







【Dynamic-SLAM】 动态视觉SLAM
1. 为什么需要Dynamic-SLAM(动态视觉SLAM)
动态视觉SLAM(Dynamic Visual SLAM)在许多应用场景中是必不可少的,其主要原因包括以下几点:
1.1 处理动态环境
- 动态障碍物:在现实世界中,许多环境是动态的,存在移动的物体(如行人、车辆、动物等)。传统的SLAM算法通常假设环境是静态的,而动态视觉SLAM则能够实时地识别和处理这些动态障碍物,从而提高定位和地图构建的准确性。
- 自适应性:动态视觉SLAM能根据环境的变化快速自适应,从而保证机器人的安全导航和高效工作。
1.2. 增强地图的准确性
- 分离静态与动态特征:通过将动态物体与静态背景分离,动态视觉SLAM可以构建更为准确的环境地图。这对于后续的路径规划和决策制定非常重要。
- 减少噪声影响:动态物体可能对环境特征造成干扰,动态视觉SLAM通过过滤掉这些动态特征,减少了对地图的噪声影响,提升了整体性能。
1.3 支持实时应用
- 实时性能:在许多应用中(如自动驾驶、无人机飞行、机器人导航),系统必须在快速变化的环境中实时做出反应。动态视觉SLAM能够提供高效的地图更新和定位,适应这些快速变化的环境。
- 提高响应速度:动态视觉SLAM可以在动态场景中快速更新状态,帮助机器人及时避开障碍,确保安全性。
1.4 改善导航与决策能力
- 智能决策:动态视觉SLAM提供了更为丰富的环境信息,使得机器人能够在复杂场景中做出更智能的决策,如避开障碍物、选择最佳路径等。
- 路径规划:通过精确的环境模型,动态视觉SLAM可以帮助机器人进行高效的路径规划,特别是在动态变化的环境中。
1.5 多种应用场景
- 自动驾驶:在自动驾驶中,动态视觉SLAM能够实时识别路上的行人、车辆和其他动态障碍物,从而安全导航。
- 机器人导航:在服务机器人或工业机器人的应用中,动态视觉SLAM可以帮助机器人在不确定的动态环境中进行有效导航。
- 增强现实(AR)与虚拟现实(VR):动态视觉SLAM在AR/VR中用于实时跟踪用户的运动与环境变化,提供更好的沉浸体验。
1.6 提高系统的鲁棒性
- 鲁棒性增强:动态视觉SLAM可以通过实时更新和动态特征识别提高系统的鲁棒性,确保在复杂和动态的环境中保持稳定性和可靠性。
动态视觉SLAM的需求主要源于现实世界的复杂性和多变性,它能够有效处理动态障碍物,提供更精确的定位和地图信息,支持智能决策与实时反应。随着自动驾驶、机器人导航、增强现实等领域的发展,动态视觉SLAM的重要性日益凸显。
2. 环境中的所有物体依据“动态程度”的不同,分为四类:
- 高动态物体:实时移动的物体,如行人、车辆、跑动的宠物…
- 低动态物体:短暂停留的物体,如站在路边短暂交谈的人。
