






在使用nltk处理文本数据时,发现没有下载wordnet资源
需要运行如下代码:
import nltk
nltk.download('wordnet')运行后提示:
[nltk_data] Error loading wordnet: <urlopen error [Errno 11004]
[nltk_data] getaddrinfo failed>
选择手动下载nltk数据资源.
nltk数据库GitHub官网:NLTK
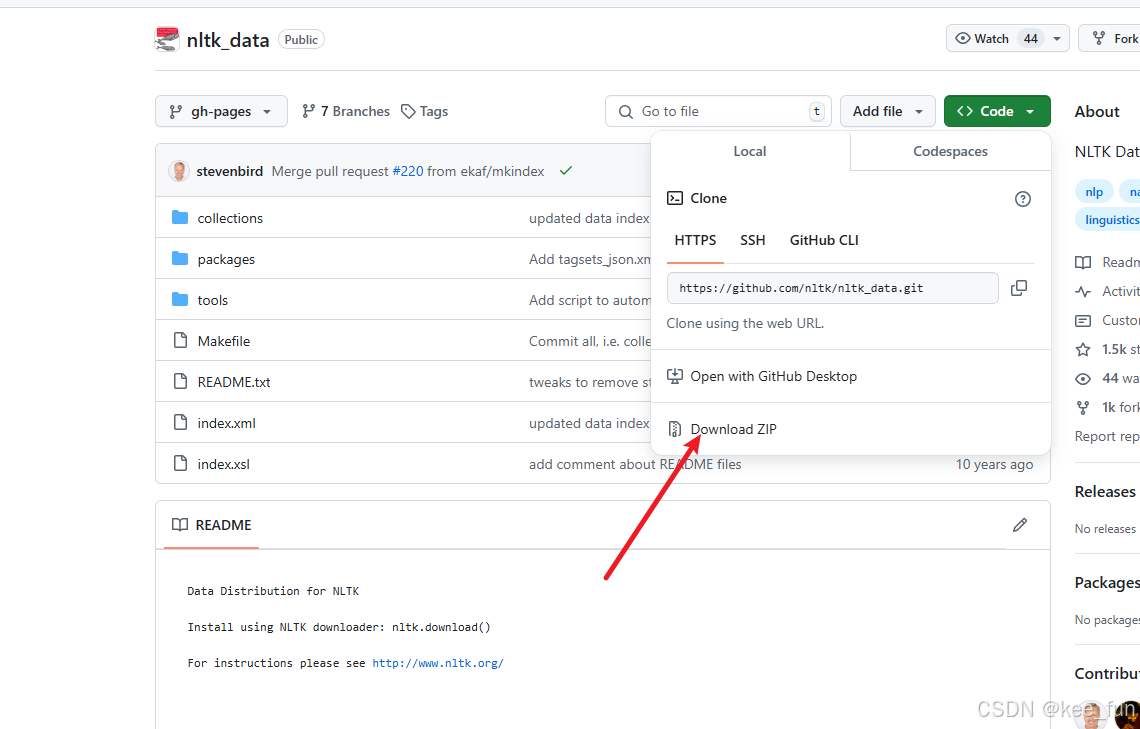
下载之后只需要保留packages文件夹
然后可以通过运行如下代码查看nltk数据包在电脑中的位置
import nltk
print(nltk.data.path)选择一个其中的位置
![]()
我这里以如上位置为例,将下载后保留的packages文件夹改名为nltk_data,并直接替换掉这里的原nltk文件.
