







 本文详细介绍了k近邻算法(k-NN),包括算法描述、距离度量方式以及K值选择的影响。通过实例展示了如何利用欧氏距离进行分类,并提供了算法的简单实现。k-NN是一种基于实例的学习,适用于分类问题,其分类决策依赖于最近邻的多数投票。文章还引用了相关学习资源供读者进一步研究。
本文详细介绍了k近邻算法(k-NN),包括算法描述、距离度量方式以及K值选择的影响。通过实例展示了如何利用欧氏距离进行分类,并提供了算法的简单实现。k-NN是一种基于实例的学习,适用于分类问题,其分类决策依赖于最近邻的多数投票。文章还引用了相关学习资源供读者进一步研究。
K近邻算法(k-nearest neighbor, k-NN)在各种算法中算是比较简单的算法,理解起来也比较轻松。
1.描述
在一个已知特征标签的数据集(训练集)中,数据集的各个元素在坐标空间中都是有距离的,而距离最近的数据子集一般具有相对优势的特征标签数量。新数据(测试数据,没有特征标签)输入后,观测与其相临近的K个数据组成的数据子集的特征标签,其中数量最多的即是该新数据的特征标签。
其中,有两个比较重要的概念:1.距离,一般采用欧氏距离度量,是欧几里得空间里两点间“普通”(即直线)距离。此外还有曼哈顿距离、切比雪夫距离、闵可夫斯基距离等。2.K,是自定义参数,K选取的大小对预测准确度有很大的影响,一般在2~10之间。
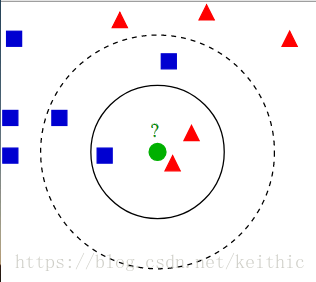
如图所示,数据集有两个特征标签(蓝色方块、红色三角),测试样本(绿色圆形)要么是蓝色方块类,要么是红色三角类。如果 k=3(实线圆圈)它会被分配给红色三角类,因为内圆内红色数量居多;如果k=5(虚线圆圈)它会被分配到蓝色方块类(3个正方形与2个三角形在外侧圆圈之内)。
2.算法
输入:训练集
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7460
7460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