- 半静态物体:在一个SLAM周期中不动,但并非永远不动的物体,如停车场的>车辆、堆放的物料、临时工棚、临时围墙、商场中临时搭建的舞台…
- 静态物体:永远不动的物体,如建筑物、马路、路沿、交通信号灯杆。
除了静态物体外的其它三类物体,都有不同程度上的动态属性,应对策略也各不>相同:
- 针对高动态物体:在线实时过滤。
- 针对低动态物体:一次SLAM过程结束后,后处理方式过滤。
- 针对半静态物体:全生命周期建图(life-long SLAM, or long-term SLAM)。
3. 基于目标检测/语义分割的动态SLAM
3.1 DS-SLAM(2018年)
- 论文链接:[DS-SLAM: A Semantic Visual SLAM towards Dynamic Environments]
- 代码链接:[https://github.com/ivipsourcecode/DS-SLAM]
基于目标检测或语义分割的动态SLAM是当前研究的主流方向之一。这种方法的基本思路是在ORB-SLAM2/3或VINS等传统SLAM系统的基础上,集成YOLO等目标检测模型,以识别并剔除动态物体对特征点的影响。以下是这一方法的一些主流方案:
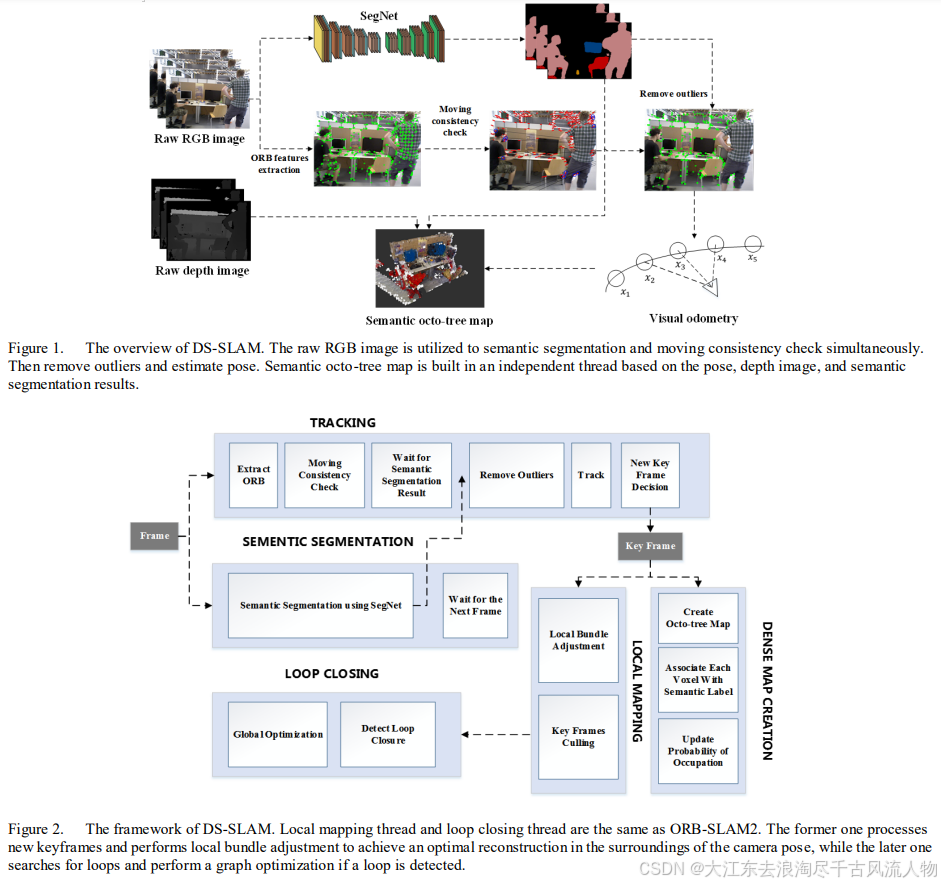
DS-SLAM的主要特点:
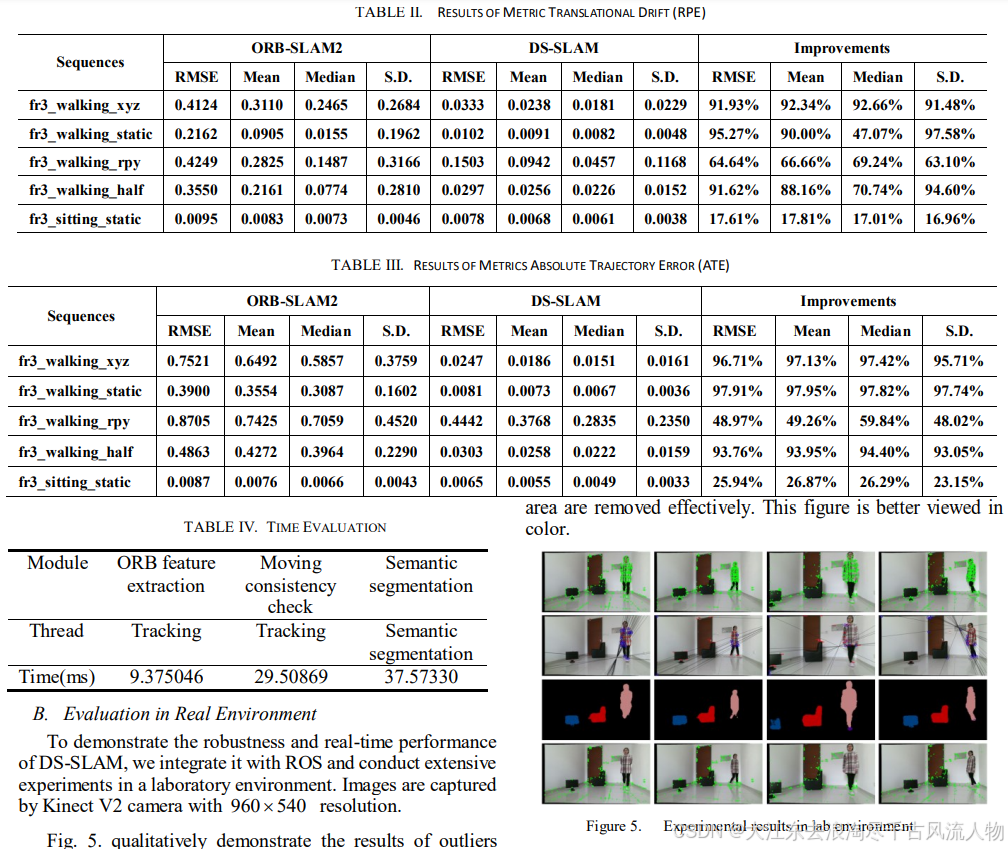
- 基于ORB-SLAM2开发,包含5个并行线程:跟踪、语义分割、局部建图、回环检测和稠密语义八叉树地图构建。
- 使用SegNet进行语义分割,针对动态目标(如行人)进行运动一致性检查,剔除动态区域上的特征点。
- 运动一致性检查流程:
- 计算光流金字塔,获取当前帧中的匹配特征点对。
- 校验匹配点对的合法性,剔除靠近图像边缘或像素值差异过大的点对。
- 使用RANSAC算法寻找内点,并求解基础矩阵。
- 利用基础矩阵计算当前帧中的极线方程。
- 计算匹配点到极线的距离,超过阈值的点对被认为是动态点,予以剔除。
优点:
- 通过语义分割和运动一致性检查,有效剔除动态物体的影响,提高SLAM在动态环境下的鲁棒性和准确性。
- 实验结果表明,DS-SLAM在动态环境下的绝对轨迹误差(ATE)相比ORB-SLAM2有数量级的改善。
缺点:
- 依赖于语义分割的准确性,对于未预先定义的动态物体(如人手上的书),可能无法有效识别和处理。
- 在YOLO等目标检测模型漏检时,系统稳定性会受到影响。
总的来说,基于目标检测或语义分割的动态SLAM方法通过结合深度学习模型,有效提高了SLAM系统在动态环境下的鲁棒性。然而,这些方法仍然面临一些挑战,如对语义分割准确性的依赖、对未定义动态物体的处理能力有限等。未来的研究可能会集中在提高目标检测的准确性、增强对未知动态物体的适应能力等方面。
