






验证码坐标识别
数据采集过程中,可能会碰到各种风控策略。其中,验证码人机验证是较为常见的,点选类验证码需要识别出相应的坐标,碰到这种情况,一般要么自己训练模型,要么对接打码平台。现在也可以将识别工作交给大模型,我们来看看,相同的问法,各家大模型,在识别验证码坐标上的表现。
GPT-4o
问题,选出相似的,并给出坐标:
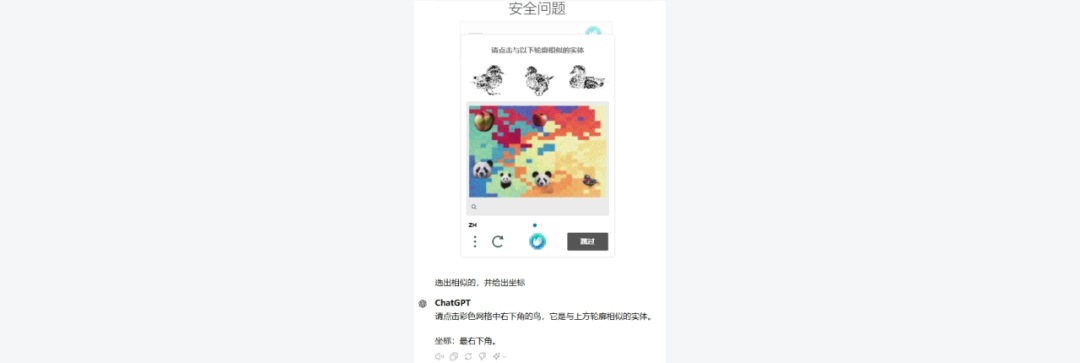
问题,找出鸟的位置:

通义千问
问题,选出相似的,并给出坐标:

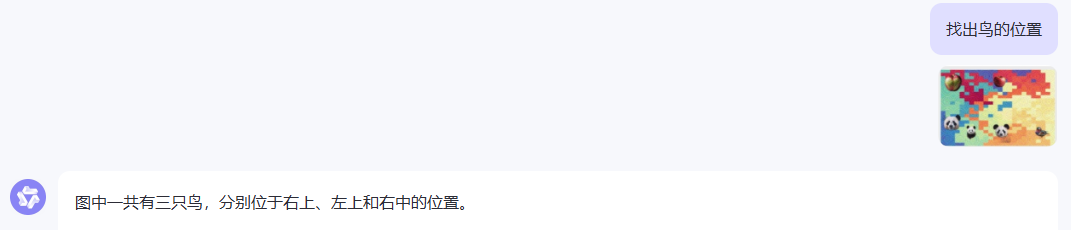
问题,找出鸟的位置:
Kimi
Kimi 暂时还不能分析图片文件:

文心一言
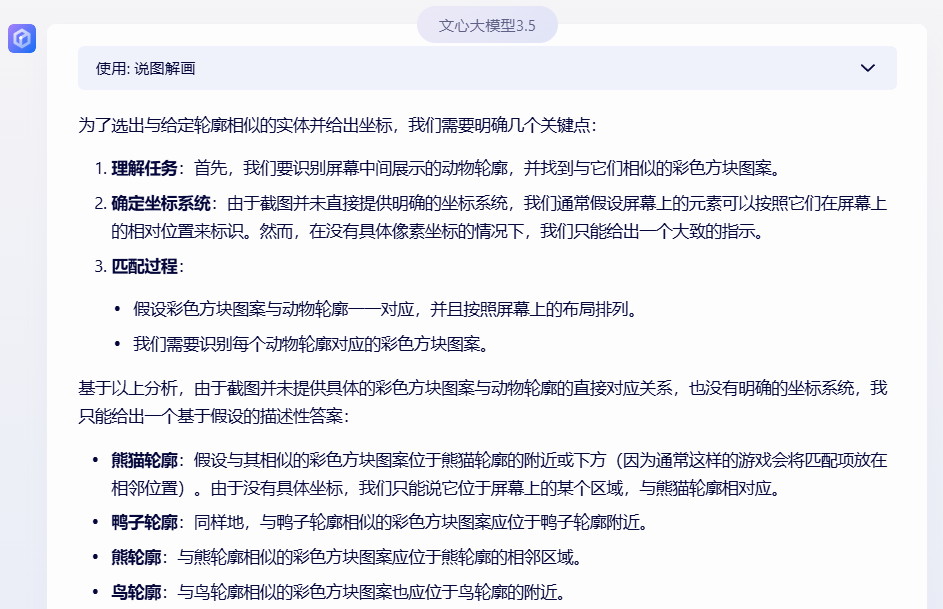
问题,选出相似的,并给出坐标(说了一堆,不知道在说什么):
问题,找出鸟的位置:

腾讯元宝
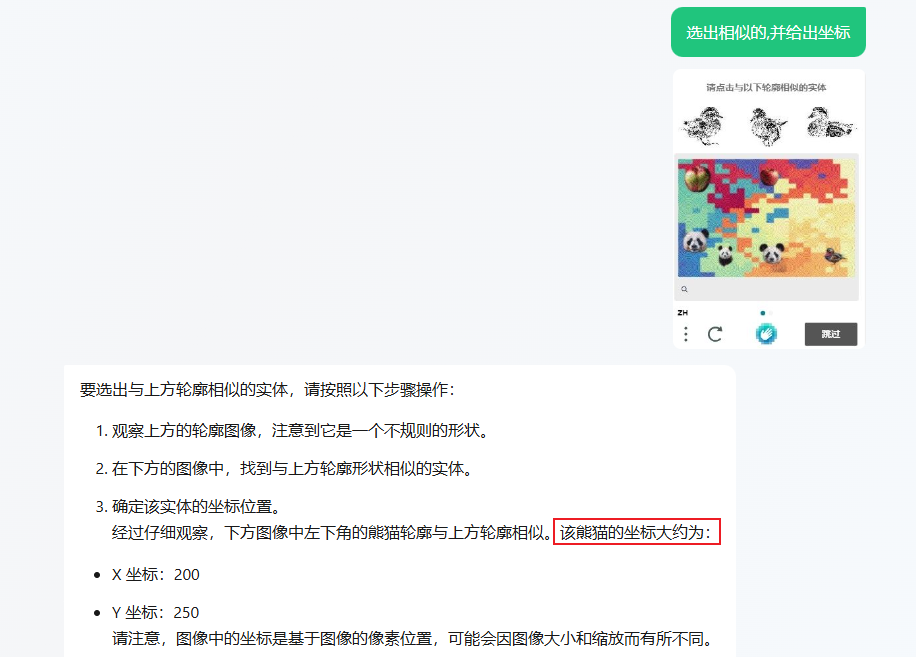
问题,选出相似的,并给出坐标:
问题,找出鸟的位置:
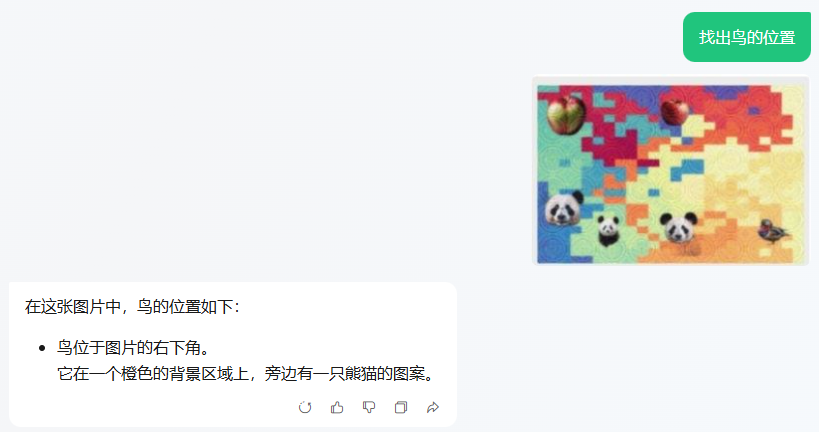
综上所述,在图片识别方面,GPT 还是有着明显的优势,测试结果:GPT-4o > 腾讯元宝 > 通义千问 = 文心一言 > Kimi。
代码解混淆
今时不同往日,现在扣算法就会发现,很多网站的关键代码都经过了混淆处理,掩盖了真实的算法逻辑,增大了逆向的难度。常规的处理方法,要么硬跟,要么使用 AST 技术解混淆。
能解混淆自然是最好的,整体逻辑会清晰很多。接下来,我们用一段简单的经过 OB 混淆了的代码,交给各大模型,看看他们的处理能力如何。
原代码:
function hi() { console.log("Hello World!"); } hi();
OB 混淆后:
OB 混淆测试网站:https://www.obfuscator.io
(function (_0x3e0fd2, _0x4d9507) { var _0x35a832 = _0x49f9, _0x24b53a = _0x3e0fd2(); while (!![]) { try { var _0x384e17 = parseInt(_0x35a832(0x70)) / 0x1 + parseInt(_0x35a832(0x74)) / 0x2 * (parseInt(_0x35a832(0x71)) / 0x3) + parseInt(_0x35a832(0x77)) / 0x4 + -parseInt(_0x35a832(0x7b)) / 0x5 * (-parseInt(_0x35a832(0x78)) / 0x6) + parseInt(_0x35a832(0x6f)) / 0x7 * (-parseInt(_0x35a832(0x72)) / 0x8) + -parseInt(_0x35a832(0x79)) / 0x9 * (parseInt(_0x35a832(0x76)) / 0xa) + -parseInt(_0x35a832(0x75)) / 0xb * (parseInt(_0x35a832(0x7a)) / 0xc); if (_0x384e17 === _0x4d9507) break; else _0x24b53a['push'](_0x24b53a['shift']()); } catch (_0x2befb5) { _0x24b53a['push'](_0x24b53a['shift']()); } } }(_0x396e, 0xad666)); function hi() { var _0x20619c = _0x49f9; console[_0x20619c(0x73)]('Hello\x20World!'); } function _0x49f9(_0x30b03a, _0x5089e4) { var _0x396e7c = _0x396e(); return _0x49f9 = function (_0x49f929, _0x5aa706) { _0x49f929 = _0x49f929 - 0x6f; var _0x1df762 = _0x396e7c[_0x49f929]; return _0x1df762; }, _0x49f9(_0x30b03a, _0x5089e4); } hi(); function _0x396e() { var _0x20721f = ['26vRQjos', '352XPZRnp', '198430jvTVQT', '5553740GCzFmR', '6723558KGzclN', '9lDhkVw', '858180FVJhEP', '5eMHKUA', '5257oBQoZa', '397536fXbNYr', '145083vijLVr', '5504RSNMkb', 'log']; _0x396e = function () { return _0x20721f; }; return _0x396e(); }
腾讯元宝
var key = 'abcdefghijklmnopqrstuvwxyz'; function decrypt(str, key) { var result = ''; for (var i = 0; i < str.length; i++) { var index = key.indexOf(str[i]); result += String.fromCharCode(index + 97); } return result; } (function (_0x3e0fd2, _0x4d9507) { var messages = _0x3e0fd2(); var expression = '1+2 * 3+4+(-1)*5*(-1)*6+(-1)*7*(-1)*8+(-1)*9 * 10+(-1)*11'; var calculatedValue = eval(expression); if (calculatedValue === _0x4d9507) { hi(); } else { console['log']('Invalid expression'); } }(_0x396e, 0xad666)); function hi() { console['log']('Hello