







一、需求:
在编写MapReduce程序时,常用的TextInputFormat是以换行符作为Record分隔符的,即该行的内容作为MapReduce中map方法中的value,而该行头在文件中的偏移值作为key。
但是在实际应用中,我们在提取日志内容时,有可能遇到一条Record包含多行的情况,并且要提取字段开始限定符到结束限定符的情况,如下。
2015/09/01 12:23:12 435[INFO]: xxxxx.xxx.xxx:
<xml>
…
<xml>
2015/09/01 12:23:12 735[INFO]: xxxxx.xxx.xxx:
…
2015/09/01 12:23:13 835[INFO]: xxxxx.xxx.xxx:
<xml>
…
<xml>
2015/09/01 12:23:13 835[INFO]: xxxxx.xxx.xxx:
<xml>
…
<xml>
我们要提取得到:
<xml>
…
<xml>
<xml>
…
<xml>
<xml>
…
<xml>
二、相关类的UML图及TextInputFormat流程:
这时候就要自定义自己的InputFormat来完成这个功能。其中涉及到的类如下,其中黑色的类是org.apache.hadoop.mapreduce.lib.input的源码,蓝色的类是对应左边新创建的类。
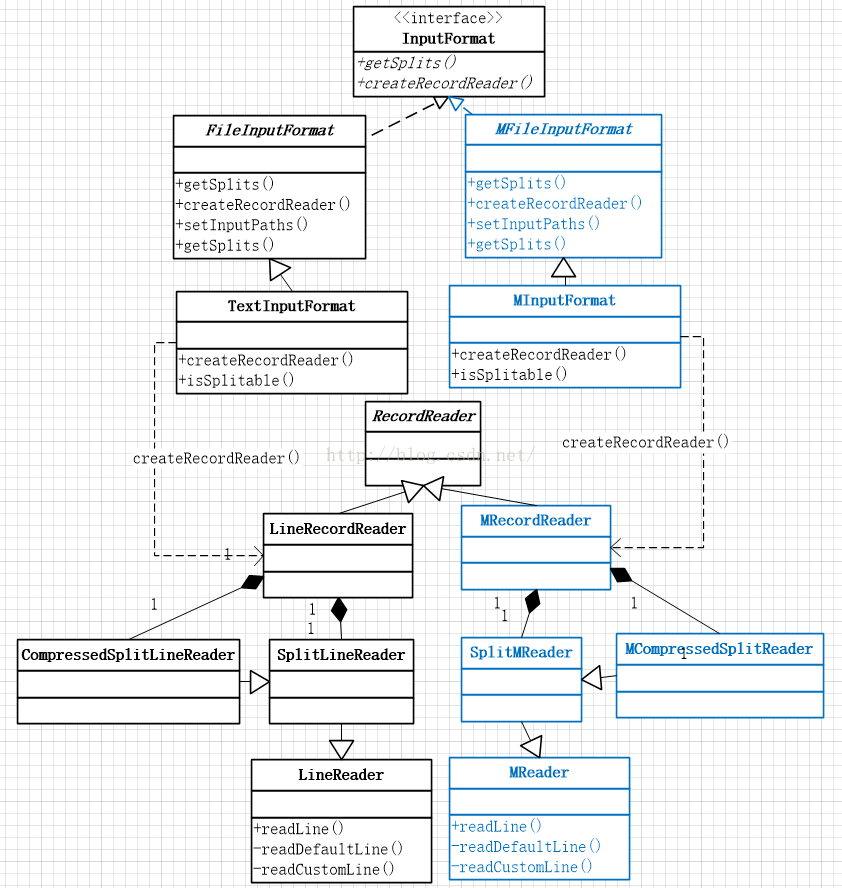
TextInputFormat对文件处理流程