3.2 DynaSLAM(2018年)
paper : Tracking, Mapping and Inpainting in Dynamic Scenes
DynaSLAM是一种视觉SLAM系统,它基于ORB-SLAM2,并增加了动态物体检测和背景修复的能力,以提高在动态场景中的鲁棒性。以下是DynaSLAM的主要特点和工作流程:
-
DynaSLAM的主要特点:
-
动态物体检测:能够检测和处理动态物体,避免它们对SLAM过程产生干扰。
-
背景修复:对于被动态物体遮挡的背景区域,使用历史观测数据进行修复,从而生成完整的场景地图。
-
多相机支持:适用于单目、双目和RGB-D相机配置。
-
实时性能:虽然DynaSLAM尚未针对实时操作进行优化,但其生成的静态场景地图适用于长期应用。
-
DynaSLAM的工作流程:
-
动态物体检测:
- 使用Mask R-CNN**进行像素级语义分割,识别出图像中潜在的动态物体,如行人、车辆等,总所周知,这个检测识别框架,必然会带来这个问题。美哟办法实现实时检测西面可以看到基本需要200ms+的时间。
- 结合多视图几何方法,通过分析深度和角度变化,进一步检测正在移动的物体。
-
相机位姿估计:
- 仅使用静态区域和非动态物体边缘的ORB特征点进行相机位姿估计,以提高定位的准确性。
-
背景修复:
- 利用历史观测数据,对被动态物体遮挡的背景区域进行修复,生成没有动态内容的合成图像。
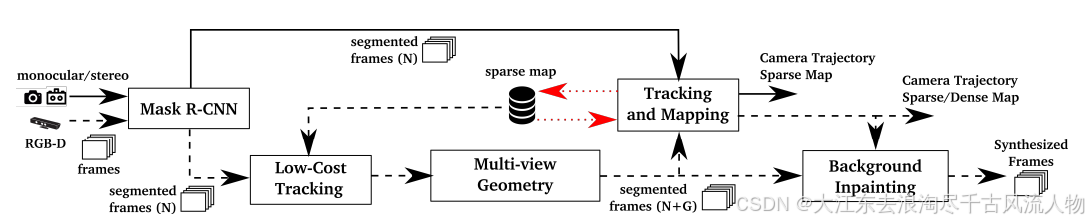
图 2:我们提议的方案的框图。在立体声和单目管道(黑色实线)中,图像首先通过一个卷积神经网络(Mask R-CNN)来计算像素级的语义分割,以识别出先验动态物体,然后才用于映射和跟踪。在RGB-D案例中(黑色虚线),增加了一种基于多视图几何的方法来进行更精确的运动分割,为此我们需要一个低成本的跟踪算法。一旦知道了相机的位置(跟踪和映射输出),我们就可以对被动态物体遮挡的背景进行修复。红色虚线表示存储的稀疏地图的数据流。
- 利用历史观测数据,对被动态物体遮挡的背景区域进行修复,生成没有动态内容的合成图像。
- DynaSLAM中几何一致性验证的具体流程:
-
选择关键帧:
- 选取与当前关键帧(CF)重合度最高的5个关键帧(KF)。
-
投影和深度计算:
- 计算每个关键点从KF到CF的投影,获取投影后的坐标和深度。
-
视差角和深度差异分析:
- 计算两个坐标之间的视差角,如果大于30°,则认为该点可能属于动态物体,予以滤除。
- 计算两个深度之间的差值,如果超过设定的阈值,则认为该点属于动态物体。