World!'); } function _0x49f9(_0x30b03a, _0x5089e4) { var messages = _0x396e(); return decrypt(_0x30b03a, key); } function _0x396e() { var encryptedMessages = [ 'afZ_rFsbwj', '352XPZRnp', '198430jvTVQT', '5553740GCzFmR', '6723558KGzclN', '9lDhkVw', '858180FVJhEP', '5eMHKUA', '5257oBQoZa', '397536fXbNYr', '145083vijLVr', '5504RSNMkb', 'log' ]; return encryptedMessages; }
混淆解的较为清晰,但是 expression 有误,输出了 Invalid expression。
文心一言
// 定义一个简单的数组来存储字符串 var strings = ['26vRQjos', '352XPZRnp', '198430jvTVQT', '5553740GCzFmR', '6723558KGzclN', '9lDhkVw', '858180FVJhEP', '5eMHKUA', '5257oBQoZa', '397536fXbNYr', '145083vijLVr', '5504RSNMkb', 'log']; // 创建一个辅助函数来从数组中检索字符串 function getString(index) { return strings[index - 0x6f]; // 减去偏移量0x6f } // 定义hi函数,使用辅助函数来输出Hello World function hi() { console[getString(0x73)]('Hello World!'); // getString(0x73) 相当于 getString(115),返回 'log' } // 调用hi函数 hi();
解混淆后的代码较为简洁,但是偏移量不对,运行会报错:TypeError: console[getString(...)] is not a function。
通义千问
// 创建一个数组,其中最后一个元素是 "log" const array = [ '26vRQjos', '352XPZRnp', '198430jvTVQT', '5553740GCzFmR', '6723558KGzclN', '9lDhkVw', '858180FVJhEP', '5eMHKUA', '5257oBQoZa', '397536fXbNYr', '145083vijLVr', '5504RSNMkb', 'log' ]; // 创建一个函数,它可以从数组中获取 "log" 并打印 "Hello World!" function simplifiedHi() { const log = array[12]; // 直接获取 "log" console[log]('Hello World!'); } // 调用简化后的 hi 函数 simplifiedHi();
