






说明:本文主要是通过一些小的案例,让你体验一下OpenAI提供的一些API,如果你连ChatGPT和OpenAI是什么都不知道,那么这篇文章可能不适合你,你可以划走了.
环境准备:
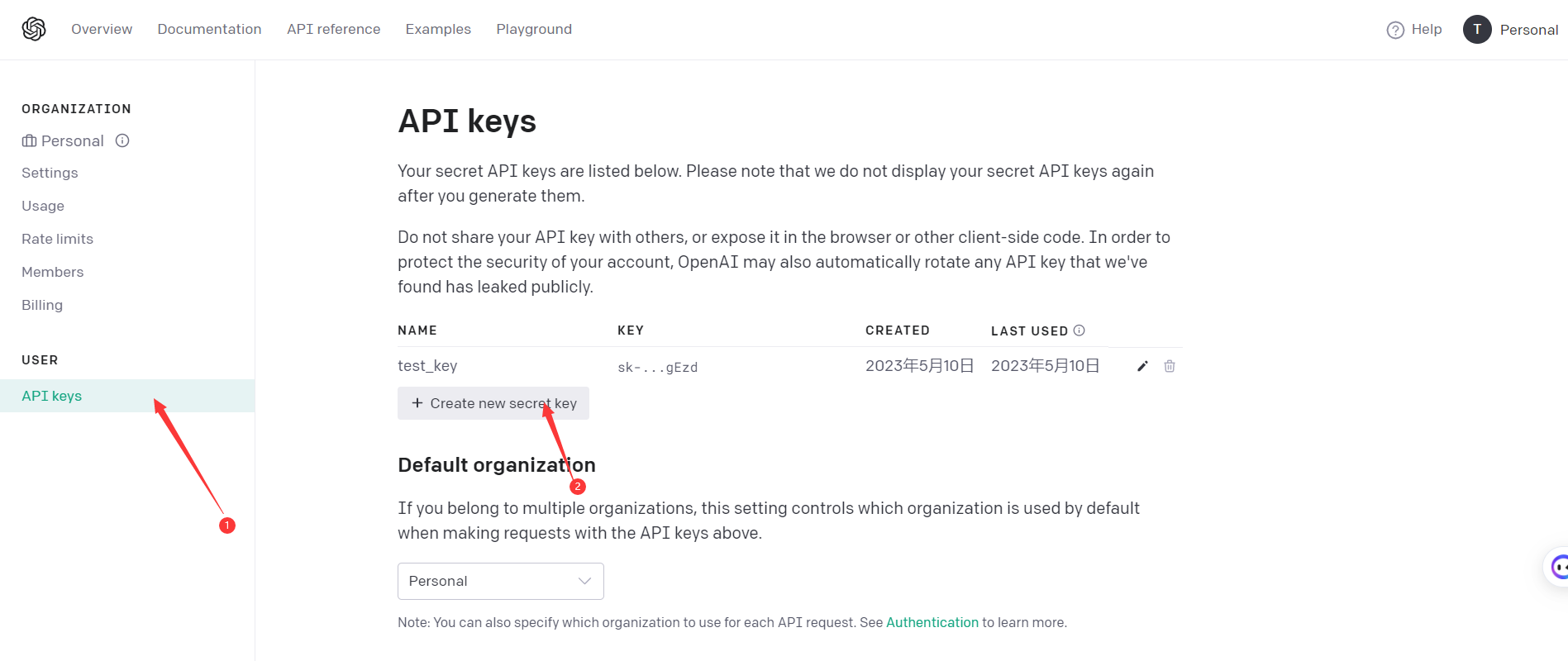
01.准备账号和APIKey
首先要注册一个ChatGPT账号,账号注册完成之后,打开地址:
https://platform.openai.com/account/api-keys.