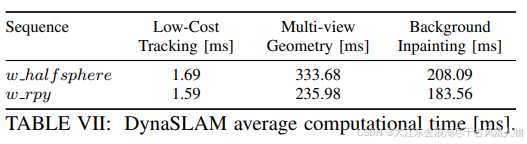
尽管DynaSLAM在处理动态场景时表现出了较好的效果,但其计算耗时较大,特别是在进行深度学习和多视图几何分析时。未来的工作可能包括提高实时性能、开发基于RGB的动态物体检测方法,以及通过使用更复杂的修复技术来提高合成RGB帧的真实感。
3.3 RDS-SLAM(2020 12月)
前面说到,语义分割的主要问题在于太过耗时。而RDS-SLAM的主要贡献就是在实时性上的提升。RDS-SLAM是在ORB-SLAM3的基础上,开辟了一个独立的语义线程。这样就可以不等待语义信息进入跟踪线程,将语义分割与跟踪分离。利用移动概率将语义信息从语义线程传递到跟踪线程。利用移动概率来检测和去除跟踪中的异常值。
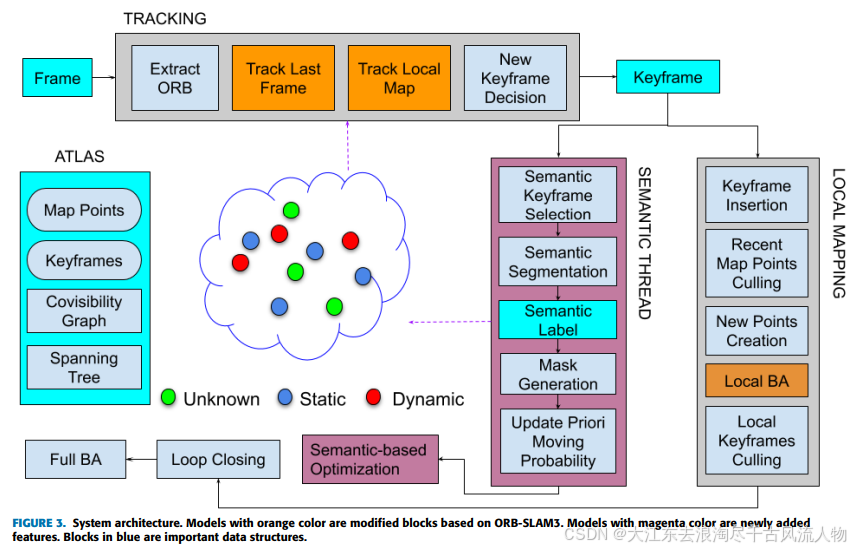
那么具体来说,为啥开辟一个新的语义线程就可以提高实时性呢?作者定义了语义延时来说明该部分如何保证语义分割的实时性。首先按照时间顺序分割每一帧(假设语义分割一次耗时10次采样时间,每隔两帧取一个关键帧),同时连续分割两帧。注意,作者使用了双向模型(bi-directional model),关键帧的分割不是按顺序进行的,而是分割队列的前面和后面。这里还有一个问题,就是为什么还要对前面的关键帧做分割呢?这是因为如果前几帧没有语义信息,由于跟踪线程很快,可能已经因为动态物体累计了很大的误差。因此,需要使用语义信息来把漂移拉回来。


对于速度的提升也很明显,可以在2080Ti上达到实时。
3.4 MMS-SLAM(22年5月)
MMS-SLAM不是一个纯视觉方案,而是多模态方案。MMS-SLAM能够在不同的动态环境中提供实时定位,并解决由于误分类、小尺度目标和遮挡造成的分割错误。具体来说,作者修改了现有的主干网络,以学习更强大的对象特征表示,并在主干网络中部署了两次查看和思考的机制,提升了实例分割的性能。此外,作者结合几何聚类和视觉语义信息来减少运动模糊的影响。
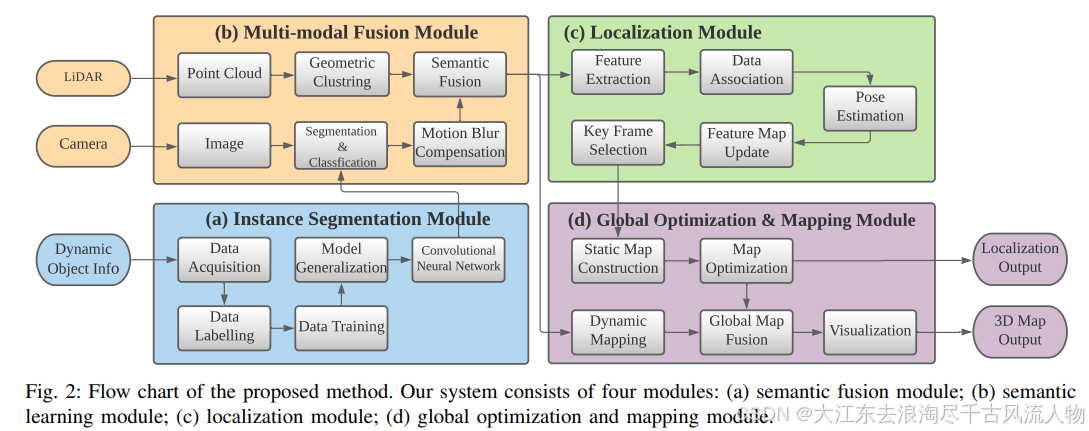
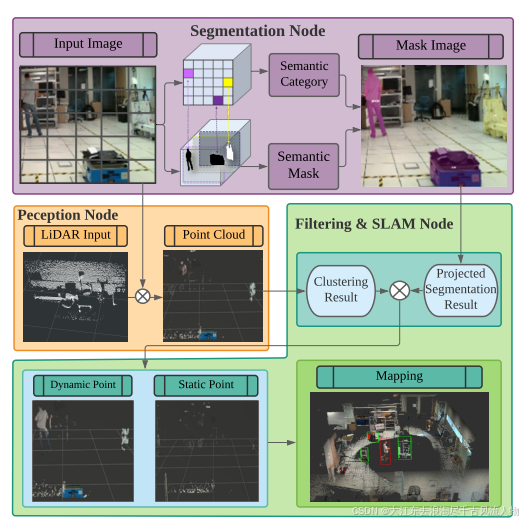
图 1:提出的多模态语义SLAM系统概览。与传统的语义SLAM相比,我们提议使用多模态方法来提高现有SLAM方法在复杂和动态环境中的效率和准确性。我们的方法显著减少了由动态物体引起的定位漂移,并在实时进行密集的语义映射。
MMS-SLAM的语义框架由四个模块组成,即实例分割模块、多模态融合模块、定位模块和全局优化及建图模块。实例分割模块使用实时实例分割网络来提取RGB图像中存在的所有潜在动态对象的语义信息。卷积神经网络离线训练,然后在线实现,以达到实时性能。同时,多模态融合模块通过传感器融合将相关语义数据传输到激光雷达,并随后使用多模态信息来进一步加强分割结果。在定位模块中使用静态信息来寻找机器人姿态,而在全局优化和建图模块中使用静态信息和动态信息来建立3D稠密语义地图。
