







 本文介绍pix2pix方法,它基于GAN对抗性训练,与cycleGAN相对,使用已配对训练集。生成器采用U-net架构,用于特征提取和上采样生成高质量图像;鉴别器使用PatchGAN,对图像patch进行识别。U-net有跳跃连接融合多尺度特征,PatchGAN可生成高频不模糊图像。
本文介绍pix2pix方法,它基于GAN对抗性训练,与cycleGAN相对,使用已配对训练集。生成器采用U-net架构,用于特征提取和上采样生成高质量图像;鉴别器使用PatchGAN,对图像patch进行识别。U-net有跳跃连接融合多尺度特征,PatchGAN可生成高频不模糊图像。
前言
这篇文章俗称pix2pix(即像素映射到像素),和上一篇cycleGAN是相对的,本文用的是已配对的训练集,而cycleGAN是无配对的训练集。
本文的思想依然是GAN对抗性训练,生成器网络架构为U-net,压缩路径用于特征提取获取上下文信息,扩展路径用于上采样精确定位生成高质量图像。鉴别器网络架构为patchGAN用于对分成N*N个patch的图像每个patch进行识别,再取平均值。
同时,U-net有跳跃连接,使得上采样部分会融合特征提取部分的输出,这样做实际上是将多尺度特征融合在了一起,以最后一个上采样为例,它的特征既来自第一个卷积block的输出(同尺度特征),也来自上采样的输出(大尺度特征)。
Introduction
在GAN中,我们通过随机噪声得到的图像是随机的,不能根据我们的需求生成对应的图像。而pix2pix弥补了这项缺陷。
pix2pix可以理解为输入一张简单图像,得到对应的具体的输出图像,比如,给定一张猫的素描边框照片,得到这只猫的具体图片。即以输入图像为条件并生成相应的输出图像。
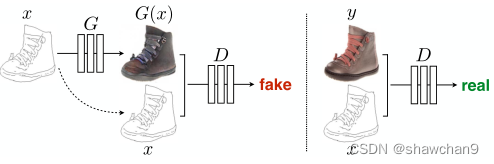
图2.训练一个条件GAN来映射边缘图像x→照片。鉴别器D学习在假元组(由生成器合成)和真元组{边缘x, photo}之间进行分类。生成器G学会了欺骗鉴别器。与无条件GAN不同,生成器和鉴别器都观察输入边映射x。
本文的生成器使用基于“U-Net”的架构,鉴别器使用了卷积“PatchGAN”分类器,它只在图像patch的规模上惩罚结构。
Method
CGAN学习从观察图像x和随机噪声向量z到y, 即G: {x, z}→y的映射。
3.1.Objective
CGAN的目标可以表示为:
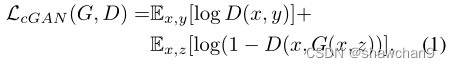
G试图最小化这个目标,而D试图最大化。
为了测试条件化鉴别器的重要性,我们还比较了鉴别器不观察x的无条件变体:
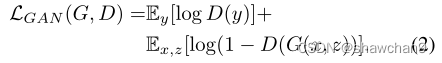
生成器的任务不仅是欺骗鉴别器D,还有生成质量和分辨率更高的图像。使得在L2意义上接近全真图像输出。我们使用L1距离而不是L2距离,因为L1鼓励更少的模糊:
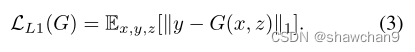
最终目标函数为:
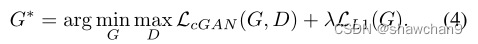
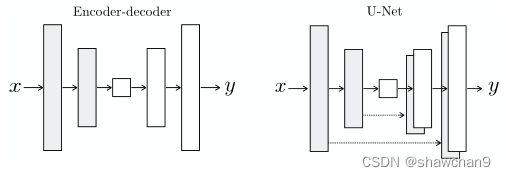
图3:生成器G架构的两种选择。“U-Net”是一种编码器-解码器,在编码器和解码器堆栈中的对称的层之间具有跳跃连接。
Network architectures
生成器和鉴别器都使用卷积- batchnorm - relu形式的模块.