然后点击 “API Keys”,就会进入一个管理 API Keys 的页面,继续点击你点击下面的 “+Create new secret key” 可以创建一个新的 API Key。
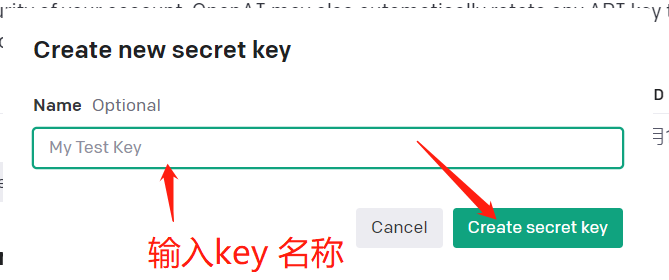
输入key的名称,随便起个名字,然后点击create key
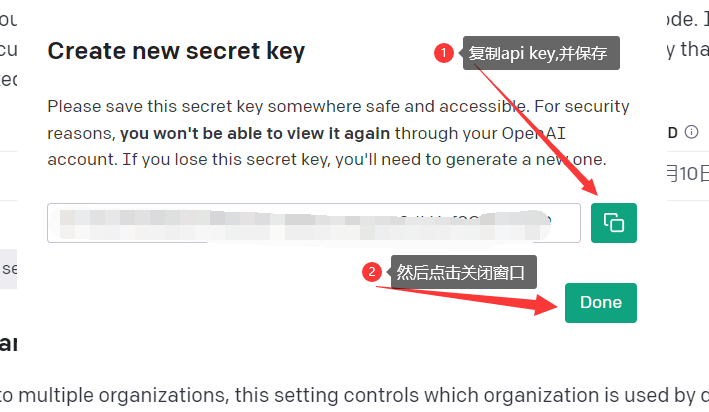
生成API key 并保存
02.保证你的账户有充足的余额
登录你的ChatGPT账号,打开地址查看:https://platform.openai.com/account/usage
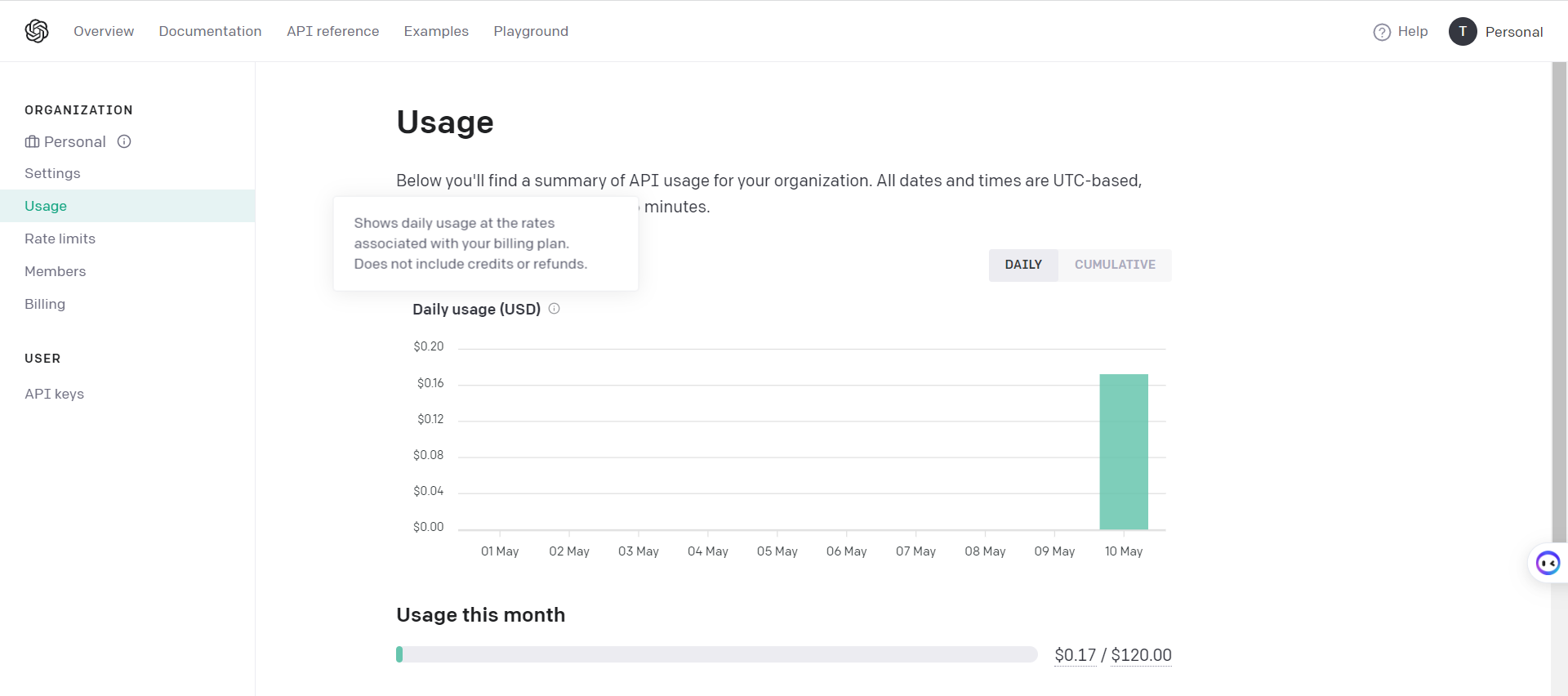
默认新注册的用户赠送5美金,没有余额的自己要想办法啦
03.开发环境搭建
你需要有一台可以访问ChatGPT的服务器,或者可以科学的上网并且成功访问到ChatGPT的工具.