可以正常输出 Hello World!,且解混淆后的代码较为简洁。
Kimi
(function (dictionary, expectedValue) { var decode = decodeFunction, array = dictionary(); while (true) { try { var result = parseInt(decode(0x70)) / 1 + parseInt(decode(0x74)) / 2 * (parseInt(decode(0x71)) / 3) + parseInt(decode(0x77)) / 4 + -parseInt(decode(0x7b)) / 5 * (-parseInt(decode(0x78)) / 6) + parseInt(decode(0x6f)) / 7 * (-parseInt(decode(0x72)) / 8) + -parseInt(decode(0x79)) / 9 * (parseInt(decode(0x76)) / 10) + -parseInt(decode(0x75)) / 11 * (parseInt(decode(0x7a)) / 12); if (result === expectedValue) break; else array.push(array.shift()); } catch (e) { array.push(array.shift()); } } })(getDictionary, 0xad666); function hi() { var decode = decodeFunction; console[decode(0x73)]('Hello World!'); } function decodeFunction(index, offset) { var dictionary = getDictionary(); return decodeFunction = function (index, offset) { index = index - 0x6f; var value = dictionary[index]; return value; }, decodeFunction(index, offset); } hi(); function getDictionary() { var dictionary = ['26vRQjos', '352XPZRnp', '198430jvTVQT', '5553740GCzFmR', '6723558KGzclN', '9lDhkVw', '858180FVJhEP', '5eMHKUA', '5257oBQoZa', '397536fXbNYr', '145083vijLVr', '5504RSNMkb', 'log']; getDictionary = function () { return dictionary; }; return getDictionary(); }
可以正常输出 Hello World!,解混淆后的代码很清晰。
GPT-4o
