










tee的功能类似重定向, tee前面可以加sudo , 重定向不能加sudo , 这在不能使用root用户时很有用
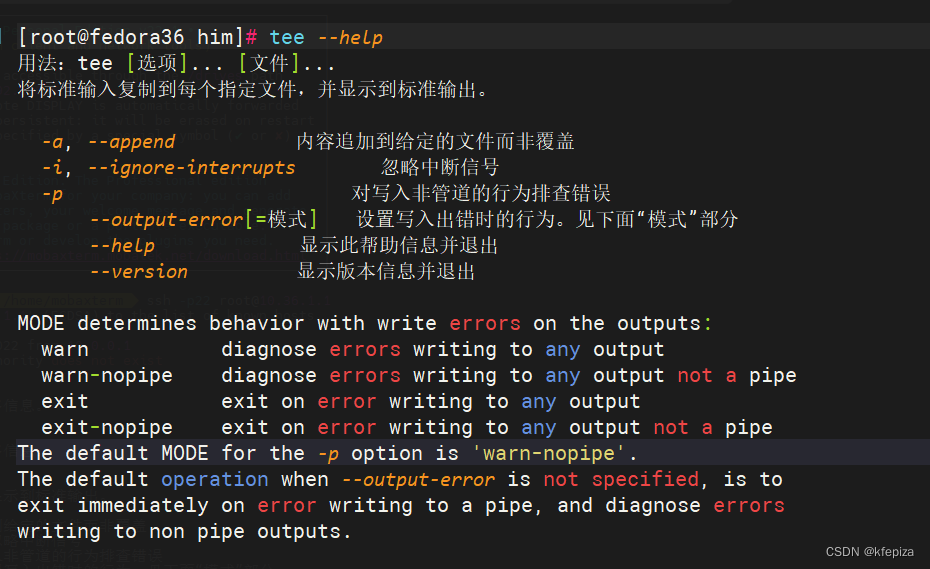
用法:tee [选项]… [文件]…
将标准输入复制到每个指定文件,并显示到标准输出。
-a, --append 内容追加到给定的文件而非覆盖
-i, --ignore-interrupts 忽略中断信号
-p 对写入非管道的行为排查错误
–output-error[=模式] 设置写入出错时的行为。见下面“模式”部分
–help 显示此帮助信息并退出
–version 显示版本信息并退出
模式确定向输出写入出错时的行为:
‘warn’ 对向任何文件输出出错的情况进行诊断
‘warn-nopipe’ 对向除了管道以外的任何文件输出出错的情况进行诊断
‘exit’ 一旦输出出错,则退出程序
‘exit-nopipe’ 一旦输出出错且非管道,则退出程序
-p 选项的默认模式是“warn-nopipe”。
当 --output-error 没有给出时,默认的操作是在向管道写入出错时立刻退出,
且在向非管道写入出错时对问题进行诊断。

Fedora36的tee文档
tee --help
man tee
TEE(1) 用户命令 TEE(1)
名称
tee - 从标准输入读入并写往标准输出和文件
概述
tee [选项]... [文件列表]...
描述
把标准输入的数据复制到文件列表中的每一个文件,同时送往标准输出。
-a, --append
追加到给出的文件,而不是覆盖
-i, --ignore-interrupts
忽略中断信号
-p 对写入非管道的行为排查错误
--output-error[=模式]
设置写入出错时的行为。见下面“模式”部分
--help 显示此帮助信息并退出
--version
显示版本信息并退出
模式确定向输出写入出错时的行为:
'warn' 对向任何文件输出出错的情况进行诊断
'warn-nopipe'
对向除了管道以外的任何文件输出出错的情况进行诊断
'exit' 一旦输出出错,则退出程序
'exit-nopipe'
一旦输出出错且非管道,则退出程序
-p 选项的默认模式是“warn-nopipe”。当 --output-error
没有给出时,默认的操作是在向管道写入出错时立刻退出,且在向非管道写入出错时对问题进行诊断。
作者
由 Mike Parker, Richard M. Stallman 和 David MacKenzie 编写。
报告错误
GNU coreutils 的在线帮助: <https://www.gnu.org/software/coreutils/>
请向 <https://translationproject.org/team/zh_CN.html> 报告翻译错误。
版权
Copyright © 2020 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later
<https://gnu.org/licenses/gpl.html>.