具备这些条件之后,我们开始安装conda
介绍:Conda是一个开源的包管理工具和虚拟环境管理工具,可以在不同的平台上(如Windows、Linux和macOS)安装和管理不同版本的软件包和Python环境。Conda可以创建、导出、共享、修改和删除不同的环境,每个环境都可以安装不同版本的软件包和Python解释器。这使得在同一系统上同时使用不同版本的软件和Python环境变得容易,可以避免因不同版本的依赖冲突而导致的问题。
安装Conda:
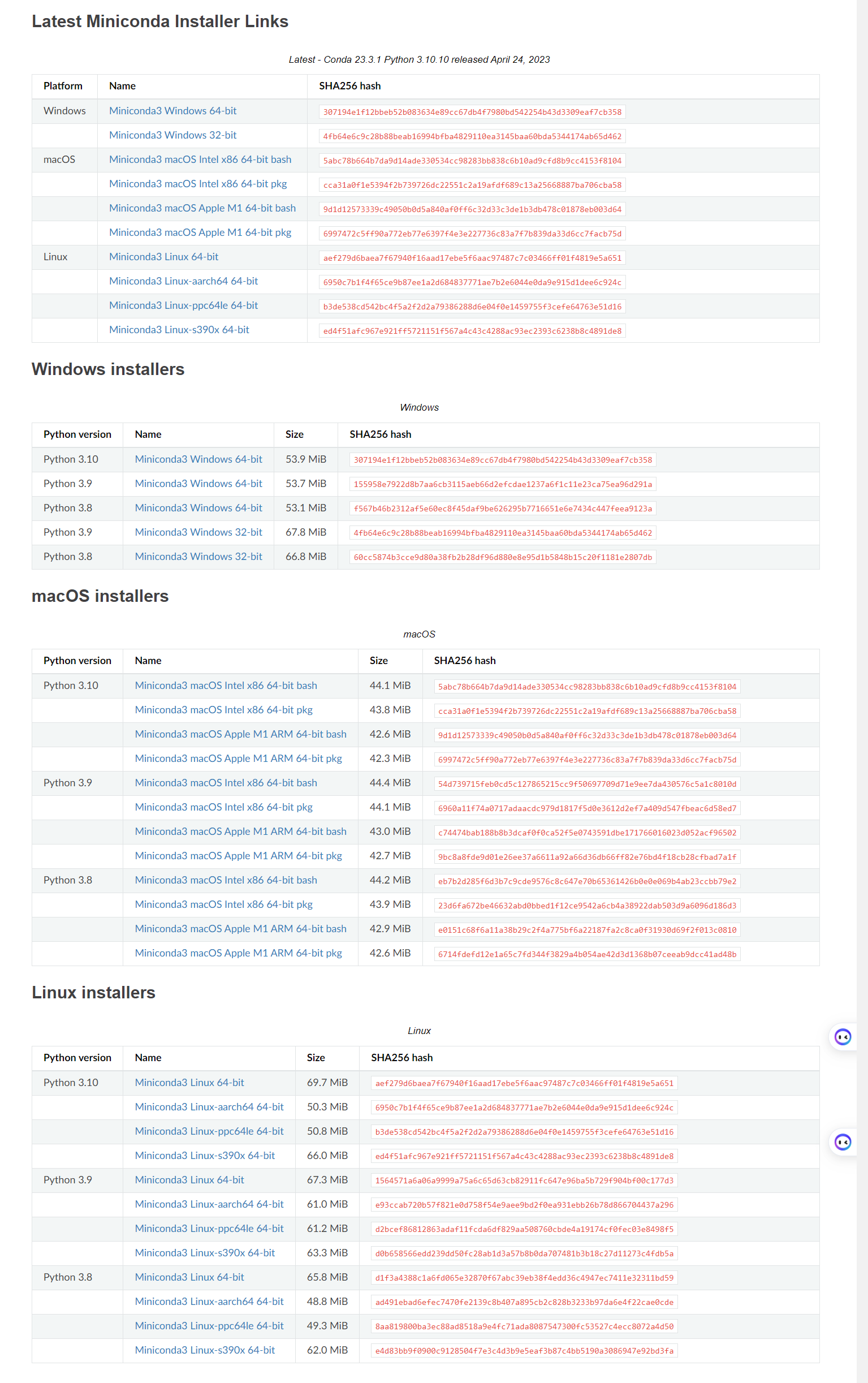
首先去官网地址下载:https://docs.conda.io/en/latest/miniconda.html
选择你自己的平台下载
具体安装教程省略,可以参考我之前写的如下:
linux 安装教程地址:https://blog.csdn.net/weixin_44621343/article/details/126005530
Windows安装教程:https://blog.csdn.net/weixin_44621343/article/details/120168347
04.创建虚拟环境和安装OpenAI包
安装好以后创建一个虚拟环境
conda create --name py310 python=3.10
激活虚拟环境
conda activate py310
安装 openai 包
conda install -c conda-forge openai
一.测试体验OpenAI的API
尝试运行下面的代码,将api_key替换为你的
import openai
import os
api_key='你的api_key'
openai.api_key = api_key
COMPLETION_MODEL = "text-davinci-003" # text-davinci-003 是 OpenAI GPT-3 语言模型的一个变体,它是目前最先进的自然语言处理模型之一。它可以用于生成文本、回答问题、翻译语言、摘要提取和对话生成等任务,具有非常高的语言理解和生成能力。
prompt = """
思考问题 : 外响mp3学生随身听纯色运动插卡播放器带无屏内存卡全套批发礼品
1.在 20 个单词以内撰写淘宝上使用的人类阅读产品标题。
2.为淘宝上的产品写下5个卖点。
3.评估此产品在中国的价格范围
以 json 格式输出结果,其中包含三个属性,分别称为title、selling_points 和 price_range ,
"""
def get_response(prompt):
"""
"""
try:
# 调用了openai.Completion.create方法来请求OpenAI的API生成一个文本提示的响应
completions = openai.Completion.create (
engine=COMPLETION_MODEL, # 用于生成响应的OpenAI模型的名称或ID
prompt=prompt, # 请求生成响应的文本提示
max_tokens=512, # 请求生成的响应最大令牌数
n=1, # 请求生成的响应数
stop=None, # 响应中的停止标记。当生成的响应中包含此字符串时,响应将被截断
temperature=0.8, # 控制生成的响应的创造性和多样性的值。
)