3.5 DynaVINS(22年8月)
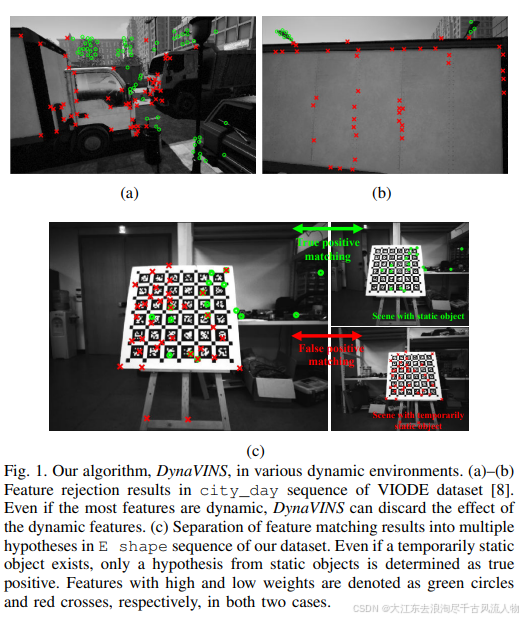
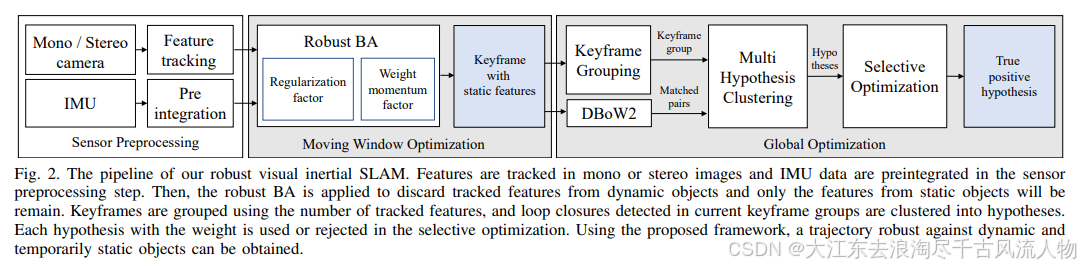
DynaVINS的输入为单目/双目图像和IMU,并进行特征跟踪和IMU预积分。一方面,DynaVINS设计了一个鲁棒BA来从动态对象中丢弃跟踪的特征,保留静态特征。之后使用被追踪特征的数量对关键帧进行分组,并且聚类在当前关键帧组中检测到的回环假设。最后在选择性优化中使用或拒绝具有权重的每个假设,最终获得面向动态和暂时静态对象鲁棒的轨迹。
传统方法的回环检测很难处理临时静止的物体,容易导致假阳性闭环。而且,来自临时静态对象的特征和来自静态对象的特征可能存在于同一个关键帧中。因此,DynaVINS使用了关键帧分组:来自相同特征的回环被分组,即使它们来自不同的关键帧。因此,每个组只使用一个权重,从而实现更快的优化。在对回环进行分组之前,必须对共享最少数量跟踪特征的相邻关键帧进行分组。
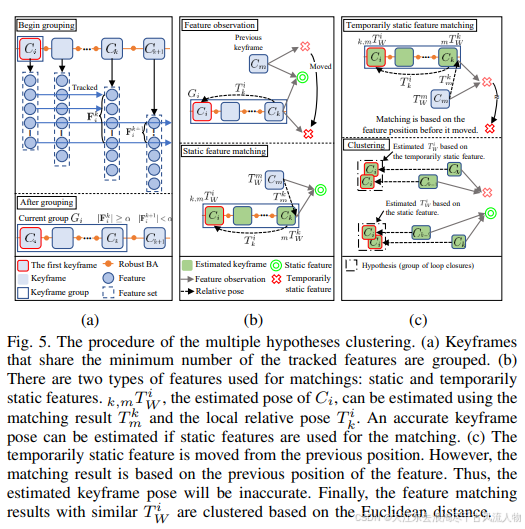
之后,使用DBoW2识别与当前组Gi中的每个关键帧Ck相似的关键帧Cm,如果没有相似关键帧,则跳过Ck。在识别出k最多3个不同的m后,在Ck和这些关键帧之间进行特征匹配,可以得到相对位姿T。如果用于匹配的特征来自同一对象,即使匹配的Ck和Cm不同,匹配的估计位姿也会位于彼此接近的位置。因此,通过计算回环位姿之间的欧氏距离,可以将欧氏距离较小的相似闭环进行聚类。
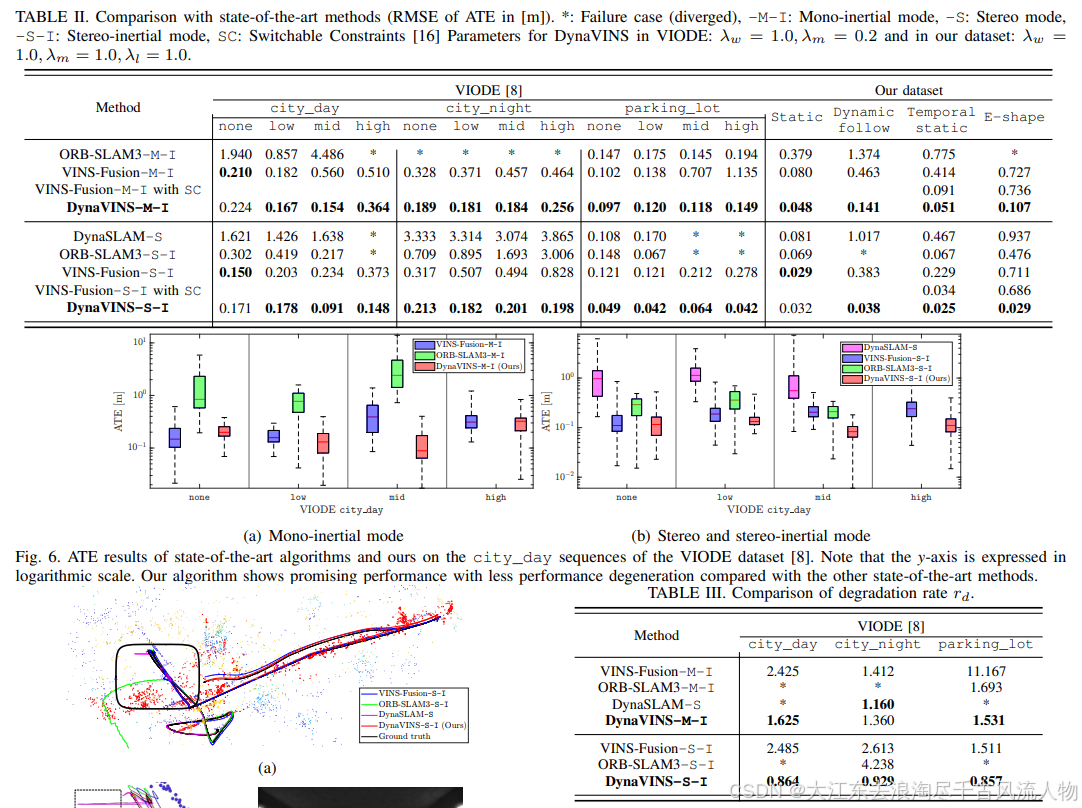
性能提升也很明显,但对比的方案主要是ORB-SLAM3和VINS这种非动态SLAM,对比其他动态SLAM方案的结果还有待验证。
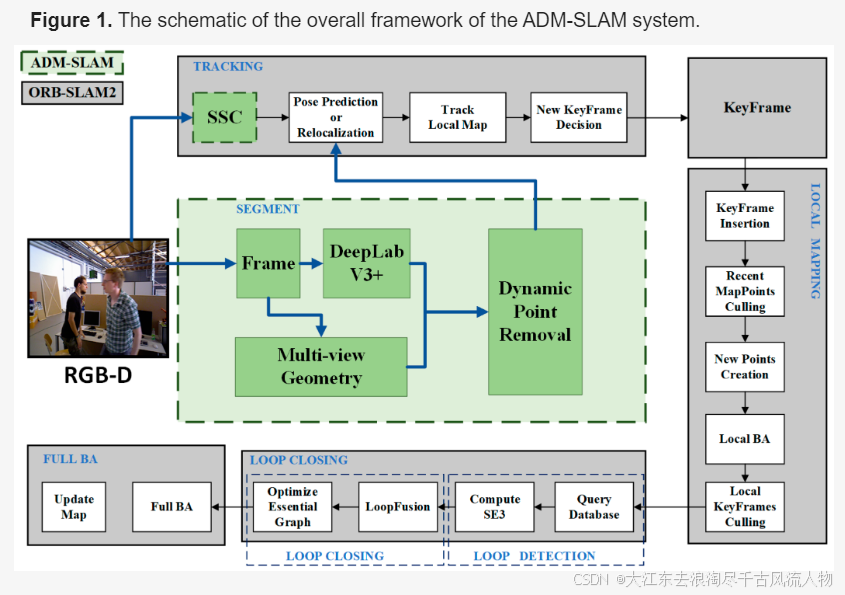
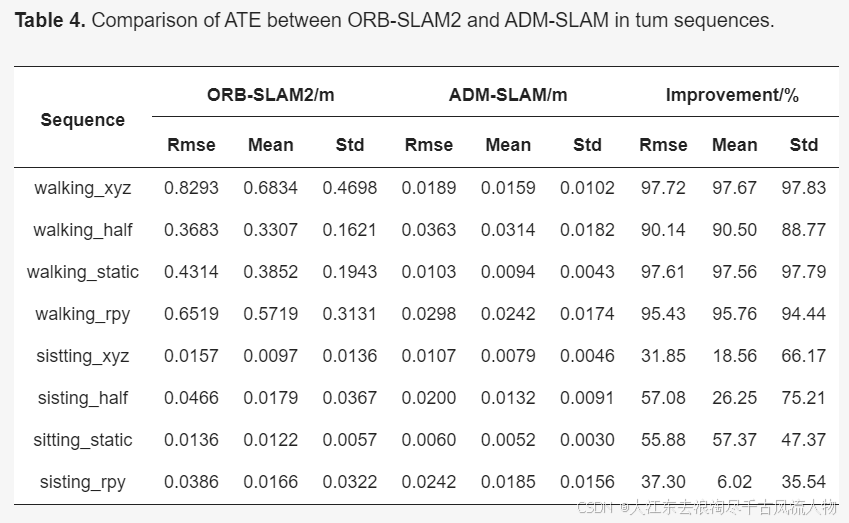
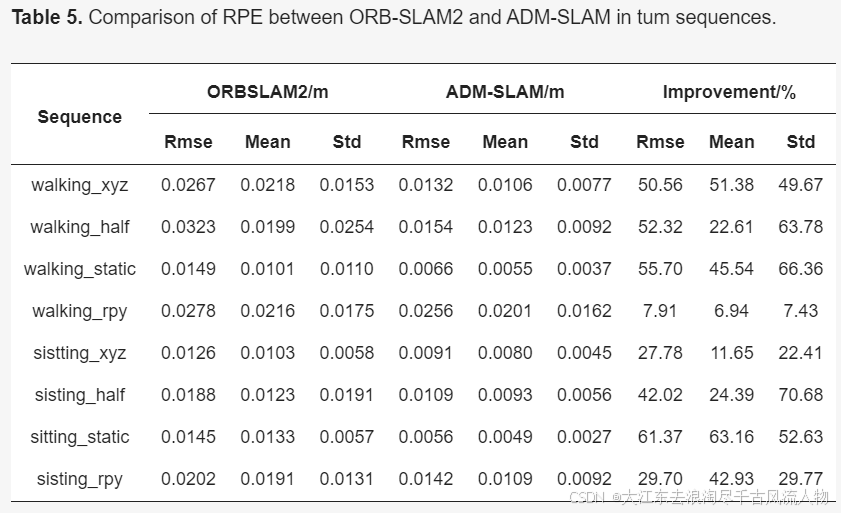
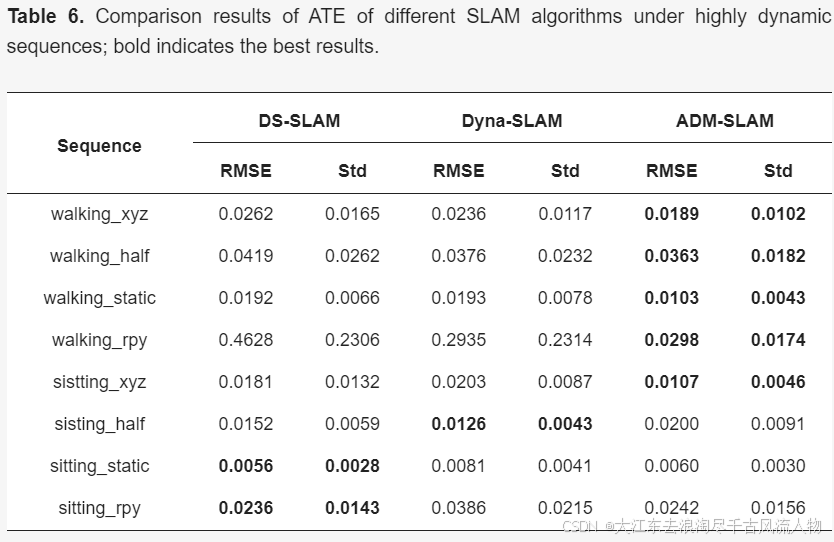
3.6 ADM-SLAM(24年)
