







数据抽象
数据抽象的目的与意义
- 数据对象
信息缺失:程序中的数据对象只有地址和值,没有数据类型、数据解释及数据意义等信息 - 解决手段:抽象
数据的表示:注释、有意义的数据对象名称
数据的功能:描述可以在数据上工作的操作集
数据的功能比表示更重要
例:程序员更关心整数的运算而不是计算机如何存储整数
结构化数据类型的性质
- 类 型
细节由用户自定义,语言仅提供定义手段 - 成 员
结构化数据类型的子数据对象 - 成员类型
每个成员具有确切的类型 - 成员数目
部分结构化数据类型可变,部分固定 - 成员组织
成员组织结构(线性结构或非线性结构)必须显式定义 - 操作集
可以在数据上进行的操作集合
数据封装
- 数据封装:将数据结构的细节隐藏起来
- 实现方式:分别实现访问数据成员的存取函数
- 数据封装示例
struct DYNINTS{
unsigned int capacity;
unsigned int count;
int * items;
bool modified;
};
unsigned int DiGetCount( DYNINTS* a )
{
if( !a ){ cout << "DiGetCount: Parameter illegal." << endl; exit(1); }
return a->count;
}
信息隐藏
- 数据封装的问题
只要将结构体类型定义在头文件中,库的使用者就可以看到该定义,并按照成员格式直接访问,而不调用存取函数 - 解决方法
将结构体类型的具体细节定义在源文件中,所有针对该类型量的操作都只能通过函数接口来进行,从而隐藏实现细节 - 信息隐藏示例
/* 头文件“dynarray.h”*/
struct DYNINTS; typedef struct DYNINTS * PDYNINTS;
/* 源文件“dynarray.cpp”*/
struct DYNINTS{
unsigned int capacity; unsigned int count; int * items; bool modified;
};
抽象数据类型
设计能够存储二维平面上点的抽象数据类型
/* 点库接口“point.h”*/
struct POINT;
typedef struct POINT * PPOINT;
PPOINT PtCreate( int x, int y ); //创建指针
void PtDestroy( PPOINT point ); //销毁指针
void PtGetValue( POINT point, int * x, int * y );
void PtSetValue( PPOINT point, int x, int y );
bool PtCompare( PPOINT point1, PPOINT point2 );
char * PtTransformIntoString( PPOINT point );
void PtPrint( PPOINT point );
/* 点库实现“point.cpp”*/
#include <cstdio>
#include <cstring>
#include <iostream>
#include "point.h"
using namespace std;
static char* DuplicateString( const char* s );
struct POINT{ int x, y; };
PPOINT PtCreate( int x, int y )
{
PPOINT t = new POINT; t->x = x; t->y = y; return t;
}
void PtDestroy( PPOINT point )
{
if( point ){ delete point; }
}
void PtGetValue( PPOINT point, int * x, int * y )
{
if( point ){ if( x ) *x = point->x; if( y ) *y = point->y; }
}
void PtSetValue( PPOINT point, int x, int y )
{
if( point ){ point->x = x; point->y = y; }
}
bool PtCompare( PPOINT point1, PPOINT point2 )
{
if( !point1 || !point2 ){ cout << "PtCompare: Parameter(s) illegal." << endl; exit(1); }
return ( point1->x == point2->x ) && ( point1->y == point2->y );
}
void PtPrint( PPOINT point )
{
if( point ) printf( "(%d,%d)", point->x, point->y );
else printf( "NULL" );
}
char * PtTransformIntoString( PPOINT point )
{
char buf[BUFSIZ];
if( point ){
sprintf( buf, "(%d,%d)", point->x, point->y );
return DuplicateString( buf );
}
else return "NULL";
}
char* DuplicateString( const char* s )
{
unsigned int n = strlen(s);
char* t = new char[n+1];
for( int i=0; i<n; i++)
t[i] = s[i];
t[n] = '\0';
return t;
}
链 表
链表定义
-
链表的意义与性质
存储顺序访问的数据对象集
数据对象占用的存储空间总是动态分配的 -
链表的定义
元素序列,每个元素与前后元素相链接

-
结点:链表中的元素
-
表头、表尾:链表的头尾结点
-
头指针、尾指针:指向表头、表尾的指针
链表数据结构
- 链表结点:使用结构体类型表示
至少包含两个域:结点数据域与链接指针域
struct NODE; typedef struct NODE * PNODE;
struct NODE{
PPOINT data; /* 当前结点的存储数据 */
PNODE next; /* 指向下一结点,表尾此域为 NULL */
};
- 链表结构:封装结点表示的细节
struct LIST; typedef struct LIST * PLIST;
struct LIST{
unsigned int count; /* 链表中包含的结点数目 */
PNODE head, tail; /* 链表头尾指针 */
};
- 标准链表图例