message = completions.choices[0].text
except Exception as e:
print(e)
message ="出错了,请求频率过高,API-Key无效,网络出现问题或者余额不足!"
return message
response = get_response(prompt)
print(response)
如果没有问题的话运行处的结果如下:
{
"title":"外响MP3学生随身听无屏内存播放器全套礼品",
"selling_points":["轻薄纯色设计","支持MP3音频播放","运动时无线自由插卡","内置大容量内存卡","支持多种文件格式"],
"price_range":"40-80元"
}
到这里,你已经学会调用OpenAI的API了
在上面的例子中,你有没有发现,你并没有指定输出中文,但是它根据的语意输出了中文,这是因为它能理解你的语义去生成文本
根据我们的要求把我们想要的结果,通过一个 JSON 结构化地返回给我们,还把卖点放在一个列表里面,非常的贴心
我们再来一个例子,
prompt = """
Tengger adaptation of the wings of angels, Zhang Fei think it is very good to hear
请将上面这句话的人名提取出来,并用json的方式展示出来
"""
response = get_response(prompt)
print(response)
输入结果为:
[
{
"name": "Tengger"
},
{
"name": "Zhang Fei"
}
]
可以看到,它能够准确的识别到人名,是不是有点激动,这里我们用到了机器学习的命名体识别
二.利用Embedding 接口,20 行代码帮你做情感分析
通过大语言模型来进行情感分析,官方提供了Embedding 这个 API。这个 API 可以把任何你指定的一段文本,变成一个大语言模型下的向量,也就是用一组固定长度的参数来代表任何一段文本。
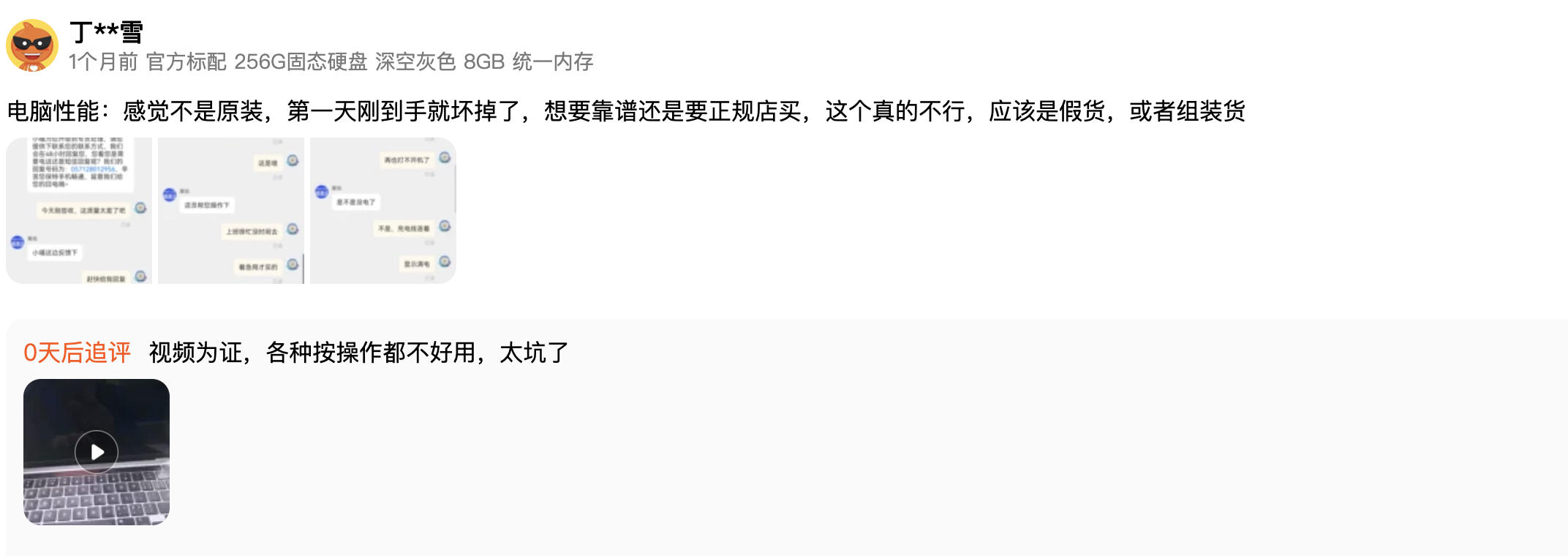
这里我们以顾客的好评和差评为例,在这个方法分析一下两条在淘宝上购买了 MacBook Pro 用户的评论

首先试着运行下面的代码
import openai
from openai.embeddings_utils import cosine_similarity, get_embedding
OPENAI_API_KEY = '你的APIKey'
openai.api_key = OPENAI_API_KEY
EMBEDDING_MODEL = "text-embedding-ada-002"
positive_review = get_embedding("好评")
negative_review = get_embedding("差评")
positive_example = get_embedding("音质超级棒👍🏻操作丝滑,真是神仙笔记本")
negative_example = get_embedding("电脑性能:感觉不是原装,第一天刚到手就坏掉了,想要靠谱还是要正规店买,这个真的不行,应该是假货,或者组装货,视频为证,各种按操作都不好用,太坑了")
def get_score(sample_embedding):
