







如何避免索引失效
- 尽量全值匹配;
- 最佳左前缀法则;
- 不要在索引上做任何操作(计算、函数、(自动或者手动)类型转换);
- 存储引擎不能使用索引中范围条件右边的列;
- 尽量使用覆盖索引(只访问索引的查询(索引列和查询列一直)),减少select *;
- MySQL在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描;
- is null,is not null也无法使用索引;
- like以通配符开头(‘%abc…’)MySQL索引也会失效变成全表扫描的操作;
- 字符串不加单引号索引也会失效;
- 少用or,用它来连接时也会导致索引失效。
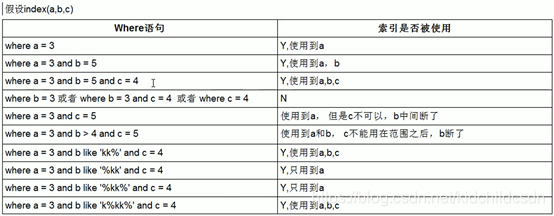
最佳左前缀法则:如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不要跳过索引中的列。
问题:解决like ‘%字符串%’时索引不被使用的方法???
使用覆盖索引:只访问索引的查询(索引列和查询列一致)),减少select *;
案例:
表之间的关联方式
1、in的好处是逻辑直观简单(通常是独立子查询);缺点是只能判断单字段,并且当not in时效率较低,而且null会导致不想要的结果。
2、exists的好处是效率高,可以判断单字段和组合字段,并不受null的影响;缺点是逻辑稍微复杂(通常是相关子查询)。
3、join的用途是联接两个表,而不是判断一个表的记录是否在另一个表。
join的实现是采用Nested Loop Join算法,就是通过驱动表的结果集作为循环基础数据,然后一条一条的通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。如果有多个join,则将前面的结果集作为循环数据,再一次作为循环条件到后一个表中查询数据。
所以join连接的优化方法如下:
- 尽可能减少join语句中的NestedLoop的循环总次数;
- 永远用小结果集驱动大结果集;
- 优先优化NestedLoop的内层循环;
- 保证join语句中被驱动表上join条件字段已经被索引;
- 当无法保证被驱动表的join条件字段被索引且内存资源充足的前提下,可以加大joinBuffer的参数。
exists与in
查询优化有个原则:小表驱动大表。
Select * from A where id in(select id from B)等价于:
For select id from B
For select * from A where A.id=B.id.
当B表的数据集必须少于A表的数据集的时候,用in由于exists.
Select * from A where exists (select 1 from B where B.id=A.id)等价于:
For select * from A
For select * from B where B.id=A.id
当A表的数据集少于B表的数据集时,用exists由于in。
注意:A表与B表的id字段应该建立索引。















 766
766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