视觉同步定位与地图构建(V-SLAM)在智能机器人和自主导航系统的发展中扮演着至关重要的角色。然而,在处理高度动态环境方面仍面临重大挑战。目前环境中用于动态目标识别的普遍方法是深度学习。但是,像Yolov5和Mask R-CNN这样的模型需要大量的计算资源,这限制了它们在实时应用中的潜力,因为受到硬件和时间的限制。为了克服这一限制,本文提出了ADM-SLAM,这是一个为动态环境设计的视图SLAM系统,它建立在ORB-SLAM2的基础上。该系统整合了高效的自适应特征点均匀化提取、基于改进的DeepLabv3的轻量级深度学习语义分割,以及多视图几何分割。它优化了关键帧提取,使用语义分割网络通过上下文信息分割潜在的动态对象,并使用多视图几何方法检测动态对象的运动状态,从而消除动态干扰点。结果表明,ADM-SLAM在动态环境中优于ORB-SLAM2,特别是在高动态场景中,它实现了高达97%的绝对轨迹误差(ATE)降低。在多个高度动态的测试序列中,ADM-SLAM在实时性能和准确性方面优于DS-SLAM和DynaSLAM,证明了其出色的适应性。
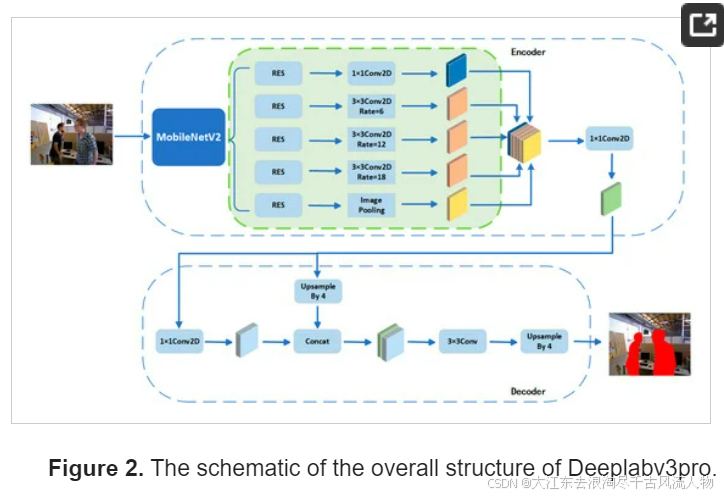
Deeplabv3pro的总体架构
传统的卷积神经网络,特别是在视觉SLAM语义分割任务中,可能会遇到诸如接受场有限、边界定位不准确、处理大规模上下文信息的能力不足和高训练复杂性等问题。这些限制使得网络难以捕捉更广泛的上下文信息和细粒度的对象细节,导致分割结果出现不连续和模糊的边界。Deeplabv3pro是基于改进的Deeplab[34,35]语义分割模型设计的,旨在解决这些问题;总体结构如图2所示。
精度:
3.5 DynaVINS(22年8月)
4. 基于光流/场景流运动分割的动态SLAM
4.1 STDyn-SLAM (20年10月)
除了使用目标检测和语义分割网络进行动态目标识别的SLAM系统外,还有一类动态SLAM是基于光流和场景流分割设计的。
论文链接
代码链接
STDyn-SLAM使用光流、SegNet和深度图来检测动态物体,光流主要用于运动一致性检查。首先会在双目图像中提取ORB特征,然后根据对极几何建立当前帧和上一帧光流。如果不满足对极几何约束,则认为是动态点,需要剔除。
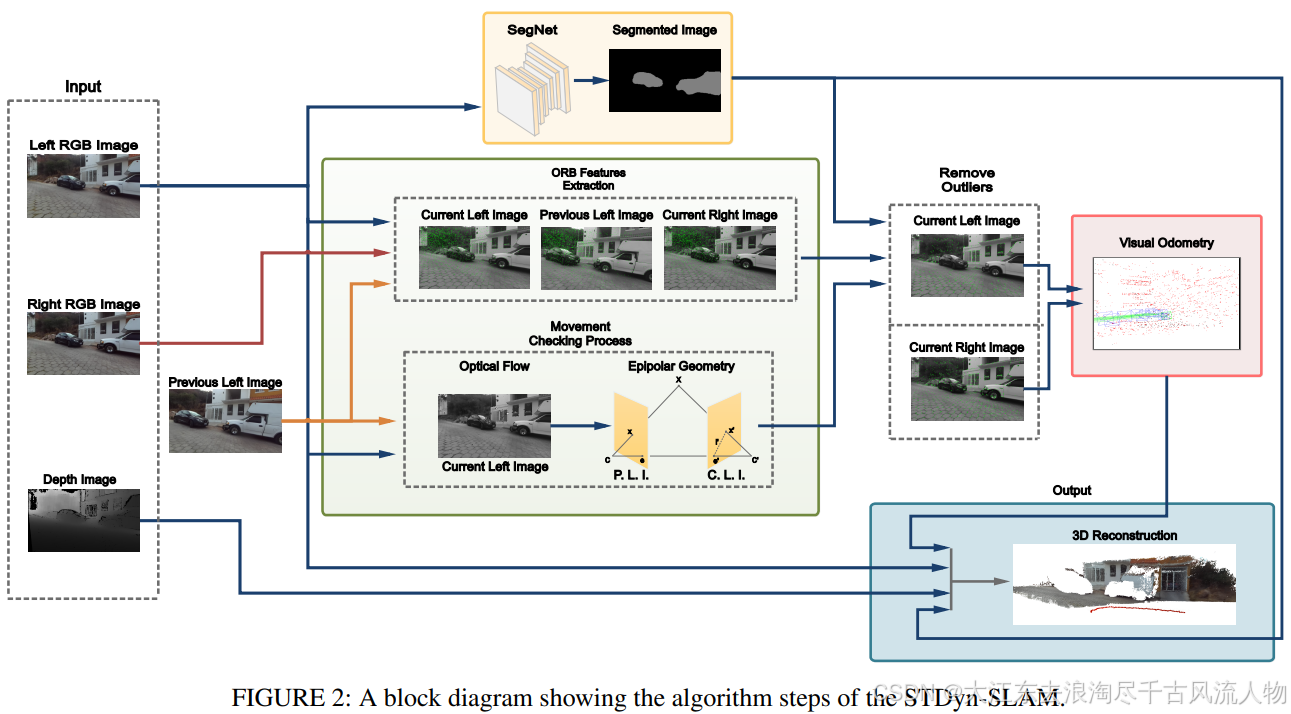
实验还是太少了,KITTI数据集就对比了4个序列,性能也没有多大的提升,而且感觉挑序列进行比较的行为不太可取。
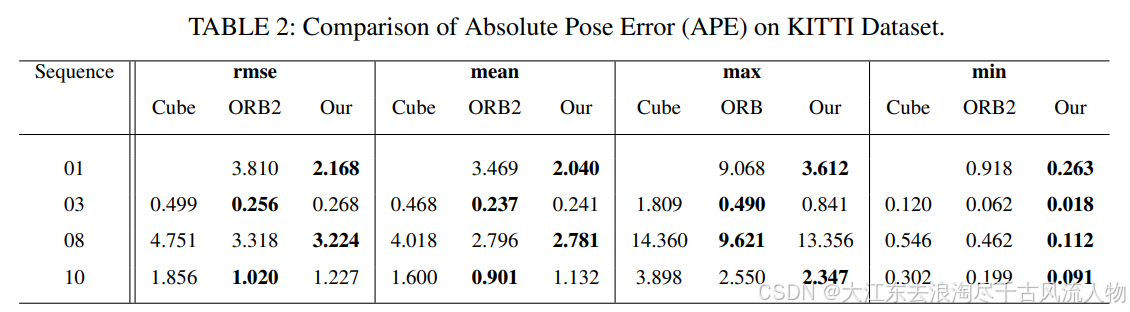
4.2 TartanVO
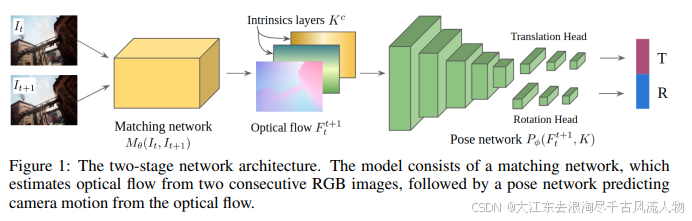
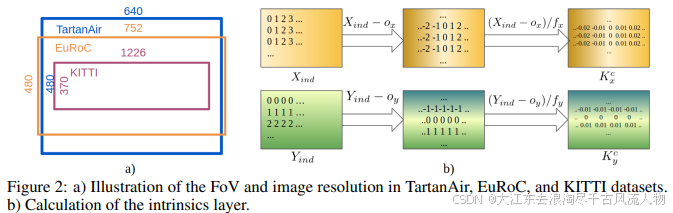
