






 本文探讨了一种通用的图像到图像转换框架,利用CGAN结合U-Net生成器和PatchGAN分类器,优化L1损失与GAN结构。研究了不同损失函数对生成质量的影响,并通过ATM和FCN-Score评估模型性能。实验涉及上色、特征生成和图像生成任务,揭示了L1在保持清晰度时的局限性与cGAN的优点。
本文探讨了一种通用的图像到图像转换框架,利用CGAN结合U-Net生成器和PatchGAN分类器,优化L1损失与GAN结构。研究了不同损失函数对生成质量的影响,并通过ATM和FCN-Score评估模型性能。实验涉及上色、特征生成和图像生成任务,揭示了L1在保持清晰度时的局限性与cGAN的优点。
- Introduction
找到一个统一的框架来处理从图片生成图片(image-to-image translation)的任务,其中包含由label map合成图片,由eage maps 重建目标,图片上色。
- Related Work
CNN存在的问题:人工干预如何最小化损失。如果计算预测图片和真实图片的欧氏距离,结果将会非常模糊,因为欧氏距离在最小化看似正确的结果的平均值,这会导致结果模糊。
本文基于CGAN,将输入图像作为条件,生成与之相关的输出图像。不同于之前的一些针对特定任务的特定结构,本文的框架可以完成不同类的多种任务,只要是基于image-to-image.
本文CGAN的生成器使用U-Net,判别器使用PatchGAN的分类器,这个分类器只对图像块尺度上的结构进行惩罚。
- Method
3.1 Objective | 损失函数
之前有论文提出,生成器不仅要骗过判别器,还要用L2损失来使生成图像接近ground truth output.本文使用L1损失而不是L2,因为L1可以减小产生模糊的现象。
LL1(G) = Ex,y,z[ || y - G(x , z) ||1 ]
生成器最终的目标损失为
G* = arg min(G)max(D) LcGAN(G,D)+ λ\lambdaλLL1(G).
之所以要有随机噪声z的输入,是为了生成不确定输出。
但在实验过程中发现模型在学习过程中总是忽略初始噪声,所以在本模型中,以Dropout的形式提供噪声,并应用在生成器的多层上。尽管这样,输出还是只体现了很小的随机性。
3.2 Network architectures
convolution-BatchNorm-ReLu
3.2.1 Generator with skips | 跳步生成
image-to-image的一个问题是输入和输出都是高分辨率图片,很多工作用encoder-decoder网络来解决,即不停下采样再上采样。这种网络要求所有的图片信息通过网络结构,包括大量低级信息。比如图片上色中图片里明显边缘的位置,其实可以直接将这些信息通过网络,而不是让它们也一层一层的经过网络。
因此设计出skip connections,结构如U-Net一样,在第 i 层和第 n-i 层添加连接,这些连接简单的将每个channels进行全连接。
3.2.2 PatchGAN
在图片生成中使用L1和L2损失,会导致生成模糊的结果。虽然在高频结构上的结果不好,但在低频上表现还不错。因此这里只用判别器来判别高频结构,用L1来判别低频结构。
PatchGAN对N*N大小的每个图片块分为real和fake,使用卷积(滑动窗口)进行,最后对所有结果进行平均得到最终结果。
较小的PatchGAN具有更少的参数,但生成的结果依然不错,且运行速度快,可以应用到任意大小的图片上。
3.3 Optimization and inference
最大化logD(x, G(x, z))
优化D时将损失除以2,以降低D相对于G的学习率。
miniBatch SGD
Adam lr=0.0002 , β\betaβ1=0.5 , β\betaβ2=0.999
测试时使用Dropout,并使用测试数据的均值和方差进行批量归一化。这种批大小为1的归一化被称为(instance normalization)实例归一化,在生成任务中很有效。
4. Experiments
4.1 Evaluation metrics
评估生成图片的质量一直是个挑战。
为了更好的从整体方面评估生成的结果,使用两个方法。
第一个是用ATM(Amazon Mechanical Turk)来分辨真假。对于图片上色和图片生成,最终目标为骗过人类,因此使用ATM来评估特征生成,图片生成(aerial photo generation)和图片上色。
第二个是用类似于IS的已有识别系统来测试是否能够识别(特征或类别)。
注:ATM为辅助人工智能的人力,比如标注,识别。
4.1.1
ATM感知研究:在每个试验中,每个图片出现一秒,由Turk(识别员一样的存在)来标定真假。每个环节的前十张图片Turks会得到反馈(对工人的训练),后面的四十张图片没有反馈。每个环节只评估一个算法。每个Turk只能完成一个环节。每个算法由50个Turks来评估。
对于图片上色,真实图片和生成图片都来自于同一灰度级的输入。
For our colorization experiments, the real and fake images were generated from the same grayscale input.
???Why do real images also need to be generated???
对于特征生成图片(map↔aerial photo),真实图片和生成图片不是由相同的输入产生的,这么做的目的是让这一任务更难并避免发生floor-level results.训练时使用256256的图片,测试时使用512512的图片,然后进行下采样至256256并让Turks进行判断。
对于图片上色,在256256的图片上进行训练和测试,并以相同分辨率让Turks分辨。
4.1.2 FCN-Score
类似于IS,采用FCN-8s结构进行语义识别。并在城市风景数据集上训练它。然后计算得分,这一得分是测试分类标签的准确率,测得的正确类别标签个数 / 所有标签个数 。
4.2 目标函数的分析
为了探究清楚目标函数中L1项、GAN损失项哪个更重要,并比较有条件的判别器和无条件的判别器,进行了消融实验(ablation studies)。
注:消融实验:类似于控制变量法,为了探究在有多个变量影响的实验中哪个变量的影响更重要。
图4:

展示了不同目标函数下的结果
只用L1,结果会模糊;
只用cGAN,图片清晰很多,但引入了一些奇怪的特征(ground truth中没有的)
使用L1 + cGAN,会减少上述的奇怪特征。
评估模型时使用FCN-score,有GAN结构的目标得分都很高,证明其生成的图片包含了更多的可识别的结构。本实验还将有条件的判别器换成无条件的,其损失函数不会惩罚输入和输出的不匹配(即生成图片是否包含输入的condition),只会关心真实图片是否看起来像真实的。这个实验的表现很不好,不论输入什么图片,输出都几乎一样。
注意,添加L1会增加输入对于输出的影响,因为L1会根据匹配了输入标签的真实图片和可能没有匹配输入标签的生成图片间的距离进行惩罚。
[Note, however, that adding an L1 term also encourages that the output respect the input, since the L1 loss penalizes the distance between
ground truth outputs, which correctly match the input, and synthesized outputs, which may not.]
图片上色
就像L1会产生模糊图片,因为它不知道将比较突出的边缘放置在哪里,对于颜色也是这样,它无法搞清楚一个像素应该有哪种颜色,因此生成的颜色没有cGANs丰富,而更偏向于生成“平均颜色”。L1会通过选择条件概率密度函数的中间值而不是可能的颜色来减小损失。
4.3 生成器结构
生成器是U-Net结构。
本实验中Encoder-Decoder结构不能够生成逼真的图像。
不管是用L1损失还是cGANs,使用U-Net结构的模型生成的图像都更加真实。
4.4 从PixelGANs到PatchGANs到ImageGANs
探究拥有不同的感受野大小N的判别器的效果,从11的PixelGANs到286286的ImageGANs,本文中的其他环节的实验,如果没有特别说明,都是使用7070的PatchGANs,本环节使用L1+cGAN损失函数。

L1损失下的图片很模糊,并且颜色饱和度很低

使用L1 + cGANs损失,图片的颜色饱和度和锐度都有改善,但会有一些奇怪的结构出现。

7070 表现很好,286286表现也很好,但在FCN-score上的评估不如7070。这可能是因为286*286的模型拥有太多参数,难以训练的缘故。
PixelGAN在空间锐度上面没有明显改善,但会改善颜色饱和度。
Color Histogram matching是图像处理的普遍问题,PixelGANs可以提供一个简单的改良。
Fully-convolutional translation
PatchGANs的优势是固定大小的patch可以应用于任何大小的图像上。
4.5 Perceptual validation
4.6 语义分割
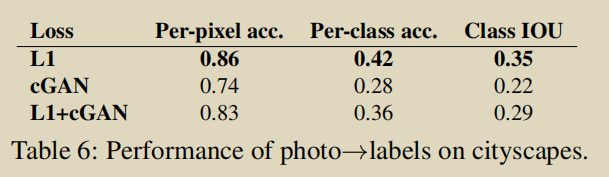
语义分割方面,在城市风景照的图片->标签任务中,只使用L1损失的Per-pixel-acc和Per-class-acc以及Class-IOU都比cGANs要高。我们认为在可视化任务中(vision problems),目标函数要比图像任务(graphics tasks)更模糊,因此L1损失函数已足够。
猜想:cGANs损失函数的惩罚力度更强会导致过拟合从而导致测试的精确度反而下降?
4.7 社区驱动研究
我们的模型成功得被用于各种图像任务,包括轮廓画猫猫、黑色背景去除、调色板生成、素描->肖像、素描->宝可梦、“Do as I do 动作迁移”和fotogenerator。
- 总结
略。

















 487
487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