- 特别说明
结点总是动态分配内存的,所以结点逻辑上连续,物理上地址空间并不一定连续
时刻注意维护链表的完整性:一旦头指针 head 失去链表表头地址,整个链表就会丢失;任一结点 next 域失去下一结点地址,后续结点就会全部丢失。
有单向链表、双向链表、循环链表、双向循环链表
抽象链表
- 抽象链表接口
设计能够处理点数据类型的抽象链表接口
#include "point.h"
struct LIST;
typedef struct LIST * PLIST;
PLIST LlCreate();
void LlDestroy( PLIST list );
void LlAppend( PLIST list, PPOINT point );
void LlInsert( PLIST list, PPOINT point, unsigned int pos );
void LlDelete( PLIST list, unsigned int pos );
void LlClear( PLIST list );
void LlTraverse( PLIST list );
bool LlSearch( PLIST list, PPOINT point );
unsigned int LlGetCount( PLIST list );
bool LlIsEmpty( PLIST list );
抽象链表实现
- 链表的构造与销毁
PLIST LlCreate(){
PLIST p = new LIST;
p->count = 0;
p->head = NULL;
p->tail = NULL;
return p;
}
void LlDestroy( PLIST list )
{
if (list)
{
LlClear(list);
delete list;
}
}
void LlClear( PLIST list )
{
if( !list )
{
cout << "LlClear: Parameter illegal." << endl;
exit(1);
}
while( list->head )
{
PNODE t = list->head;
list->head = t->next;
PtDestroy( t->data );
delete t;
list->count--;
}
list->tail = NULL;
}
- 表头结点的删除
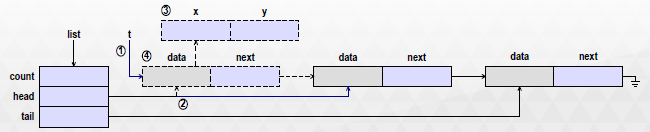
操作步骤
设置临时指针 t,使其指向链表头结点
将链表头结点设置为 t 的后继结点
删除原头结点 data 域所指向的目标数据对象
删除 t 所指向的结点
递减链表结点数目
- 结点的追加

void LlAppend( PLIST list, PPOINT point )
{
PNODE t = new NODE;
if( !list || !point ){ cout << "LlAppend: Parameter illegal." << endl; exit(1); }
t->data = point;
t->next = NULL;
if( !list->head )
{
list->head = t;
list->tail = t;
}
else
{
list->tail->next = t;
list->tail = t;
}
list->count++;
}
- 结点的插入


void LlInsert( PLIST list, PPOINT point, unsigned int pos )
{
if( !list || !point )
{
cout << "LlInsert: Parameter illegal." << endl;
exit(1);
}
if( pos < list->count )
{
PNODE t = new NODE;
t->data = point;
t->next = NULL;
if( pos == 0 )
{
t->next = list->head;
list->head = t;
}
else
{
unsigned int i;
PNODE u = list->head;
for( i = 0; i < pos - 1; ++i )
u = u->next;
t->next = u->next;
u->next = t;
}
list->count++;
}
else
LlAppend( list, point );
}
- 结点的删除

void LlDelete( PLIST list, unsigned int pos )
{
if( !list )
{
cout << "LlDelete: Parameter illegal." << endl;
exit(1);
}
if( list->count == 0 )
return;
if( pos == 0 )
{
PNODE t = list->head;
list->head = t->next;
if( !t->next )
list->tail = NULL;
PtDestroy( t->data );
delete t;
list->count--;
}
- 结点的遍历
编写函数,遍历链表,调用 PtTransformIntoString 函数输出结点数据,相邻结点使用“->”连接
void LlTraverse( PLIST list )
{
PNODE t = list->head;
if( !list )
{
cout << "LlTraverse: Parameter illegal." << endl;
exit(1);
}
while( t )
{
cout << PtTransformIntoString(t->data) << " -> ";
t = t->next;
}
cout << "NULL\n";
}
- 结点的查找
编写函数,在链表中查找特定点 point 是否存在
bool LlSearch( PLIST list, PPOINT point )
{
PNODE t = list->head;
if( !list || !point )
{
cout << "LlSearch: Parameter illegal." << endl;
exit(1);
}
while( t )
{
if( PtCompare( t->data, point ) )
return true;
t = t->next;
}
return false;
}
- 链表小结
链表的优点
插入和删除操作非常容易,不需要移动数据,只需要修改链表结点指针
与数组比较:数组插入和删除元素操作则需要移动数组元素,效率很低
链表的缺点
只能顺序访问,要访问某个结点,必须从前向后查找到该结点,不能直接访问
链表设计中存在的问题
链表要存储点数据结构,就必须了解点库的接口;如果要存储其他数据,就必须重新实现链表
若要存储目前还没有实现的数据结构,怎么办?
















 1405
1405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