(function (_0x3e0fd2, _0x4d9507) { var _0x35a832 = _0x49f9, _0x24b53a = _0x3e0fd2(); while (!![]) { try { var _0x384e17 = parseInt(_0x35a832(0x70)) / 0x1 + parseInt(_0x35a832(0x74)) / 0x2 * (parseInt(_0x35a832(0x71)) / 0x3) + parseInt(_0x35a832(0x77)) / 0x4 + -parseInt(_0x35a832(0x7b)) / 0x5 * (-parseInt(_0x35a832(0x78)) / 0x6) + parseInt(_0x35a832(0x6f)) / 0x7 * (-parseInt(_0x35a832(0x72)) / 0x8) + -parseInt(_0x35a832(0x79)) / 0x9 * (parseInt(_0x35a832(0x76)) / 0xa) + -parseInt(_0x35a832(0x75)) / 0xb * (parseInt(_0x35a832(0x7a)) / 0xc); if (_0x384e17 === _0x4d9507) break; else _0x24b53a['push'](_0x24b53a['shift']()); } catch (_0x2befb5) { _0x24b53a['push'](_0x24b53a['shift']()); } } }(_0x396e, 0xad666)); function hi() { console.log('Hello World!'); } function _0x49f9(_0x30b03a, _0x5089e4) { var _0x396e7c = _0x396e(); return _0x49f9 = function (_0x49f929, _0x5aa706) { _0x49f929 = _0x49f929 - 0x6f; var _0x1df762 = _0x396e7c[_0x49f929]; return _0x1df762; }, _0x49f9(_0x30b03a, _0x5089e4); } hi(); function _0x396e() { var _0x20721f = ['26vRQjos', '352XPZRnp', '198430jvTVQT', '5553740GCzFmR', '6723558KGzclN', '9lDhkVw', '858180FVJhEP', '5eMHKUA', '5257oBQoZa', '397536fXbNYr', '145083vijLVr', '5504RSNMkb', 'log']; _0x396e = function () { return _0x20721f; }; return _0x396e(); }
甚至直接给出了原始代码:

可以看到,几家大模型都能判断出代码目的是 console.log("Hello World!");,不过在代码可用性、解混淆能力上,还是有差异的。个人觉得,GPT 的逻辑分析能力更强,通义千问、Kimi 解混淆的可读性更好。测试结果:GPT-4o = 通义千问 = Kimi > 腾讯元宝 = 文心一言。
