







一:简单使用机制
参考:https://www.cnblogs.com/fdzfd/p/9319481.html
1:消息类型
- Map
- String(含json字符串类型)
2:处理方法
2.1 Map消息
如果发送的消息类型是map类型,可以通过SerializationUtils.deserialize方法将消息转换成map类型。
2.2 字符串类型(含json格式)
通过String类的构造函数接收byte[]类型的消息数据,获得jsonStr后可以转换成其它类,然后再进行相关操作。
这里@RabbitListener注解在方法上,如果类中有多个@RabbitListener(queues = TopicRabbitmqConfig.EVENT_MSG_QUEUE_NAME)注解的方法,测试的结果是轮流的调用。
3:另一种接收方式
注意,这里RabbitListener注解在类上,方法中通过@RabbitHandler注解标识。
RabbitMQConfig.java 配置
交换器(Exchange)
交换器就像路由器,我们先是把消息发到交换器,然后交换器再根据绑定键(binding key)和生产者发送消息时的路由键routingKey,
按照交换类型Exchange Type(fanout,direct,topic)把消息投递到对应的队列。(明白这个概念很重要,后面的代码里面充分体现了这一点)。
RabbitMQ基础知识可查看消息队列RabbitMQ基础知识详解
队列(Queue)
存放消息的队列。
绑定(Binding)
交换器怎么知道把这条消息投递到哪个队列呢?这就需要用到绑定了。大概就是:使用某个绑定键(binding key),把某个队列(Queue)绑定到某个交换器(Exchange),这样交换器就知道根据路由键把这条消息投递到哪个队列了。(后面的代码里面充分体现了这一点)
加入 RabbitMQ maven 依赖
配置
application.yaml文件中配置
RabbitMQConfig.java 配置
@Configuration
public class RabbitMQConfig {
public final static String QUEUE_NAME = "spring-boot-queue";
public final static String EXCHANGE_NAME = "spring-boot-exchange";
public final static String BINDING_KEY = "spring.boot.key.#";
// 创建队列
@Bean
public Queue queue() {
return new Queue(QUEUE_NAME);
}
// 创建一个 topic 类型的交换器
@Bean
public TopicExchange exchange() {
return new TopicExchange(EXCHANGE_NAME);
}
// 使用路由键(routingKey)把队列(Queue)绑定到交换器(Exchange)
@Bean
public Binding binding(Queue queue, TopicExchange exchange) {
return BindingBuilder.bind(queue).to(exchange).with(BINDING_KEY);
}
}
注:上面配置的是TopicExchange
实际业务中,可以配置多个队列和binding来满足需求。
生产者
直接调用 rabbitTemplate 的 convertAndSend 方法就可以了。从下面的代码里也可以看出,我们不是把消息直接发送到队列里面的,而是先发送到了交换器,交换器再根据路由键把我们的消息投递到对应的队列。
消费者
消费者也很简单,只需要对应的方法上加入 @RabbitListener 注解,指定需要监听的队列名称即可。
@Configuration
public class RabbitMQConfig {
public final static String QUEUE_NAME = "spring-boot-queue";
public final static String EXCHANGE_NAME = "spring-boot-exchange";
public final static String BINDING_KEY = "spring.boot.key.#";
// 创建队列
@Bean
public Queue queue() {
return new Queue(QUEUE_NAME);
}
// 创建一个 topic 类型的交换器
@Bean
public TopicExchange exchange() {
return new TopicExchange(EXCHANGE_NAME);
}
// 使用路由键(routingKey)把队列(Queue)绑定到交换器(Exchange)