三、各个自定义类说明
1、MInputFormat.java
说明:该类ctrl+v了org.apache.hadoop.mapreduce.lib.input.TextInputFormat, 调整了以下方法:
@Override
//把开始与结束的限定符从configuration中读取,再传人到MeacorderRdader中
public RecordReader<LongWritable, Text>
createRecordReader(InputSplit split,
TaskAttemptContext context) {
//record结束的限定符
String delimiter = context.getConfiguration().get(
"textinputformat.record.end.delimiter");
//record限定的开始符
String startdelimiter = context.getConfiguration().get(
"textinputformat.record.start.delimiter");
byte[] recordDelimiterBytes = null;
byte[] startRecordDelimiterBytes = null;
if (null != delimiter)
recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);
startRecordDelimiterBytes = startdelimiter.getBytes(Charsets.UTF_8);
//返回自定义的recordReader
return new MRecordReader(startRecordDelimiterBytes,recordDelimiterBytes);
}
2、MFileInputFormat.java
说明:该类ctrl+v了org.apache.hadoop.mapreduce.lib.input.FileInputFormat,原来是不用改的,但是现在有这样的需求,递归读取指定目录下的文件,而原来的FileInputFormat只会读取当前指定目录的文件而已。调整了以下方法:
public static void setInputPaths(Job job,
Path... inputPaths) throws IOException {
Configuration conf = job.getConfiguration();
StringBuffer str = new StringBuffer();
for(int i = 0; i < inputPaths.length;i++) {
Path path = inputPaths[i].getFileSystem(conf).makeQualified(inputPaths[i]);
RemoteIterator<LocatedFileStatus> files = inputPaths[0].getFileSystem(conf).listFiles(path, true);
while(files.hasNext())
{
str.append(StringUtils.escapeString(files.next().getPath().toString()));
str.append(StringUtils.COMMA_STR);
}
}
String strTmp = str.toString();
if(strTmp != null && !strTmp.trim().equals(""))
strTmp = strTmp.substring(0, strTmp.length()-StringUtils.COMMA_STR.length());
LOG.info("**************************strTmp:"+strTmp);
conf.set(INPUT_DIR, strTmp);
}
3、MRecordReader.java
说明:该类ctrl+v了org.apache.hadoop.mapreduce.lib.input.LineRecordReader,该类的nextKeyVlaue方法是读取(key,value)传递给Mapper的map方法,该类修改不多,主要把限定符传递给splitReader,就不贴代码了。
4、SplitMReader.java与MCompressedSplitReader.java
说明:该类ctrl+v了org.apache.hadoop.mapreduce.lib.input. CompressedSplitLineReader与SplitLineReader,MCompressedSplitReader继承SplitMReader,MRecordReader根据会判断文件是否为压缩文件选择用MCompressedSplitReader或SplitMReader,修改不多,就不贴代码了。
5、MReader.java
说明:该类ctrl+v了org.apache.hadoop.mapreduce.lib.input.LineReader,主要的内容分隔读取逻辑在该类实现。思路是类中有个buffer缓存数组,以游标形式顺序读取文件或数据块不断放入buffer中,内容提取从readCustomLine这个方法开始,不断扫描buffer中的数据,用方法readStartMark(byte[] startMarkBytes)找到起始限定符开始的位置,然后提取内容,直到匹配上了结束限定符。
private int readCustomLine(Text str, int maxLineLength, int maxBytesToConsume)
throws IOException {
int txtLength = 0; // tracks str.getLength(), as an optimization
long bytesConsumed = 0;//record的长度
int delPosn = 0;记录当前已匹配到delimiter的第几个字符
int ambiguousByteCount=0; // To capture the ambiguous characters count //保存上一次buffer结束时候匹配到结束字符串的第几个字符
str.clear();
//这个是我加上去的,可以限定record从哪里开始哦
this.startMarkbytesConsumed = 0;
bufferPosn = readStartMark(this.startRecordDelimiterBytes);
bytesConsumed += this.startMarkbytesConsumed;
//添加匹配头
str.append(this.startRecordDelimiterBytes, 0, this.startRecordDelimiterBytes.length);
do {
int startPosn = bufferPosn; // Start from previous end position
if (bufferPosn >= bufferLength) {//貌似读到了当前buffer尽头了
startPosn = bufferPosn = 0;
//又要重新去load缓存的数据
bufferLength = fillBuffer(in, buffer, ambiguousByteCount > 0);
if (bufferLength <= 0) {//如果未能load进数据,要把那匹配的几个delimiter中的字符加上去
str.append(endRecordDelimiterBytes, 0, ambiguousByteCount);
break; // EOF
}
}
for (; bufferPosn < bufferLength; ++bufferPosn) {
if (buffer[bufferPosn] == endRecordDelimiterBytes[delPosn]) {//又找到一个匹配的字符了
//记录当前已匹配到delimiter的第几个字符
delPosn++;
if (delPosn >= endRecordDelimiterBytes.length) {//恭喜你
//完全可以匹配到delimiter,跳出循环,就要返回了。
bufferPosn++;
break;
}
}
//很不幸,未能完全匹配到delimiter
else if (delPosn != 0) {
bufferPosn--;//稍微前移一下
delPosn = 0;
}
}
int readLength = bufferPosn - startPosn;
bytesConsumed += readLength;
//当重新读取下一个buffer时,先让str不添加delimiter的前部分
int appendLength = readLength - delPosn;
//超过最大长度了,要截断
if (appendLength > maxLineLength - txtLength) {
appendLength = maxLineLength - txtLength;
}
if (appendLength > 0) {
if (ambiguousByteCount > 0) {//若新的buffer不能构成完整的delimiter,就应该增加上次buffer的尾巴
str.append(endRecordDelimiterBytes, 0, ambiguousByteCount);
//appending the ambiguous characters (refer case 2.2)
//bytesConsumed增加上次buffer的尾巴的计数
bytesConsumed += ambiguousByteCount;
ambiguousByteCount=0;
}
str.append(buffer, startPosn, appendLength);
txtLength += appendLength;
}
if (bufferPosn >= bufferLength) {
//终于到一个buffer的终点了
//居然buffer的结尾匹配到了几个delimiter中的字符
if (delPosn > 0 && delPosn < endRecordDelimiterBytes.length) {
//bytesConsumed要先减去那几个字符
ambiguousByteCount = delPosn;
bytesConsumed -= ambiguousByteCount; //to be consumed in next
}
}
} while (delPosn < endRecordDelimiterBytes.length
&& bytesConsumed < maxBytesToConsume);//一次循环下来未能完全匹配一个结束字符串
if (bytesConsumed > Integer.MAX_VALUE) {
throw new IOException("Too many bytes before delimiter: " + bytesConsumed);
}
//只有构成一个完整的开始与结束
if(delPosn == endRecordDelimiterBytes.length){
//作为结果返回
str.append(this.endRecordDelimiterBytes,0,this.endRecordDelimiterBytes.length);
str.set(str.toString());
}
return (int) bytesConsumed;
}
四、运行
在job的main方法中使用该自定义InputFormat,读取日志文件:
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "job_"+args[0]+"_"+args[1]);
job.setJarByClass(ReqExtracJob.class);
// TODO: specify input and output DIRECTORIES (not files)
MFileInputFormat.setInputPaths(job, new Path(args[2]));
FileOutputFormat.setOutputPath(job, new Path(args[3]));
//抽取字符串的起始与截止位置
job.getConfiguration().set("textinputformat.record.startdelimiter","<xml>");
job.getConfiguration().set("textinputformat.record.delimiter","</xml>");
job.setInputFormatClass(MInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
附:
相关代码下载链接














 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