return cosine_similarity(sample_embedding, positive_review) - cosine_similarity(sample_embedding, negative_review)
positive_score = get_score(positive_example)
negative_score = get_score(negative_example)
print("好评例子的评分 : %f" % (positive_score))
print("差评例子的评分 : %f" % (negative_score))
在上述代码中,我们需要提前计算“好评”和“差评”这两个字的 Embedding向量。而对于任何一段文本评论,我们也都可以通过 API 拿到它的 Embedding。那么,我们把这段文本的 Embedding 和“好评”以及“差评”通过余弦距离(Cosine Similarity)计算出它的相似度。然后我们拿这个 Embedding 和“好评”之间的相似度,去减去和“差评”之间的相似度,就会得到一个分数。如果这个分数大于 0,那么说明我们的评论和“好评”的距离更近,我们就可以判断它为好评。如果这个分数小于 0,那么就是离差评更近,我们就可以判断它为差评。
ChatGPT 代码解释
这段代码使用了 OpenAI 的 API 来计算两个文本之间的语义相似度。首先,它使用了 openai.embeddings_utils 模块中的 cosine_similarity() 函数来计算两个嵌入向量之间的余弦相似度,其中 get_embedding() 函数用于获取输入文本的嵌入向量。然后,get_score() 函数使用正面评论和负面评论之间的余弦相似度差来计算文本的情感得分。最后,使用几个示例评论来演示代码的用法,并输出情感得分。
具体来说,这段代码做了以下事情:
- 导入必要的模块:
openai用于连接 OpenAI API - 设置 OpenAI API 的密钥和嵌入模型,这里设置模型为。
- 使用
get_embedding()函数获取正面和负面评论的嵌入向量。 - 使用
get_score()函数计算示例评论的情感得分。 - 输出示例评论的情感得分。
通过这种方式,我们可以使用 OpenAI API 计算文本之间的相似度和评分,以帮助我们判断它们的情感和意义。
这里只是举个小例子,更多情感分析案例请自行探索。
三.巧用提示语,调用Completion接口
ChatGPT 上线至今,已经快 5 个月了,但是不少人还没真正掌握它的使用技巧。
其实,ChatGPT 的难点,在于 Prompt(提示词)的编写,OpenAI 创始人在今年 2 月时,在 Twitter 上说:能够出色编写 Prompt 跟聊天机器人对话,是一项能令人惊艳的高杠杆技能。
因为从 ChatGPT 发布之后,如何写好 Prompt 已经成为了一个分水岭。熟练掌握 Prompt 编写的人,能够很快让 ChatGPT 理解需求,并很好的执行任务。
目前你在网上看到的所有 AI 助理、智能翻译、角色扮演,本质上还是通过编写 Prompt 来实现。
只要你的 Prompt 写的足够好,ChatGPT 可以帮你快速完成很多工作,包括写爬虫脚本、金融数据分析、文案润色与翻译等等,并且这些工作还做的比一般人出色。