U-net
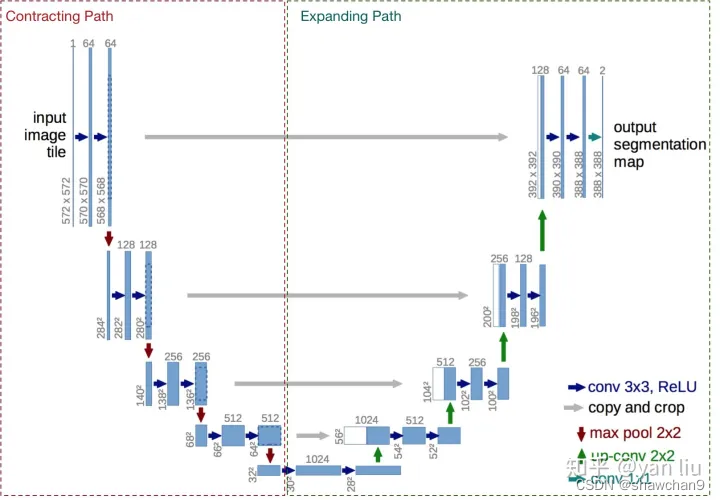
图1.U-Net网络结构图
(1)网络的左侧(红色虚线)是由卷积和Max Pooling构成的一系列降采样操作,将这一部分叫做压缩路径(contracting path)。压缩路径由4个block组成,每个block使用了2个有效卷积和1个Max Pooling降采样,每次降采样之后Feature Map的个数乘2(通道数乘2)。
(2)网络的右侧部分(绿色虚线)在论文中叫做扩展路径(expansive path)。同样由4个block组成,每个block开始之前通过反卷积将Feature Map的尺寸乘2,同时将其个数减半(个数减半的话还需要卷积来实现)(最后一层略有不同),然后和左侧对称的压缩路径的Feature Map合并,由于左侧压缩路径和右侧扩展路径的Feature Map的尺寸不一样,U-Net是通过将压缩路径的Feature Map裁剪到和扩展路径相同尺寸的Feature Map进行归一化的(即图1中左侧虚线部分)。扩展路径的卷积操作依旧使用的是有效卷积操作,最终得到的Feature Map的尺寸是388*388。由于该任务是一个二分类任务,所以网络有两个输出Feature Map。
收缩路径用于获取上下文信息(context),作用是特征提取,扩张路径上采样用于精确的定位,生成精密的图像(localization),且两条路径相互对称。
U-net采用了完全不同的特征融合方式:拼接(Concat),U-Net采用将特征在channel维度拼接在一起,形成更厚的特征。而FCN融合时使用的对应点相加,并不形成更厚的特征。
U-net镜像操作
数据集原始图像尺寸是512512的,最终输出图像是388388的.因为有效卷积是会降低Feature Map分辨率的,但是我们希望512*512的图像的边界点能够保留到最后一层Feature Map。
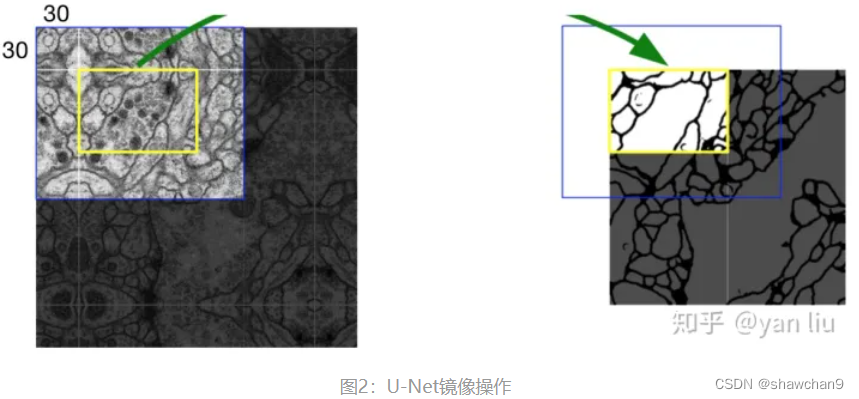
镜像操作即是给输入图像加入一个对称的边(图2),那么边的宽度是多少呢?一个比较好的策略是通过感受野确定。增加的尺寸即是感受野的大小,也就是说每条边界增加感受野的一半作为镜像边。
根据图1中所示的压缩路径的网络架构,我们可以计算其感受野:
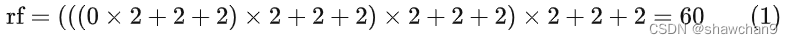
PatchGAN(马尔科夫鉴别器)
为了生成高频的不模糊图像,将我们的关注点限制在局部图像块中的结构就足够了。
本文设计了名为PatchGAN的鉴别器结构,只在patch的规模上进行鉴别。
这个鉴别器尝试分类图像中的每个N × N 的patch是真的还是假的。我们在整个图像中卷积地运行这个鉴别器,平均所有响应以提供D的最终输出。4.4节实验结果显示,仍可得到高质量的结果。
较小的PatchGAN具有更少的参数,运行更快,并且可以应用于任意大的图像。
Appendix Network architectures
设Ck表示具有k个过滤器的卷积-batchnorm-relu层,CDk表示卷积-batchnorm-dropout-relu层。所有卷积都是4 × 4空间滤波器,stride为2。
Generator architectures
生成器架构为U-net,
encoder为C64-C128-C256-C512-C512-C512-C512-C512,Batchnorm并不应用于第一个C64层。
decoder为CD512-CD512-CD512-C512-C256-
C128-C64,
在解码器的最后一层之后,应用卷积来映射到输出通道的数量(一般是3,除了着色,它是2),然后是一个Tanh函数。
编码器中的所有relu都是leaky的,斜率为0.2,而解码器中的relu则不是leaky。
Discriminator architectures
7070PatchGAN鉴别器架构为:
C64-C128-C256-C512
在最后一层,用卷积映射到1维输出,然后是Sigmoid函数。
BatchNorm并不应用于第一个C64层。所有relu都是leaky的,斜率为0.2。
1616鉴别器为:
C64-C128
286*286鉴别器:
C64-C128-C256-C512-C512-C512


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