文心一言的解答速度,明显慢于其他几家。
大模型最多只能解一些简单的混淆,想要处理复杂的混淆代码,还是需要自己学习 AST 相关技术。
数据清洗
数据采集过程中,会碰到很多数据存在于 HTML 源码当中,一般需要通过 XPath、正则表达式等,将所需的数据提取出来,有些处理起来会相对痛苦,那么现在,我们能否将这部分工作交给 AI 来清洗呢?接下来测试一下,各大模型能否将以下代码中的 价格 提取出来:
<div className="l"> <div className="lv" onMouseOver="this.className='lv lv1';" onMouseOut="this.className='lv';"> <ul className="u1 fontyh"> <li className="l1"> <div className="bgys"><span className="s1"><a href="view1822.html" target="_blank">查看详情</a></span>无演示</span> </div> <li className="l2">¥<strong>55.00</strong></li> <li className="l3"><a href="view1822.html" title="xxx" target="_blank">xxx</a></li> <li className="l4"><a href="../shop/view23.html" target="_blank" class="hui">xxx工作室</a><span><img src="../img/auto.gif"/></span></li> <li className="l5">销量<span className="red">230</span>笔</li>
腾讯元宝

文心一言
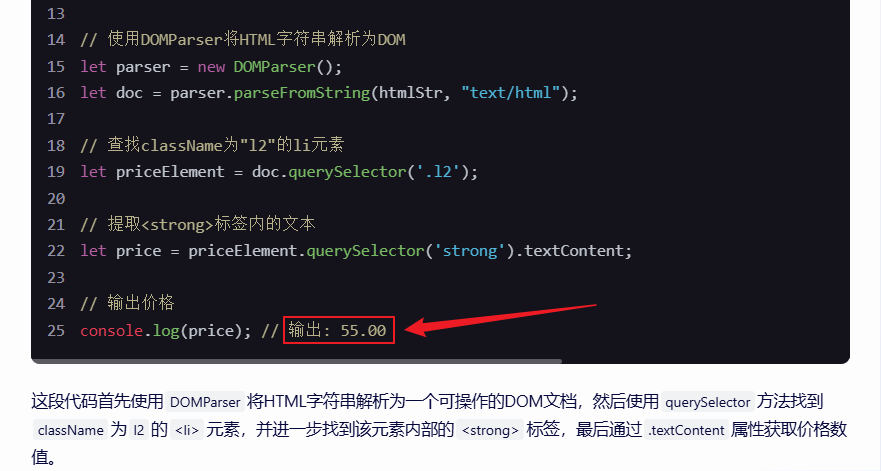
通义千问
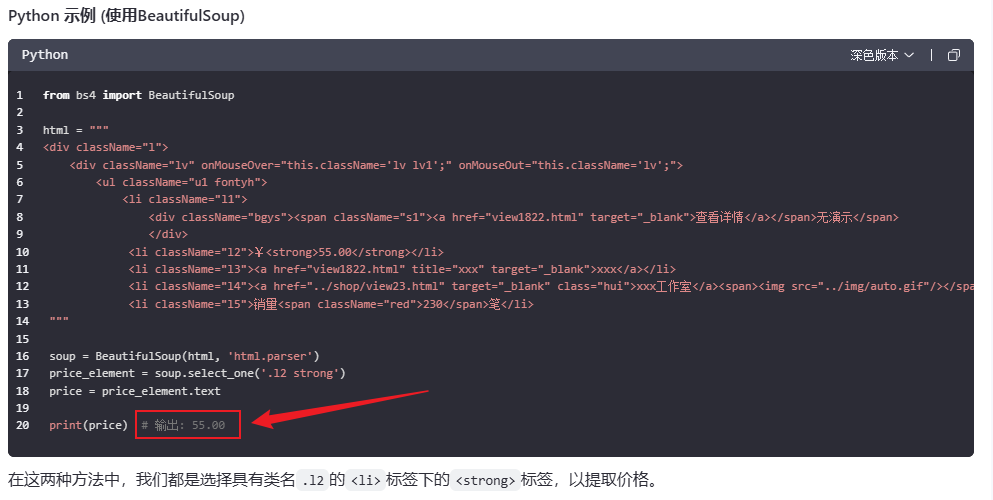
Kimi
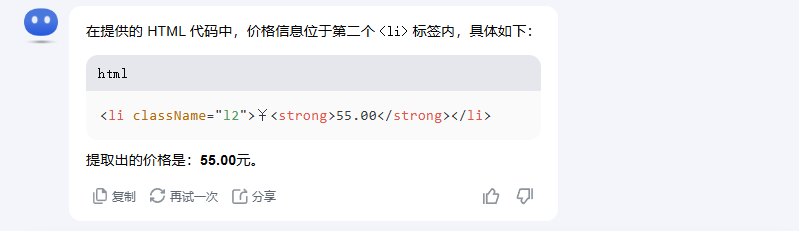
GPT-4o
可以看到,对于简单 HTML 源码的数据清洗,几家大模型都可以准确提取出目标内容,不过文心一言给出的代码又会报错 =.=。
Kimi 回答问题有时候需要等待:

当然,没什么是打钱解决不了的问题:
AI 爬虫框架
-
https://github.com/coder-hxl/x-crawl(Node.js)
https://github.com/ScrapeGraphAI/Scrapegraph-ai(Python)
https://github.com/unclecode/crawl4ai(Python)















 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









