







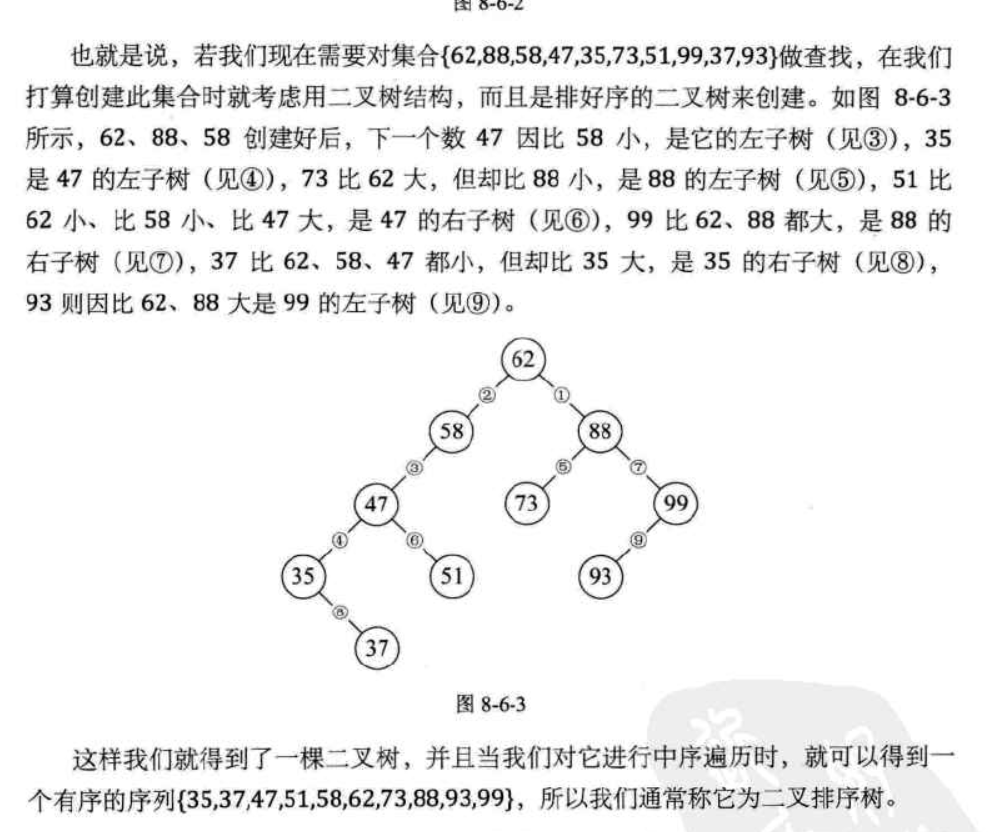
 本文探讨了动态查找中的问题,提出二叉排序树作为解决方案。二叉排序树是一种保证左子树所有节点小于根节点,右子树所有节点大于根节点的二叉树。文章详细解释了二叉排序树的定义,构建过程,包括查找、插入和删除操作,并通过代码示例展示了删除操作的三种情况。最后,强调了保持树平衡对于优化查找性能的重要性。
本文探讨了动态查找中的问题,提出二叉排序树作为解决方案。二叉排序树是一种保证左子树所有节点小于根节点,右子树所有节点大于根节点的二叉树。文章详细解释了二叉排序树的定义,构建过程,包括查找、插入和删除操作,并通过代码示例展示了删除操作的三种情况。最后,强调了保持树平衡对于优化查找性能的重要性。
请注意,为了能够更好的理解二叉排序树,我建议各位在看代码时能够设置好断点一步一步跟踪函数的运行过程以及各个变量的变化情况
一.动态查找所面临的问题
在进行动态查找操作时,如果我们是在一个无序的线性表中进行查找,在插入时可以将其插入表尾,表长加1即可;删除时,可以将待删除元素与表尾元素做个交换,表长减1即可。反正是无序的,当然是怎么高效怎么操作。但如果是有序的呢?回想学习线性表顺序存储时介绍的顺序表的缺点,就在于插入删除操作的复杂与低效。
正因为如此,我们引入了链式存储结构,似乎这样就能解决上面遇到的问题了。但细想一下,我们要进行的是查找操作,而链式结构的好处在于插入删除,但在查找方面则显得无能为力。那么有没有一种结构能让我们既提高查找的效率,又不影响插入删除的效率呢?