为了帮助大家能更好的掌握 Prompt 工程,DeepLearning.ai 创始人吴恩达与 OpenAI 开发者 Iza Fulford 联手推出了一门面向开发者的技术教程:《ChatGPT 提示工程》。

01.帮你做AI客服机器人
在传统的智能客服往往是套用固定的模版。每次的回答都一模一样,整体的体验还是相当呆板。
有了GPT这样的大语言模型,可以使用AI帮我们去写文案,只要把我们的需求提给 Open AI 提供的 Completion 接口
可以尝试运行下面的代码:
import openai
import os
OPENAI_API_KEY ='你的APIKey'
openai.api_key = OPENAI_API_KEY
COMPLETION_MODEL = "text-davinci-003"
prompt = '请你用朋友的语气回复给到客户,并称他为“亲”,他的订单已经发货在路上了,预计在3天之内会送达,订单号2021AEDG,我们很抱歉因为天气的原因物流时间比原来长,感谢他选购我们的商品。'
def get_response(prompt, temperature = 1.0):
completions = openai.Completion.create (
engine=COMPLETION_MODEL,
prompt=prompt,
max_tokens=1024,
n=1,
stop=None,
temperature=temperature,
)
message = completions.choices[0].text
return message
print(get_response(prompt))
下面是我运行了几次的结果,每次回答都不太一样,让AI智能客服变的更加有趣味性。

在这里,我们可以temperature这个参数来调整每次输出的结果的随机性和多样性,这个参数的输入范围是 0-2 之间的小数(浮点数)。
这个参数该怎么设置,取决于实际使用的场景。如果对应的场景比较严肃,不希望出现差错,那么设得低一点比较合适,比如银行客服的场景。如果场景没那么严肃,有趣更加重要,比如讲笑话的机器人,那么就可以设置得高一些。
Completion 接口常用参数
-
第一个参数是 engine,也就是我们使用的是 Open AI 的哪一个引擎,这里我们使用的是 text-davinci-003,也就是现在可以使用到的最擅长根据你的指令输出内容的模型。
-
第二个参数是 prompt,自然就是我们输入的提示语。
-
第三个参数是 max_tokens,也就是调用生成的内容允许的最大 token 数量。你可以简单地把 token 理解成一个单词。实际上,token 是分词之后的一个字符序列里的一个单元。有时候,一个单词会被分解成两个 token。比如,icecream 是一个单词,但是实际在大语言模型里,会被拆分成 ice 和 cream 两个 token。这样分解可以帮助模型更好地捕捉到单词的含义和语法结构。一般来说,750 个英语单词就需要 1000 个 token。我们这里用的 text-davinci-003 模型,允许最多有 4096 个 token。需要注意,这个数量既包括你输入的提示语,也包括 AI 产出的回答,两个加起来不能超过 4096 个 token。比如,你的输入有 1000 个 token,那么你这里设置的 max_tokens 就不能超过 3096。不然调用就会报错。