然后进入corpora文件夹,找到wordnet.zip文件
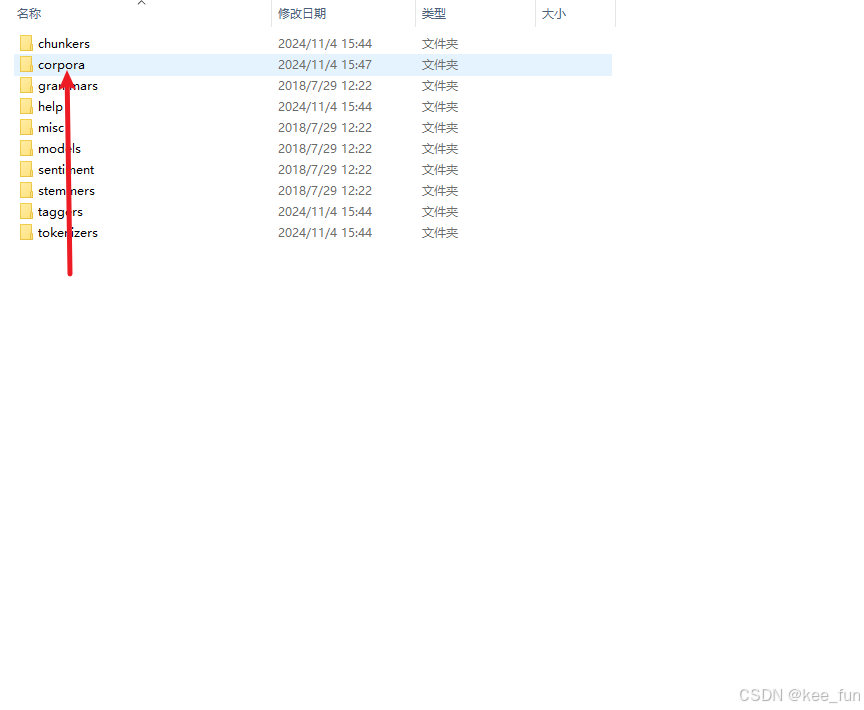
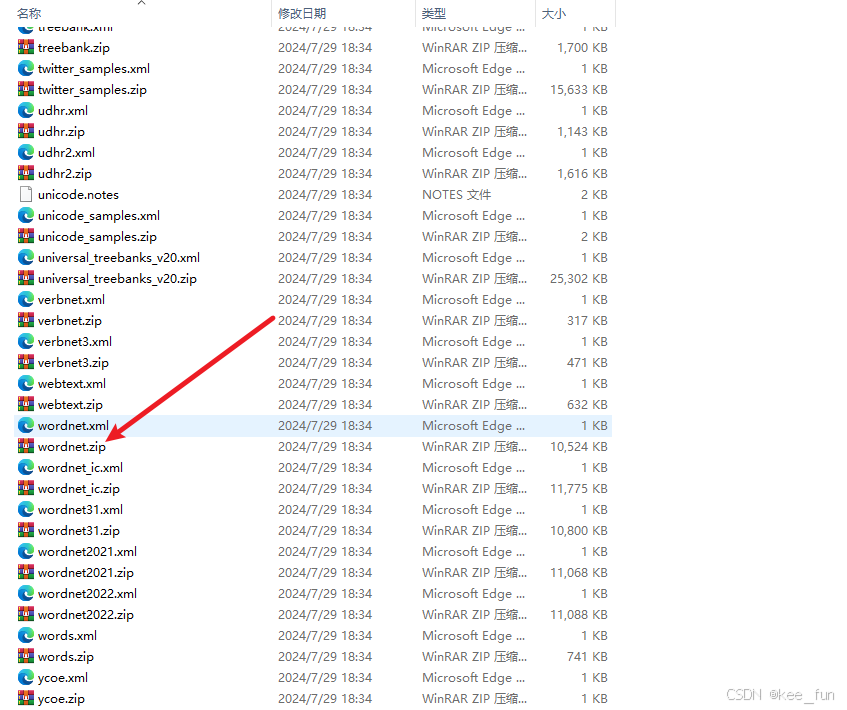
将其解压到corpora文件夹下,完成!
参考博文:
【自然语言处理】调用NLTK数据失败‘wordnet‘和‘punkt‘不存在[Errno 11004]问题解决_nltk.download('wordnet')-CSDN博客

















 1764
1764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