This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law.
参见
完整文档请见: <https://www.gnu.org/software/coreutils/tee>
或者在本地使用: info '(coreutils) tee invocation'
跋
本页面中文版由中文 man 手册页计划提供。
中文 man 手册页计划:https://github.com/man-pages-zh/manpages-zh
GNU coreutils 8.32 2020年三月 TEE(1)
Ubuntu22.04桌面版的tee文档
tee --help
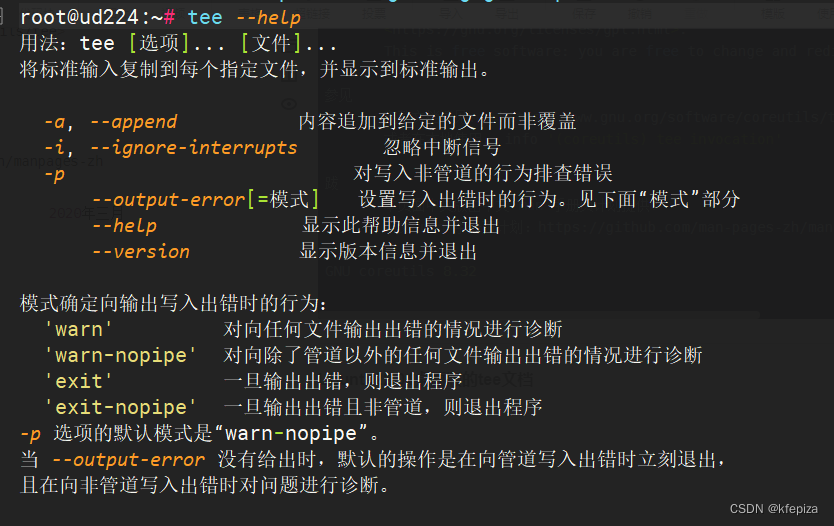
用法:tee [选项]... [文件]...
将标准输入复制到每个指定文件,并显示到标准输出。
-a, --append 内容追加到给定的文件而非覆盖
-i, --ignore-interrupts 忽略中断信号
-p 对写入非管道的行为排查错误
--output-error[=模式] 设置写入出错时的行为。见下面“模式”部分
--help 显示此帮助信息并退出
--version 显示版本信息并退出
模式确定向输出写入出错时的行为:
'warn' 对向任何文件输出出错的情况进行诊断
'warn-nopipe' 对向除了管道以外的任何文件输出出错的情况进行诊断
'exit' 一旦输出出错,则退出程序
'exit-nopipe' 一旦输出出错且非管道,则退出程序
-p 选项的默认模式是“warn-nopipe”。
当 --output-error 没有给出时,默认的操作是在向管道写入出错时立刻退出,
且在向非管道写入出错时对问题进行诊断。
man tee
TEE(1) User Commands TEE(1)
NAME
tee - read from standard input and write to standard output and files
SYNOPSIS
tee [OPTION]... [FILE]...
DESCRIPTION
Copy standard input to each FILE, and also to standard output.
-a, --append
append to the given FILEs, do not overwrite
-i, --ignore-interrupts
ignore interrupt signals
-p diagnose errors writing to non pipes
--output-error[=MODE]
set behavior on write error. See MODE below
--help display this help and exit
--version
output version information and exit
MODE determines behavior with write errors on the outputs:
'warn' diagnose errors writing to any output
'warn-nopipe'
diagnose errors writing to any output not a pipe
'exit' exit on error writing to any output
'exit-nopipe'
exit on error writing to any output not a pipe
The default MODE for the -p option is 'warn-nopipe'. The default operation
when --output-error is not specified, is to exit immediately on error writ‐
ing to a pipe, and diagnose errors writing to non pipe outputs.
AUTHOR
Written by Mike Parker, Richard M. Stallman, and David MacKenzie.