@Bean
public Binding binding(Queue queue, TopicExchange exchange) {
return BindingBuilder.bind(queue).to(exchange).with(BINDING_KEY);
}
}
注:上面配置的是TopicExchange
实际业务中,可以配置多个队列和binding来满足需求。
生产者
直接调用 rabbitTemplate 的 convertAndSend 方法就可以了。从下面的代码里也可以看出,我们不是把消息直接发送到队列里面的,而是先发送到了交换器,交换器再根据路由键把我们的消息投递到对应的队列。
消费者
消费者也很简单,只需要对应的方法上加入 @RabbitListener 注解,指定需要监听的队列名称即可。
二 、6种工作模式
一.基于erlang语言: 是一种支持高并发的语言
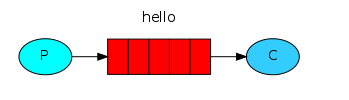
- 消息产生着§将消息放入队列
- 消息的消费者(consumer) 监听(while) 消息队列,如果队列中有消息,就消费掉,消息被拿走后,自动从队列中删除(隐患 消息可能没有被消费者正确处理,已经从队列中消失了,造成消息的丢失)应用场景:聊天(中间有一个过度的服务器;p端,c端)
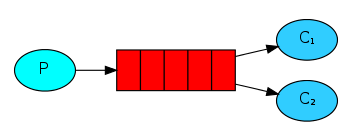
- 消息产生者将消息放入队列消费者可以有多个,消费者1,消费者2,同时监听同一个队列,消息被消费?C1 C2共同争抢当前的消息队列内容,谁先拿到谁负责消费消息(隐患,高并发情况下,默认会产生某一个消息被多个消费者共同使用,可以设置一个开关(syncronize,与同步锁的性能不一样) 保证一条消息只能被一个消费者使用)
- 应用场景:红包;大项目中的资源调度(任务分配系统不需知道哪一个任务执行系统在空闲,直接将任务扔到消息队列中,空闲的系统自动争抢)
1.3 publish/subscribe发布订阅(共享资源)
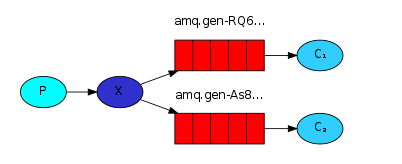
- X代表交换机rabbitMQ内部组件,erlang 消息产生者是代码完成,代码的执行效率不高,消息产生者将消息放入交换机,交换机发布订阅把消息发送到所有消息队列中,对应消息队列的消费者拿到消息进行消费
- 相关场景:邮件群发,群聊天,广播(广告)
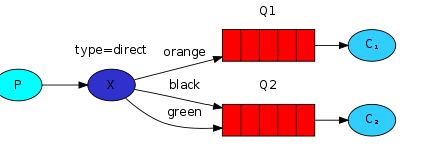
- 消息生产者将消息发送给交换机按照路由判断,路由是字符串(info) 当前产生的消息携带路由字符(对象的方法),交换机根据路由的key,只能匹配上路由key对应的消息队列,对应的消费者才能消费消息;
- 根据业务功能定义路由字符串
- 从系统的代码逻辑中获取对应的功能字符串,将消息任务扔到对应的队列中业务场景:error 通知;EXCEPTION;错误通知的功能;传统意义的错误通知;客户通知;利用key路由,可以将程序中的错误封装成消息传入到消息队列中,开发者可以自定义消费者,实时接收错误;
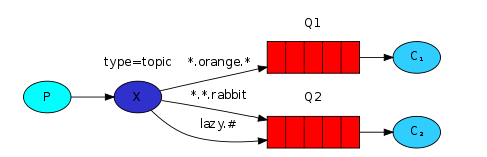
- 星号井号代表通配符
- 星号代表多个单词,井号代表一个单词
- 路由功能添加模糊匹配
- 消息产生者产生消息,把消息交给交换机
- 交换机根据key的规则模糊匹配到对应的队列,由队列的监听消费者接收消息消费
三 、消息的不丢失
https://www.cnblogs.com/flyrock/p/8859203.html
RabbitMQ一般情况很少丢失,但是不能排除意外,为了保证我们自己系统高可用,我们必须作出更好完善措施,保证系统的稳定性。
下面来介绍下,如何保证消息的绝对不丢失的问题,下面分享的绝对干货,都是在知名互联网产品的产线中使用。
1.消息持久化
2.ACK确认机制
3.设置集群镜像模式
4.消息补偿机制
第一种:消息持久化
RabbitMQ 的消息默认存放在内存上面,如果不特别声明设置,消息不会持久化保存到硬盘上面的,如果节点重启或者意外crash掉,消息就会丢失。
所以就要对消息进行持久化处理。如何持久化,下面具体说明下:
要想做到消息持久化,必须满足以下三个条件,缺一不可。
1) Exchange 设置持久化
2)Queue 设置持久化
3)Message持久化发送:发送消息设置发送模式deliveryMode=2,代表持久化消息
第二种:ACK确认机制
多个消费者同时收取消息,比如消息接收到一半的时候,一个消费者死掉了(逻辑复杂时间太长,超时了或者消费被停机或者网络断开链接),如何保证消息不丢?
这个使用就要使用Message acknowledgment 机制,就是消费端消费完成要通知服务端,服务端才把消息从内存删除。
这样就解决了,及时一个消费者出了问题,没有同步消息给服务端,还有其他的消费端去消费,保证了消息不丢的case。
第三种:设置集群镜像模式
我们先来介绍下RabbitMQ三种部署模式:
