







 本文介绍如何使用Python的requests库和Firefox的Temper Data插件模拟登录北邮信息门户,并爬取相关数据。通过分析登录表单,获取lt等关键参数,并利用session保持cookie,实现登录与爬取。
本文介绍如何使用Python的requests库和Firefox的Temper Data插件模拟登录北邮信息门户,并爬取相关数据。通过分析登录表单,获取lt等关键参数,并利用session保持cookie,实现登录与爬取。
之前利用爬虫爬取过百度贴吧的部分页面,但是百度贴吧并不需要登录。当我们发现一些网站上有具有实用价值的信息时,又往往需要登录后才能查看这些信息。那么如何通过python模拟登陆这些网站呢?我们以北邮信息门户为例。
一.工具
1.requests库
2.firefox浏览器和Temper Data
“工欲善其事,必先利其器”,之前我们介绍过urllib和urllib2这两个python自带的库。而requests库是一个第三方库,相比于前两个库则显得更为好用。
requests库提供了get,post,delete等方法,我们待会儿将用它来向网站发出请求
Temper Data是一个firefox插件,它能够拦截表单,以便我们查看表单内容。
二.爬取前的准备工作
首先打开信息门户网站”http://my.bupt.edu.cn/index.portal“,一个登录界面挡住了我们
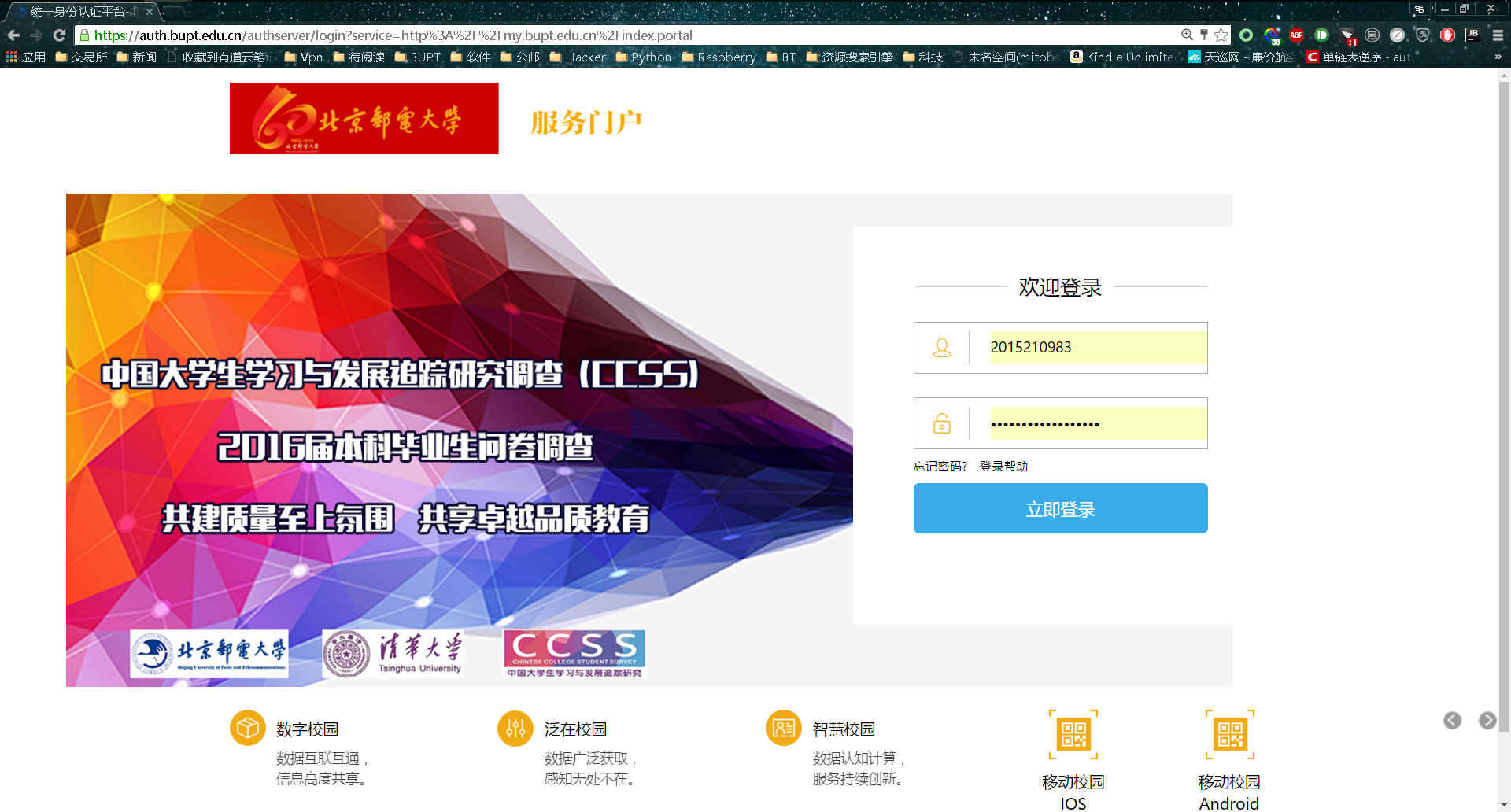
我们使用chrome浏览器的开发者模式,按下F12即可进入。 先输入一个错误的密码,点击登录按钮向网站发送一个表单。之后我们在查看这个表单都具有哪些内容。
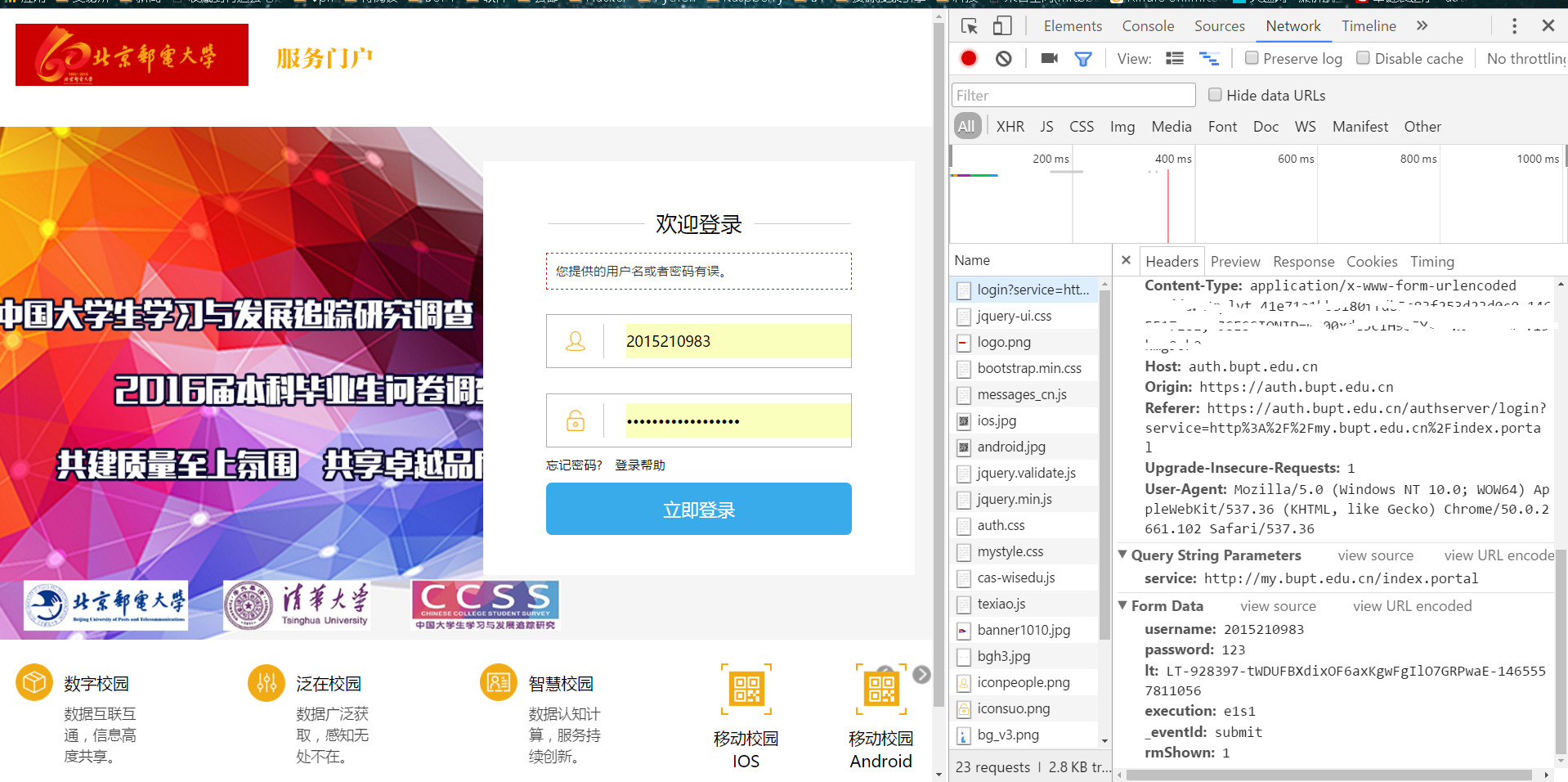
安全起见,我没有输入真实的密码,擦掉了cookie等敏感信息。我们看到表单中具有这样几个内容:
1.username
2.password
3.lt(待会儿介绍这是什么)
4.execution
5._eventId:
6.rmShown
通过分析,我们知道要想登录,就要构造含有上面这些内容的表单,username,password由用户提供,经过多次的抓取表单分析后,发现execution,_eventId,rmShown都是常量。
那么唯一没有解决的问题就是lt,lt在每次的发送的表单中都不相同,而且看不出什么规律,l
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