REPORTING BUGS
GNU coreutils online help: <https://www.gnu.org/software/coreutils/>
Report any translation bugs to <https://translationproject.org/team/>
COPYRIGHT
Copyright © 2020 Free Software Foundation, Inc. License GPLv3+: GNU GPL
version 3 or later <https://gnu.org/licenses/gpl.html>.
This is free software: you are free to change and redistribute it. There is
NO WARRANTY, to the extent permitted by law.
SEE ALSO
Full documentation <https://www.gnu.org/software/coreutils/tee>
or available locally via: info '(coreutils) tee invocation'
GNU coreutils 8.32 February 2022 TEE(1)
info tee
File: coreutils.info, Node: tee invocation, Up: Redirection
17.1 ‘tee’: Redirect output to multiple files or processes
==========================================================
The ‘tee’ command copies standard input to standard output and also to
any files given as arguments. This is useful when you want not only to
send some data down a pipe, but also to save a copy. Synopsis:
tee [OPTION]... [FILE]...
If a file being written to does not already exist, it is created. If
a file being written to already exists, the data it previously contained
is overwritten unless the ‘-a’ option is used.
In previous versions of GNU coreutils (v5.3.0 - v8.23), a FILE of ‘-’
caused ‘tee’ to send another copy of input to standard output. However,
as the interleaved output was not very useful, ‘tee’ now conforms to
POSIX which explicitly mandates it to treat ‘-’ as a file with such
name.
The program accepts the following options. Also see *note Common
options::.
‘-a’
‘--append’
Append standard input to the given files rather than overwriting
them.
‘-i’
‘--ignore-interrupts’
Ignore interrupt signals.
‘-p’
‘--output-error[=MODE]’
Adjust the behavior with errors on the outputs, with the long form
option supporting selection between the following MODEs:
‘warn’
Warn on error opening or writing any output, including pipes.
Writing is continued to still open files/pipes. Exit status
indicates failure if any output has an error.
‘warn-nopipe’
This is the default MODE when not specified, or when the short
form ‘-p’ is used. Warn on error opening or writing any
output, except pipes. Writing is continued to still open
files/pipes. Exit status indicates failure if any non pipe
output had an error.
‘exit’
Exit on error opening or writing any output, including pipes.
‘exit-nopipe’
Exit on error opening or writing any output, except pipes.
The ‘tee’ command is useful when you happen to be transferring a
large amount of data and also want to summarize that data without
reading it a second time. For example, when you are downloading a DVD
image, you often want to verify its signature or checksum right away.
The inefficient way to do it is simply:
wget https://example.com/some.iso && sha1sum some.iso
One problem with the above is that it makes you wait for the download
to complete before starting the time-consuming SHA1 computation.
Perhaps even more importantly, the above requires reading the DVD image
a second time (the first was from the network).
The efficient way to do it is to interleave the download and SHA1
computation. Then, you’ll get the checksum for free, because the entire
process parallelizes so well:
# slightly contrived, to demonstrate process substitution
wget -O - https://example.com/dvd.iso \
| tee >(sha1sum > dvd.sha1) > dvd.iso
That makes ‘tee’ write not just to the expected output file, but also
to a pipe running ‘sha1sum’ and saving the final checksum in a file
named ‘dvd.sha1’.
Note, however, that this example relies on a feature of modern shells
called “process substitution” (the ‘>(command)’ syntax, above; *Note
Process Substitution: (bash)Process Substitution.), so it works with
‘zsh’, ‘bash’, and ‘ksh’, but not with ‘/bin/sh’. So if you write code
like this in a shell script, be sure to start the script with
‘#!/bin/bash’.
Note also that if any of the process substitutions (or piped stdout)
might exit early without consuming all the data, the ‘-p’ option is
needed to allow ‘tee’ to continue to process the input to any remaining
outputs.