1)单节点模式:最简单的情况,非集群模式,节点挂了,消息就不能用了。业务可能瘫痪,只能等待。
2)普通模式:默认的集群模式,某个节点挂了,该节点上的消息不能用,有影响的业务瘫痪,只能等待节点恢复重启可用(必须持久化消息情况下)。
3)镜像模式:把需要的队列做成镜像队列,存在于多个节点,属于RabbitMQ的HA方案
为什么设置镜像模式集群,因为队列的内容仅仅存在某一个节点上面,不会存在所有节点上面,所有节点仅仅存放消息结构和元数据。下面自己画了一张图介绍普通集群丢失消息情况:
如果想解决上面途中问题,保证消息不丢失,需要采用HA 镜像模式队列。
下面介绍下三种HA策略模式:
1)同步至所有的
2)同步最多N个机器
3)只同步至符合指定名称的nodes
命令处理HA策略模版:rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]
1)为每个以“rock.wechat”开头的队列设置所有节点的镜像,并且设置为自动同步模式
rabbitmqctl set_policy ha-all "^rock.wechat" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
rabbitmqctl set_policy -p rock ha-all "^rock.wechat" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
2)为每个以“rock.wechat.”开头的队列设置两个节点的镜像,并且设置为自动同步模式
rabbitmqctl set_policy -p rock ha-exacly "^rock.wechat" \
'{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
3)为每个以“node.”开头的队列分配指定的节点做镜像
rabbitmqctl set_policy ha-nodes "^nodes\." \
'{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}'
但是:HA 镜像队列有一个很大的缺点就是: 系统的吞吐量会有所下降
第四种:消息补偿机制
为什么还要消息补偿机制呢?难道消息还会丢失,没错,系统是在一个复杂的环境,不要想的太简单了,虽然以上的三种方案,基本可以保证消息的高可用不丢失的问题,
但是作为有追求的程序员来讲,要绝对保证我的系统的稳定性,有一种危机意识。
比如:持久化的消息,保存到硬盘过程中,当前队列节点挂了,存储节点硬盘又坏了,消息丢了,怎么办?
产线网络环境太复杂,所以不知数太多,消息补偿机制需要建立在消息要写入DB日志,发送日志,接受日志,两者的状态必须记录。
然后根据DB日志记录check 消息发送消费是否成功,不成功,进行消息补偿措施,重新发送消息处理。
另外:
rabbitTemplate的发送消息流程是这样的:
1 发送数据并返回(不确认rabbitmq服务器已成功接收)
2 异步的接收从rabbitmq返回的ack确认信息
3 收到ack后调用confirmCallback函数
注意:在confirmCallback中是没有原message的,所以无法在这个函数中调用重发,confirmCallback只有一个通知的作用
在这种情况下,如果在2,3步中任何时候切断连接,我们都无法确认数据是否真的已经成功发送出去,从而造成数据丢失的问题。
最完美的解决方案只有1种:
使用rabbitmq的事务机制。
但是在这种情况下,rabbitmq的效率极低,每秒钟处理的message在几百条左右。实在不可取。
基于上面的分析,我们使用一种新的方式来做到数据的不丢失。
在rabbitTemplate异步确认的基础上
1 在本地缓存已发送的message
2 通过confirmCallback或者被确认的ack,将被确认的message从本地删除
3 定时扫描本地的message,如果大于一定时间未被确认,则重发
当然了,这种解决方式也有一定的问题:
想象这种场景,rabbitmq接收到了消息,在发送ack确认时,网络断了,造成客户端没有收到ack,重发消息。(相比于丢失消息,重发消息要好解决的多,我们可以在consumer端做到幂等)。
消息存入本地:在message 发消息的写数据库中。

消息应答成功,则删除本地消息,失败更改消息状态,可以使用定时任务去处理。

消息持久化:

消费者:
/**
* 防止重复消费,可以根据传过来的唯一ID先判断缓存数据库中是否有数据
* 1、有数据则不消费,直接应答处理
* 2、缓存没有数据,则进行消费处理数据,处理完后手动应答
* 3、如果消息 处理异常则,可以存入数据库中,手动处理(可以增加短信和邮件提醒功能)
*/















 2467
2467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









