





图像处理,图形学,CV的很多问题都可以概括为将输入图像转化为相应的输出图像,文章就是提出了一个针对这些问题的共同框架。CNN学习的目标是为了最小化损失函数(用于评估结果),尽管学习的过程是自动的,但有效的损失函数设计需要人工来参与,需要我们告诉CNN什么是我们想要最小化的。比如一个天真的方法就是采用最小化预测数据和ground truth之间的欧式距离(通过平均所有合理的输出来最小化),但这样容易产生模糊的结果。提出一个有效的损失函数来使CNN做我们想要的,是一个开放性的问题并且需要专业的知识。
如果我们能指定一个高级别的目标(比如使得输出的图像和真实图像无法区分),然后自动学习适合于达到这个目标的损失函数,这是非常可取的。GAN网络学习一个用于判别输出图像真伪的loss,同时训练一个生成器来最小化这个loss,很好地实现了这个目标。文章证明了,针对各式各样的问题,conditional GAN都能产生合理的结果;提出了一个足以产生理想结果的简单框架,并对比分析了几个重要的框架。
图像到图像的转换问题通常按照像素分类或回归方式来制定。输出空间通常被认为是一个无组织的结构,对于给定的输入图像,输出的每个像素都独立于其他所有的像素。conditional GAN学习一个结构化损失来惩罚输出的联合配置。和其他考虑了结构化损失的方法不同,conditional GAN的损失是可以学习的,并且在理论上可以惩罚输出与目标之间任意可能的结构。conditional GAN的框架不是为特定应用而设计的,所以结构设计起来比大多数方法简单得多。 在生成器和判别器的选择上,conditional GAN有别于之前的结构,生成器使用的是一个“U-Net”的基础架构;判别器使用的是卷积的“PatchGAN”分类器,惩罚结构只作用在图像的patches块上。
GAN的生成模型是学习一个从随机噪声z到输出图像y的映射G:z->y;而conditional GAN的生成模型是学习从观测图像x和随机噪声z到y之间的映射G:{x,z}->y。conditional GAN训练过程如下图所示:
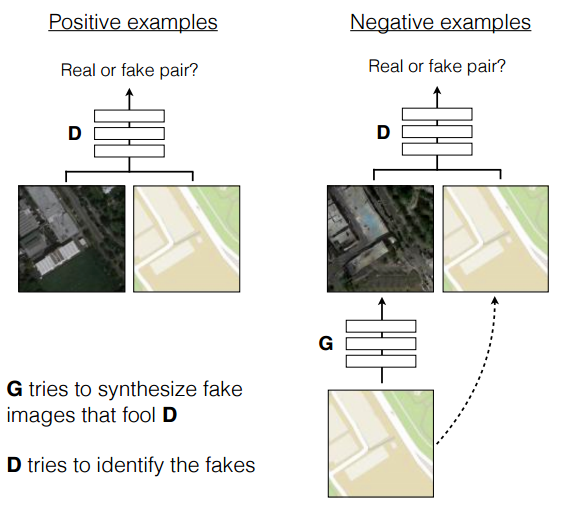
判别器D不断学习以区分真实图像和合成的图像;生成器G不断学习以蒙蔽D。D和G都有对输入图像x进行观察。
conditional GAN的目标函数如下:
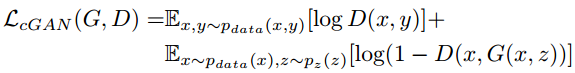
G不断学习来最小化目标函数,D则不断最大化目标函数,优化函数如下:
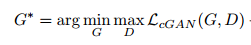
为了验证添加条件对判别器D的重要性,和没有条件变量(观察值x)的模型做比较:
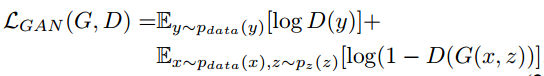
先前的方法通过混合了GAN目标函数和一个传统的损失(如L2 distance)得到更好的结果来验证conditional GANs是有效的。判别器的任务保持不变,而生成器不仅要蒙蔽判别器,还要使得output在L2 distance上逼近ground truth。与L2相比,文章采用了模糊更少的L1 distance:
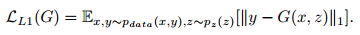
所以,最终的目标函数如下:
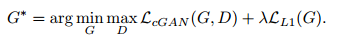
没有z,网络仍然可以学习从x到y的映射,但会产生确定性输出,因此不能匹配除delta函数之外的任何分布。最终的模型以dropout的形式来产生噪声,并在train和test期间将这些噪声应用到生成器的某些层中。尽管利用dropout来产生噪声,但网络的输出的随机性却很小。文章的重要工作就是设计产生随机输出的条件GAN,从而捕获其模型的条件分布的完整熵。
!!!图像到图像转换问题的一个特征定义是将高分辨率输入网格映射到高分辨率输出网格。输入和输出的表面外观虽不同,但两者都是相同底层结构的渲染。因此,生成器的设计中输入的结构大致与输出的结构对齐。
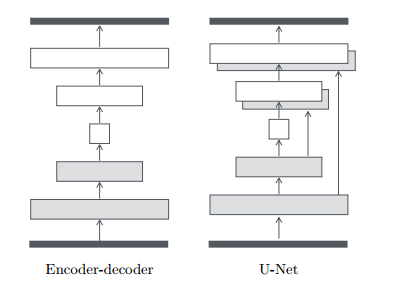
之前的结构都是基于如下图的编码-解码网络,先经过几个降采样层,到达一个瓶颈后经过一个逆过程得到最终的输出。网络要求所有的信息流通过网络的所有层。对于许多图像翻译问题,输入和输出之间共享了大量低级别的信息,因此最好将这些信息直接穿过网络。为了使得生成器能够规避这样的信息瓶颈,遵循“U-Net”的形状,添加跳跃连接。假使网络有n层,网络的第i层都和n-i层有一个连接:
众所周知,L2损失和L1损失在图像生成问题上容易产生模糊的结果。虽然这两个损失不能支持高频脆性,但是在大多数情况下仍能准确地捕获低频。 对于出现这种情况的问题,我们不需要一个全新的框架来提高在低频率下的准确率。 因为这事L1已经做了。

那么只能通过对高频结构进行建模来限制GAN判别器,并依靠L1项来保证低频的准确率。为了对高频进行建模,只需将注意力限制在图像局部块的结构上。因此我们设计了一个判别器,只在patches的尺度上加入惩罚结构,用来判别图像中一个N×N的局部块是真是假。用判别器对整张图像进行卷积,并平均所有的响应来得到最终的输出D。其中,N可以比图像的全尺寸小得多,也仍能产生高质量的结果。这是因为更小的PatchGAN有着更少的参数,跑得更快,并且能够应用到任意大小的图像中。这样的判别器有效地将图像建模为一个马尔可夫随机场,假定距离大于patch块直径的元素间是相互独立的。这种联系以前是探索过的,也是纹理和风格模型中的常见假设。 因此,我们的PatchGAN可以被理解为纹理/风格损失的一种形式。
优化过程交替对D和G进行梯度下降,使用minibatch SGD和Adam求解。在推论阶段,使用训练阶段相同的方法来运行生成器。与通常的协议不同,我们在测试期间应用dropout,并使用test batch的统计信息来应用batch normalization,而不是聚合training batch的统计信息。当batchsize设为1时,batch Normalization就相当于instangce Normalization,这对于图像生成任务来说是更有效的。














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