Since the above example writes to one file and one process, a more
conventional and portable use of ‘tee’ is even better:
wget -O - https://example.com/dvd.iso \
| tee dvd.iso | sha1sum > dvd.sha1
You can extend this example to make ‘tee’ write to two processes,
computing MD5 and SHA1 checksums in parallel. In this case, process
substitution is required:
wget -O - https://example.com/dvd.iso \
| tee >(sha1sum > dvd.sha1) \
>(md5sum > dvd.md5) \
> dvd.iso
This technique is also useful when you want to make a _compressed_
copy of the contents of a pipe. Consider a tool to graphically
summarize disk usage data from ‘du -ak’. For a large hierarchy, ‘du
-ak’ can run for a long time, and can easily produce terabytes of data,
so you won’t want to rerun the command unnecessarily. Nor will you want
to save the uncompressed output.
Doing it the inefficient way, you can’t even start the GUI until
after you’ve compressed all of the ‘du’ output:
du -ak | gzip -9 > /tmp/du.gz
gzip -d /tmp/du.gz | xdiskusage -a
With ‘tee’ and process substitution, you start the GUI right away and
eliminate the decompression completely:
du -ak | tee >(gzip -9 > /tmp/du.gz) | xdiskusage -a
Finally, if you regularly create more than one type of compressed
tarball at once, for example when ‘make dist’ creates both
‘gzip’-compressed and ‘bzip2’-compressed tarballs, there may be a better
way. Typical ‘automake’-generated ‘Makefile’ rules create the two
compressed tar archives with commands in sequence, like this (slightly
simplified):
tardir=your-pkg-M.N
tar chof - "$tardir" | gzip -9 -c > your-pkg-M.N.tar.gz
tar chof - "$tardir" | bzip2 -9 -c > your-pkg-M.N.tar.bz2
However, if the hierarchy you are archiving and compressing is larger
than a couple megabytes, and especially if you are using a
multi-processor system with plenty of memory, then you can do much
better by reading the directory contents only once and running the
compression programs in parallel:
tardir=your-pkg-M.N
tar chof - "$tardir" \
| tee >(gzip -9 -c > your-pkg-M.N.tar.gz) \
| bzip2 -9 -c > your-pkg-M.N.tar.bz2
If you want to further process the output from process substitutions,
and those processes write atomically (i.e., write less than the system’s
PIPE_BUF size at a time), that’s possible with a construct like:
tardir=your-pkg-M.N
tar chof - "$tardir" \
| tee >(md5sum --tag) > >(sha256sum --tag) \
| sort | gpg --clearsign > your-pkg-M.N.tar.sig
An exit status of zero indicates success, and a nonzero value
indicates failure.
File: coreutils.info, Node: tee invocation, Up: Redirection
17.1 ‘tee’: Redirect output to multiple files or processes
The ‘tee’ command copies standard input to standard output and also to
any files given as arguments. This is useful when you want not only to
send some data down a pipe, but also to save a copy. Synopsis:
tee [OPTION]... [FILE]...
If a file being written to does not already exist, it is created. If
a file being written to already exists, the data it previously contained
is overwritten unless the ‘-a’ option is used.
In previous versions of GNU coreutils (v5.3.0 - v8.23), a FILE of ‘-’
caused ‘tee’ to send another copy of input to standard output. However,
as the interleaved output was not very useful, ‘tee’ now conforms to
POSIX which explicitly mandates it to treat ‘-’ as a file with such
name.
The program accepts the following options. Also see *note Common
options::.
‘-a’
‘–append’
Append standard input to the given files rather than overwriting
them.
‘-i’
‘–ignore-interrupts’
Ignore interrupt signals.
‘-p’
‘–output-error[=MODE]’
Adjust the behavior with errors on the outputs, with the long form
option supporting selection between the following MODEs:
‘warn’
Warn on error opening or writing any output, including pipes.
Writing is continued to still open files/pipes. Exit status
indicates failure if any output has an error.
‘warn-nopipe’
This is the default MODE when not specified, or when the short
form ‘-p’ is used. Warn on error opening or writing any
output, except pipes. Writing is continued to still open
files/pipes. Exit status indicates failure if any non pipe
output had an error.
‘exit’
Exit on error opening or writing any output, including pipes.
‘exit-nopipe’
Exit on error opening or writing any output, except pipes.
