







众所周知,java 中hashmap 基本的数据结构是 数组和 链表or 红黑树组成,在put或者get 操作的时候,计算数据下标是一个频繁的动作,本文分析一下java hashMap 的巧妙的算法设计。
首先数组下标必定是一个数字,java中HashMap 的最大值为 2>>30(2的30次方) 1073741824
实际场景中 hashMap的长度小于 2的16次方 (65536)
HashMap 的hash计算
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这里并没有直接返回 key的hash值,而是根据key 的原始hash值 XOR 原始hash值的前16位
为什么要做计算
首先这个hash值除了进行key 的对比之后,还被用来计算 数据下标
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
若使用原始hash值 计算数组下标也不是不可以,有人做了对比
package com.fancv.myCollentions;
import java.util.HashMap;
public class My {
static final void intToTwo(int num) {
String twoInt = "";
for (int i = num; i != 0; i = i / 2) {
if (i % 2 == 0) {
twoInt = "0" + twoInt;
} else {
twoInt = "1" + twoInt;
}
}
System.out.println(twoInt);
}
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return n + 1;
}
public static void main(String[] args) {
int cap = 1000;
int[] probability1 = new int[cap];
int[] probability2 = new int[cap];
for (int ic = 0; ic < cap; ic++) {
System.out.println("---------------");
int hashLong = ("fanglile" + ic).hashCode();
System.out.print(hashLong);
System.out.print(" ");
System.out.print((probability1[ic] = hashLong & (tableSizeFor(cap) - 1)));
System.out.print(" ");
intToTwo(hashLong);
hashLong ^= hashLong >>> 16;
System.out.print(hashLong);
System.out.print(" ");
System.out.print((probability2[ic] = hashLong & (tableSizeFor(cap) - 1)));
System.out.print(" ");
intToTwo(hashLong);
}
HashMap<Integer, Integer> map1 = new HashMap<>();
for (int ic = 0; ic < probability1.length; ic++) {
map1.put(probability1[ic], map1.containsKey(probability1[ic]) ? map1.get(probability1[ic]) + 1 : 1);
}
for (java.util.Map.Entry<Integer, Integer> e : map1.entrySet()) {
System.out.println(e.getKey() + " 出现次数是:" + e.getValue());
}
System.out.println(map1.size());
System.out.println("----------分割----------");
HashMap<Integer, Integer> map2 = new HashMap<>();
for (int ic = 0; ic < probability2.length; ic++) {
map2.put(probability2[ic], map2.containsKey(probability2[ic]) ? map2.get(probability2[ic]) + 1 : 1);
}
for (java.util.Map.Entry<Integer, Integer> e : map2.entrySet()) {
System.out.println(e.getKey() + " 出现次数是:" + e.getValue());
}
System.out.println(map2.size());
}
}
图像化显示:
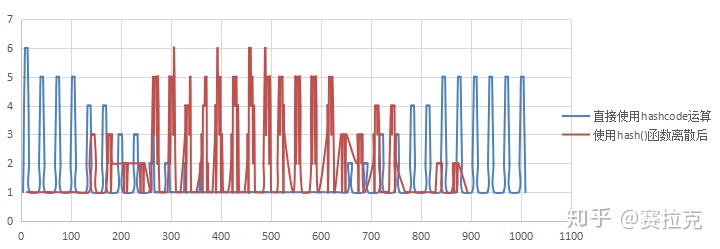
发现 使用了hash()之后 数据在数据中分布 更加集中在中间区域
分布更加平滑,优美。
为什么要右移16位
这里的16是基于经验设置的,java源码中很多例子都是作者根据多年经验设置的魔法数,例如hashMap的初始数组容量16 负载因子 0.75
为了是平衡性能和花销
这里的16位 是基于绝大多数情况下hashmap的长度不会超过65535,在根据数组(长度-1)&hash
计算数组下标的时候,hash的前16位不参与计算的,这就导致 数组下标的分布有集中的趋势,为了使得hash的前16位参与计算,需要无符号右移16位
为什么使用异或
异或运算
0 ^ 0 = 0;
1 ^ 0 = 1;
0 ^ 1 = 1;
1 ^ 1 = 0;
按位异或的3个特点:
(1)0异或任何数 = 任何数;
(2)1异或任何数 = 任何数取反;
(3)任何数异或自己 = 把自己置0;
java 的位运算 有| ^ &
and 或 or 趋向于 0 或者1 不利于后续数组下标的分散
XOR 更加合适
为什么使用 (length-1)&hash
计算数组下标一般都是 hash%(length)
但是这个计算比较耗费资源,所以在hashmap 设计的时候,规定 数组长度 是2 的N次方,最大
2>>30
这样使用了 hash&(length-1)==hash%length















 502
502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