提出了第一个基于学习的可视里程计(VO)模型,该模型能够泛化到多个数据集和真实世界场景中,并在具有挑战性的场景中胜过基于几何的方法。我们通过利用提供大量多样化合成数据的SLAM数据集TartanAir,在具有挑战性的环境中实现这一点。此外,为了使我们的VO模型能够跨数据集泛化,我们提出了一个与尺度相关的损失函数,并将相机的内在参数纳入模型中。实验表明,一个单一的模型,TartanVO,仅在合成数据上训练,无需任何微调,就可以泛化到真实世界的数据集,如KITTI和EuRoC,在具有挑战性的轨迹上显示出比基于几何的方法的显著优势。
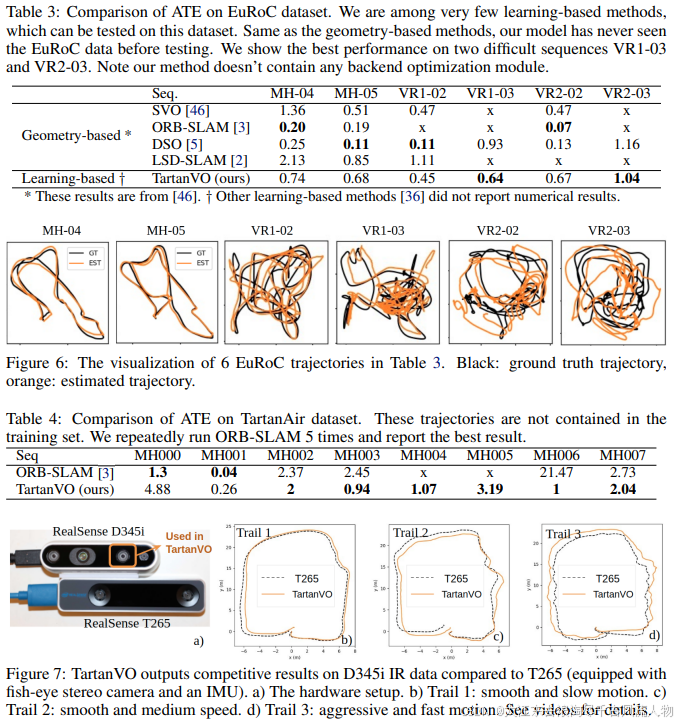
RealSense 数据对比:
我们使用定制的传感器设置收集的数据来测试 TartanVO。如图 7 a) 所示,一个 RealSense D345i 被固定在 RealSense T265 跟踪相机的顶部。我们在我们的模型中使用 D345i 的左侧近红外(IR)图像,并将其与 T265 跟踪相机提供的轨迹进行比较。我们展示了 3 个循环轨迹,这些轨迹遵循相似的路径,运动难度逐渐增加。从图 7 b) 到 d),我们观察到尽管 TartanVO 在训练期间从未见过真实世界图像或 IR 数据,它仍然能够很好地泛化,并预测与 T265 输出非常接近的里程计,T265 是一个专用设备,使用一对鱼眼立体相机和 IMU 来估计相机运动。
结论:
我们提出了 TartanVO,一个可泛化的基于学习的可视里程计。通过用大量数据训练我们的模型,我们展示了多样化数据对模型泛化能力的有效性。通过新定义的与尺度相关的损失函数,可以预期训练和测试损失之间的差距更小,从而进一步提高泛化能力。我们通过广泛的实验表明,配备有专为处理不同相机而设计的内在层,TartanVO 可以泛化到未见过的数据集,并实现甚至比直接在这些数据集上训练的专用学习模型更好的性能。我们的工作引入了许多激动人心的未来研究方向,如可泛化的基于学习的 VIO(视觉惯性里程计)、立体 VO、多帧 VO 等。
4.3 DytanVO(22年9月)
论文链接
代码链接
DytanVO是2023 ICRA的中稿论文,使用刚体运动分割网络RigidMask进行动态光流的提取,之后对动态光流区域的像素做置0操作。但这里有个问题,本身RigidMask是需要图像、场景流、位姿做为输入的,所以DytanVO的主要思想是进行运动分割和位姿解算的联合优化,也就是说将RigidMask输出的优化后的光流分割结果馈送给PoseNet,PoseNet生成的位姿又反过来优化RigidMask的动态物体分割性能,论文里提到迭代3次以后可以收敛,注意光流网络只需要前向推理一次。

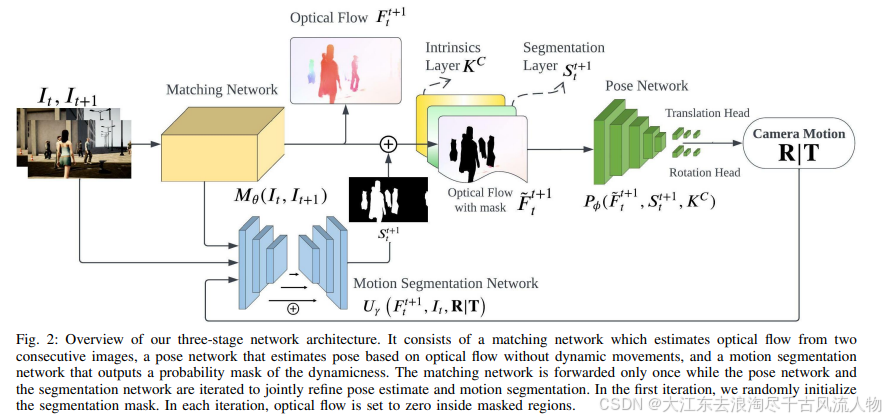
但是DytanVO的创新性其实不是很大,整个网络架构基本就是TartanVO(也是他们实验室之前的工作)和RigidMask组合到了一起。
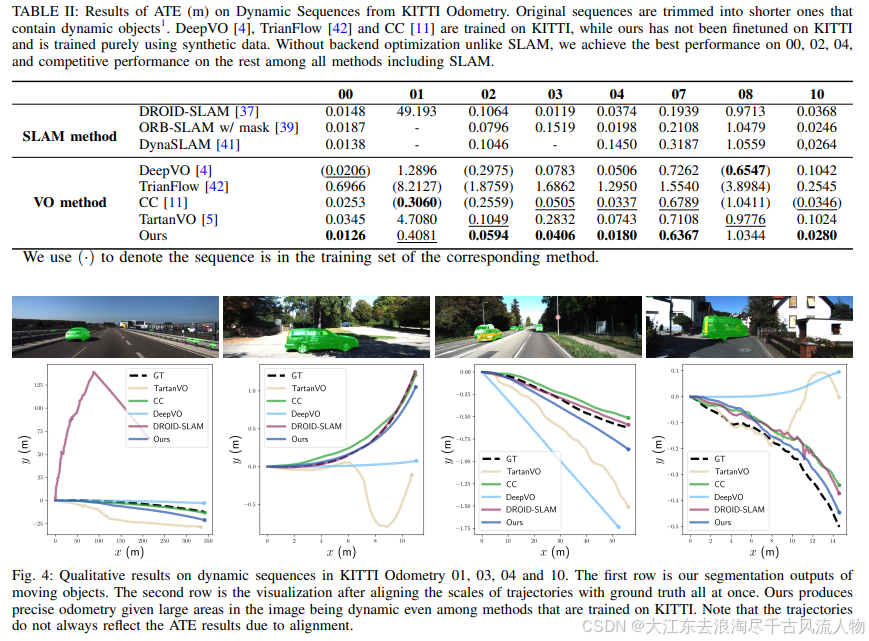