The ‘tee’ command is useful when you happen to be transferring a
large amount of data and also want to summarize that data without
reading it a second time. For example, when you are downloading a DVD
image, you often want to verify its signature or checksum right away.
The inefficient way to do it is simply:
wget https://example.com/some.iso && sha1sum some.iso
One problem with the above is that it makes you wait for the download
to complete before starting the time-consuming SHA1 computation.
Perhaps even more importantly, the above requires reading the DVD image
a second time (the first was from the network).
The efficient way to do it is to interleave the download and SHA1
computation. Then, you’ll get the checksum for free, because the entire
process parallelizes so well:
# slightly contrived, to demonstrate process substitution
wget -O - https://example.com/dvd.iso \
| tee >(sha1sum > dvd.sha1) > dvd.iso
That makes ‘tee’ write not just to the expected output file, but also
to a pipe running ‘sha1sum’ and saving the final checksum in a file
named ‘dvd.sha1’.
Note, however, that this example relies on a feature of modern shells
called “process substitution” (the ‘>(command)’ syntax, above; *Note
Process Substitution: (bash)Process Substitution.), so it works with
‘zsh’, ‘bash’, and ‘ksh’, but not with ‘/bin/sh’. So if you write code
like this in a shell script, be sure to start the script with
‘#!/bin/bash’.
Note also that if any of the process substitutions (or piped stdout)
might exit early without consuming all the data, the ‘-p’ option is
needed to allow ‘tee’ to continue to process the input to any remaining
outputs.
Since the above example writes to one file and one process, a more
conventional and portable use of ‘tee’ is even better:
wget -O - https://example.com/dvd.iso \
| tee dvd.iso | sha1sum > dvd.sha1
You can extend this example to make ‘tee’ write to two processes,
computing MD5 and SHA1 checksums in parallel. In this case, process
substitution is required:
wget -O - https://example.com/dvd.iso \
| tee >(sha1sum > dvd.sha1) \
>(md5sum > dvd.md5) \
> dvd.iso
This technique is also useful when you want to make a compressed
copy of the contents of a pipe. Consider a tool to graphically
summarize disk usage data from ‘du -ak’. For a large hierarchy, ‘du
-ak’ can run for a long time, and can easily produce terabytes of data,
so you won’t want to rerun the command unnecessarily. Nor will you want
to save the uncompressed output.
Doing it the inefficient way, you can’t even start the GUI until
after you’ve compressed all of the ‘du’ output:
du -ak | gzip -9 > /tmp/du.gz
gzip -d /tmp/du.gz | xdiskusage -a
With ‘tee’ and process substitution, you start the GUI right away and
eliminate the decompression completely:
du -ak | tee >(gzip -9 > /tmp/du.gz) | xdiskusage -a
Finally, if you regularly create more than one type of compressed
tarball at once, for example when ‘make dist’ creates both
‘gzip’-compressed and ‘bzip2’-compressed tarballs, there may be a better
way. Typical ‘automake’-generated ‘Makefile’ rules create the two
compressed tar archives with commands in sequence, like this (slightly
simplified):
tardir=your-pkg-M.N
tar chof - "$tardir" | gzip -9 -c > your-pkg-M.N.tar.gz
tar chof - "$tardir" | bzip2 -9 -c > your-pkg-M.N.tar.bz2
However, if the hierarchy you are archiving and compressing is larger
than a couple megabytes, and especially if you are using a
multi-processor system with plenty of memory, then you can do much
better by reading the directory contents only once and running the
compression programs in parallel:
tardir=your-pkg-M.N
tar chof - "$tardir" \
| tee >(gzip -9 -c > your-pkg-M.N.tar.gz) \
| bzip2 -9 -c > your-pkg-M.N.tar.bz2
If you want to further process the output from process substitutions,
and those processes write atomically (i.e., write less than the system’s
PIPE_BUF size at a time), that’s possible with a construct like:
tardir=your-pkg-M.N
tar chof - "$tardir" \
| tee >(md5sum --tag) > >(sha256sum --tag) \
| sort | gpg --clearsign > your-pkg-M.N.tar.sig
An exit status of zero indicates success, and a nonzero value
indicates failure.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