二.如何解决上述问题
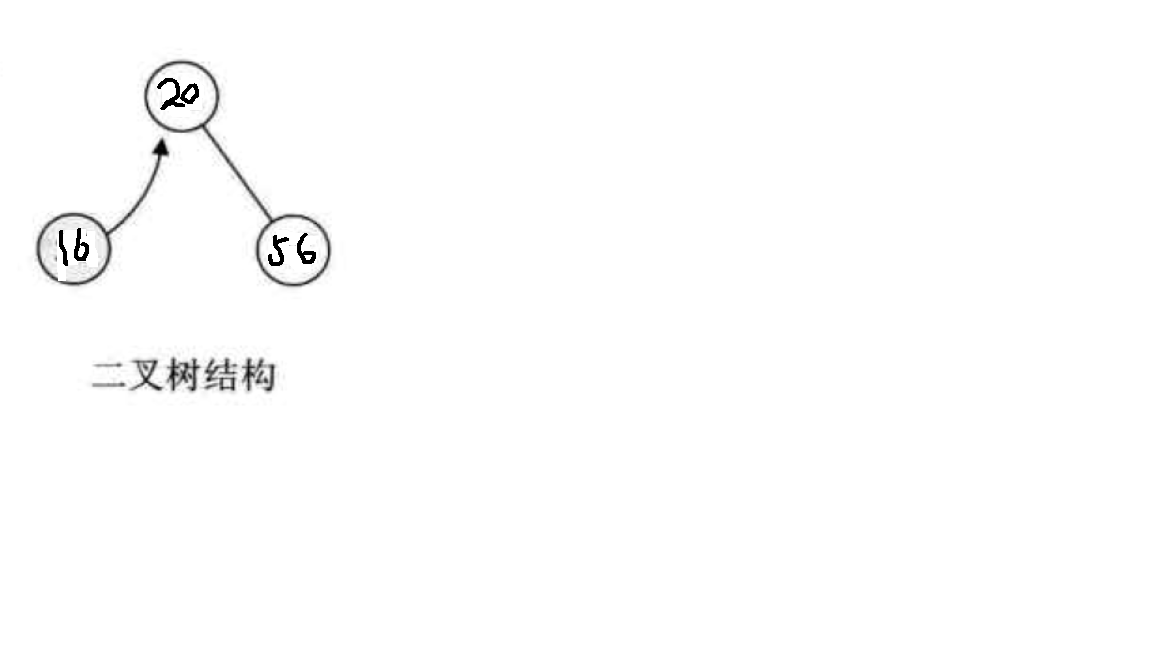
先从最简单的情况考虑,我们现在有一个只有一个数据元素的集合,假设为{20},现在我需要查找其中是否含有’56’这个数字,没有则插入;那么很显然执行该操作后集合变成了{20,56},继续查找集合中是否有’16’这个元素,没有则插入并且不改变原先的有序性。似乎要插入新数据就必须做移动。有没有办法不移动呢?有人想到了用二叉树来存储数据,让20做根节点,56比20大所以做右子树,16比20小所以做左子树,这样不就不用移动其位置了吗?思路见下图
三.二叉排序树(又称二叉搜索树)
1.定义
二叉排序树或者是一棵空树,或者是一棵有下列性质的二叉树:
1.若它的左子树不为空,则它左子树上所有结点的值必然小于根结点的值
2.若它的右子树不为空,则它右子树上所有结点的值必然大于根结点的值
3.它的左右子树也为二叉排序树
之所以要构造这样一棵树,不是为了排序,而是为了提高查找,插入和删除的效率
2.构建一棵二叉排序树
要构建一棵二叉排序树并实现相关操作,首先应理解下列的三个操作
1.查找操作:
给定key值,首先将其与根节点比较,相等则返回根结点,否则将其与根结点值进行比较,小于根结点则在左子树中递归查找;大于根结点则在右子树中递归查找,代码如下:
/*在BST中查找值为key的元素,f为指向双亲的指针,p用来返回查找路径上最后一个结点*/
Status SearchBST(BiTree T,int key,BiTree f,BiTree *p){
if(!T){
*p=f;
return ERROR;
}
if(T->data==key){
*p=T;
return OK;
}
else{
/*如果key值小于当前值,则进入左子树中查找*/
if(key<T->data)
return SearchBST(T->Lchild,key, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 992
992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