但结果还是很不错的,对比方案也都是AirDOS、VDO-SLAM、DynaSLAM这些动态SLAM,而不是仅仅与静态SLAM对比,在一些场景下的性能甚至超越了DROID-SLAM。
4.4 DS-SLAM
论文链接:Dynamic Dense RGB-D SLAM using Learning-based Visual Odometry
代码链接
严格来说,这不是一篇正经的学术论文,而是一个实验报告。这篇文章是DytanVO的前文工作,感觉像做了一个尝试,但是性能不太好所以没继续做下去,文章里也没有关于位姿精度的定量对比。思路和DytanVO也很像,都是先使用TartanVO估计光流,然后进行运动分割,之后进行运动分割和位姿解算的联合优化。即便如此,笔者认为这篇文章还是有一定的借鉴意义,尤其是它的代码仓库里有很多运动分割部分的代码,可以直接拿过来用,效果也很好。
4.5 MonoRec
MonoRec是2021 CVPR的中稿论文,来自TUM,侧重解决动态场景下的三维重建问题,也就是去除所谓的鬼影。
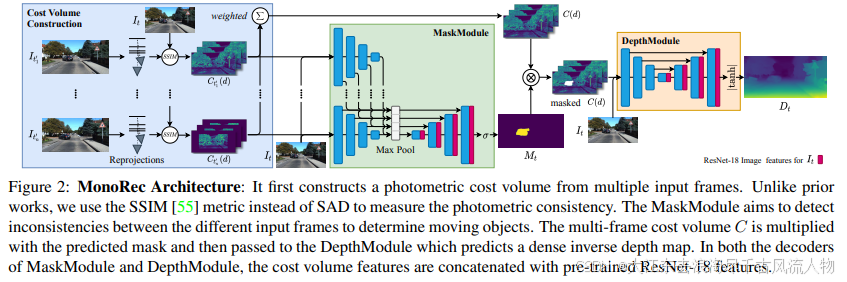
MonoRec是半监督单目稠密重建方案,可以通过单个相机在动态环境中移动来预测深度图。MonoRec基于多视点将多幅连续图像的信息编码在一个代价体中。为了处理场景中的动态对象,引入了一个MaskModule,通过利用编码的光度不一致性来预测移动对象掩码。与其他多视图立体方法不同的是,MonoRec能够利用预测的掩模对静态物体和运动物体进行准确的深度预测。
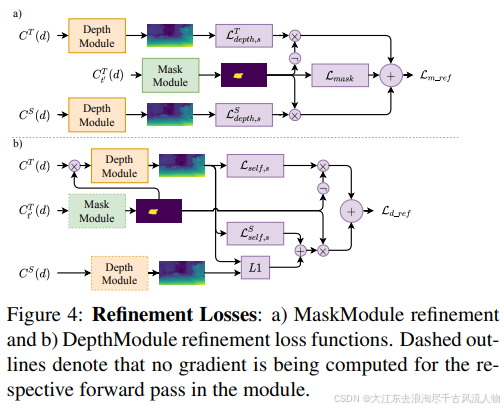
而且MonoRec可以为运动物体和静态背景同时预测深度,而不是简单得将动态物体过滤掉。训练方式也很好,不需要雷达数据,可以进行半监督学习(最近自监督、半监督和弱监督真是越来越火了)。
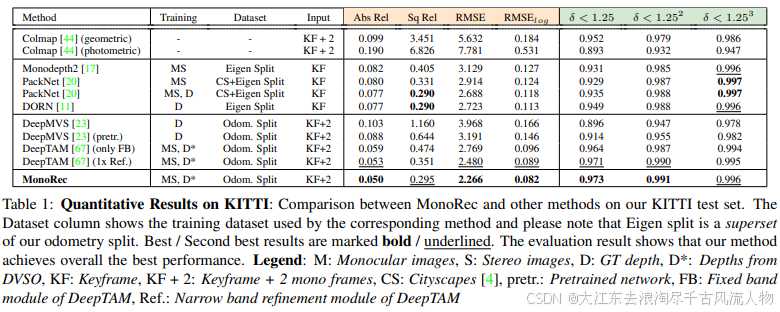
MonoRec在KITTI数据集上获得了SOTA效果,并且在Oxford RobotCar和Tum上的泛化性都不错。
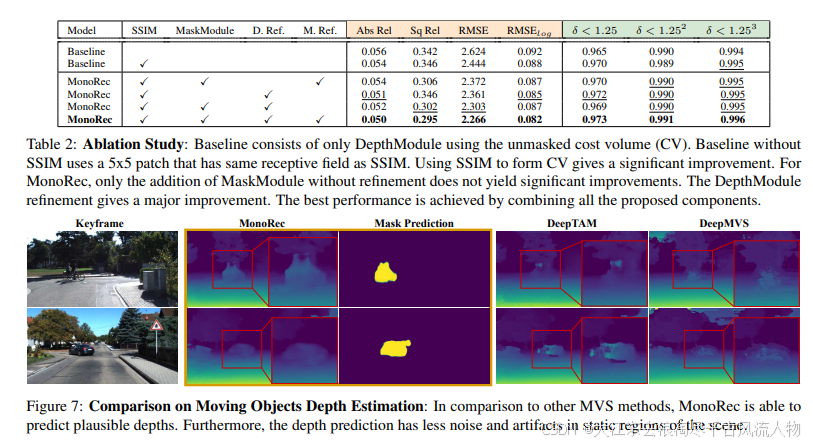
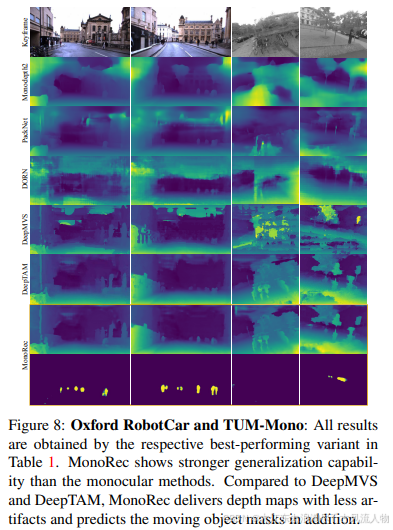
做个简单总结,说实话这方面文章不如基于目标检测和语义分割的多,主要原因是:1、需要多次迭代,对计算性能有要求;2、受到光流本身的影响,稳定性并不如检测。



















 2138
2138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











