,以及 texture cache 和 constant cache。
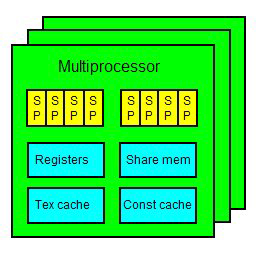
在 CUDA 中,大部份基本的运算动作,都可以由 stream processor 进行。每个 stream processor 都包含一个 FMA(fused-multiply-add)单元,可以进行一个乘法和一个加法。比较复杂的运算则会需要比较长的时间。
在执行 CUDA 程序的时候,每个 stream processor 就是对应一个 thread。每个 multiprocessor 则对应一个 block。但是我们一个block往往有很大量的线程,之前我们用到了256个和1024个,远超一个 multiprocessor 所有的8个 stream processor 。
实际上,虽然一个 multiprocessor 只有八个 stream processor,但是由于 stream processor 进行各种运算都有 latency,更不用提内存存取的 latency,因此 CUDA 在执行程序的时候,是以warp 为单位。
比如一个 warp 里面有 32 个 threads,分成两组 16 threads 的 half-warp。由于 stream processor 的运算至少有 4 cycles 的 latency,因此对一个 4D 的stream processors 来说,一次至少执行 16 个 threads(即 half-warp)才能有效隐藏各种运算的 latency( 如果你开始运算,再开一个线程,开始运算,再开一个线程,开始运算,再开一个线程开始运算,这时候第一个线程就ok了,第一个线程再开始运算 , 看起来就没有延迟了, 每个处理单元上最少开4个可以达到隐藏延迟的目的,也就是4*4=16个线程)。也因此,线程数达到隐藏各种latency的程度后,之后数量的提升就没有太大的作用了。
问:同一个SM中某一个时刻是不是只能执行同一个block里面的wrap呢?如果是的话,同一个时刻SM是否能够同时执行同一个block里面的多个wrap呢?如果是的话,由于同一个block共享32个bank,这样的话不同wrap,有没有可能产生bank confick呢,例如一个wrap0-31中的a[0]与第二个32-63wrap中的a[32]访问的是同一个bank?谢谢~
答:(1)否。一个SM可以执行来自多个blocks的warps的。而不是只能一个。这点你可以参考手册里的计算能力区别表格那里,可以清晰的看到不同计算能力的卡,能同时上多少个blocks。而它们的数字都不是1.(2)否。不同的blocks间的warps不会导致bank conflict. 目前只有一个warp内部的线程间才有可能会导致bank conflict.而不同warp不能同时导致bank conflict的原因是它们不能同时访问同一个SM里的shared memory的。同一个SM里的shared memory只能同时服务来自1个warp的请求。实际上,我们考虑shared memory是否有bank冲突的时候,只需要看某个warp的某个瞬间即可。 而无需考虑本次访问和它自身的之前、之后的访问以及和来自其他warp的访问之间的关系。 硬件本身的特性决定了,这些不能同时进行。不能同时进行自然也无bank conflict的。 你可以写个简单的程序,模拟你的怀疑,让线程31和线程32(这归属于2个不同的warp了)能同时下标映射到同一个bank上, 然后跑下profiler, 看下这两个events的计数信息: shared_ld_bank_conflict和shared_st_bank_conflict你会发现这两个数值为0.
问: 好的,谢谢,关于第一个问题还有点疑问:一个SM可以执行来自多个blocks的warps的,这个是同一个时刻执行来自多个blocks的warps?还是一个block结束后退出,然后接着执行下个?还点疑问,shared_ld_bank_conflict与shared_st_bank_conflict中ld与st代表什么呢?(这应该还是算第二次提问的延续吧,第三次我去论坛)
答:可以同时执行来自多个blocks的多个warps的。不是必须需要等待一个block完成才能进行下一个的。 但是资源的分配是以block为单位的,哪怕该block最后还残存1个warp在执行, 也需要等待此warp结束,才能block集体结束。 这会导致性能分析工具报告的achieved occupancy下降的。如果你写论文之类的话,可以在kernel结束前添加一个__syncthreads(),这会有效的提升achieved occupancy (但这对实际性能无任何用途)(只是数字好看了)(适合汇报使用)对Kepler到Pascal有效。















 5258
5258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









