







 这篇博客介绍了Mahout聚类的基本概念,包括将数据转换为向量的三种类型:DenseVector, RandomAccessSparseVector, SequentialAccessSparseVector。重点讲述了如何将文本文档通过TF-IDF和n-gram表示为向量,并探讨了多种距离测度方法,如欧式、平方欧式、曼哈顿、余弦和谷本距离,以及归一化在改善向量质量中的作用。"
104670004,4961289,Java:CloseableHttpClient处理gzip连接池问题及解决,"['Java', 'HTTP客户端', 'gzip压缩', '连接管理', '异常处理']
这篇博客介绍了Mahout聚类的基本概念,包括将数据转换为向量的三种类型:DenseVector, RandomAccessSparseVector, SequentialAccessSparseVector。重点讲述了如何将文本文档通过TF-IDF和n-gram表示为向量,并探讨了多种距离测度方法,如欧式、平方欧式、曼哈顿、余弦和谷本距离,以及归一化在改善向量质量中的作用。"
104670004,4961289,Java:CloseableHttpClient处理gzip连接池问题及解决,"['Java', 'HTTP客户端', 'gzip压缩', '连接管理', '异常处理']
聚类的基本概念
聚类就是将一个给定的文档集中的相似项目分成不同簇的过程,可以将簇看作一组簇内相似而簇间有别的项目的集合。
对文档集的聚类涉及以下三件事:
1. 一个算法:将文档集阻止到一起的算法
2. 相似性与不相似的概念
3. 停止的条件
聚类数据的表示
mahout将输入数据以向量的形式保存,在机器学习领域,向量指一个有序的数列,有多个维度,每个维度都有一个值。比如在二维空间,一个坐标就是一个向量。
将数据转换为向量
在mahout中,向量被实现为三个不同的类来针对不同的场景:
1. DenseVector:可以视为一个double型的数组,不管向量是否为0,都会分配空间,被称为密集型的。
2. RandomAccessSparseVector:可以视为一个HashMap(Integer,Double),只为非0元素分配空间,被称为稀疏向量。
3. SequentialAccessSparseVector:实现为两个并列的数组,一个Integer,一个Double,相比于面向随机访问的randomAccessSparseVector,这个更适合顺序读取。
假设有一堆苹果,用形状,大小,颜色作为三个维度来聚类,那么重量可以简单的用克或者千克来测量,大小可以定义小苹果为1,中苹果为2,大苹果为3,颜色可以采取该颜色的波长来表示(400~650nm),这样三个维度就都是一个有意义且客观的维度值,一堆苹果的向量如下:
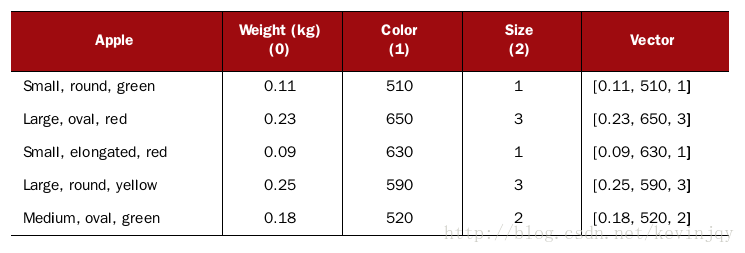
其实有一个问题,那就是颜色的差异在距离测度上大于其他两者,可以通过加权来解决这个问题。
以下为一个为各种苹果生成向量的示例代码:
public static void main(String args[]) throws Exception {
List<NamedVector> apples = new ArrayList<NamedVector>();
NamedVector apple;
//将名字与向量相关联
apple = new NamedVector(
new DenseVector(new double[] {
0.11, 510, 1}),
"Small round green apple");
apples.add(apple);
apple = new NamedVector(
new DenseVector(new double[] {
0.23, 650, 3}),
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 597
597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