-
第四个参数 n,代表你希望 AI 给你生成几条内容供你选择。在这样自动生成客服内容的场景里,我们当然设置成 1。但是如果在一些辅助写作的场景里,你可以设置成 3 或者更多,供用户在多个结果里面自己选择自己想要的。
-
第五个参数 stop,代表你希望模型输出的内容在遇到什么内容的时候就停下来。这个参数我们常常会选用 "\n\n"这样的连续换行,因为这通常意味着文章已经要另起一个新的段落了,既会消耗大量的 token 数量,又可能没有必要。我们在下面试了一下,将“,”作为 stop 的参数,你会发现模型在输出了“亲”之后就停了下来。
print(get_response(prompt, 0.0, ","))
- 第六个参数 temperature,代表模型生成内容的随机程度,数值越小生成的内容越确定性,数值越大生成的内容越随机。一般来说,0.7~1.0 是比较常用的范围。如果你想要更加准确的回答,可以适当调小这个值,如果想要更多的创意和想法,可以适当调大这个值。
- 第七个参数 frequency_penalty,代表生成内容中重复的想法、短语和词语的惩罚因子,数值越大越倾向于生成不重复的内容,数值越小越倾向于生成重复的内容。如果你需要生成长篇的内容,可以适当调低这个值;如果你需要生成短篇的内容,可以适当调高这个值。
- 第八个参数 presence_penalty,代表生成内容中未提及想法、短语和词语的惩罚因子,数值越大越倾向于生成尽可能包含所有提示信息的内容,数值越小越倾向于生成忽略某些提示信息的内容。如果你需要生成准确的回答,可以适当调低这个值;如果你需要生成更加有创意的回答,可以适当调高这个值。
02. 帮你做AI聊天机器人
对于聊天机器人来说,只理解当前用户的句子是不够的,能够理解整个上下文是必不可少的。
而 GPT 的模型,要完成支持多轮的问答也并不复杂。我们只需要在提示语里增加一些小小的工作就好了。
想要实现问答,我们只需要在提示语里,在问题之前加上 “Q :” 表示这是一个问题,然后另起一行,加上 “A :” 表示我想要一个回答,那么 Completion 的接口就会回答你在 “Q : ” 里面跟的问题。比如下面,我们问 AI “西红柿炒鸡蛋怎么做?”。它就一步一步地列出了制作步骤。
question = """
Q : 西红柿炒鸡蛋怎么做?
A :
"""
print(get_response(question))
以下是AI的回答:

而要完成多轮对话其实也不麻烦,我们只要把之前对话的内容也都放到提示语里面,把整个上下文都提供给 AI。AI 就能够自动根据上下文,回答第二个问题。比如,你接着问“那番茄酱牛肉呢?”。我们不要只是把这个问题传给 AI,而是把前面的对话也一并传给 AI,那么 AI 自然知道你问的“那番茄酱牛肉呢?”是指怎么做,而不是去哪里买或者需要多少钱。
question = """
Q : 西红柿炒鸡蛋怎么做?
A :
1. 把西红柿洗干净,剁成小丁;
2. 把鸡蛋打入碗中搅匀;
3. 倒入油量足够的料酒,再把鸡蛋内加入少许盐调味;
4. 热锅,把鸡蛋淋入锅中,翻炒数秒;
5. 把西红柿放入锅中,翻炒均匀,盛出即可。
Q : 那番茄酱牛肉呢?
A :
"""
print(get_response(question))
以下是AI的回答:

好了,看到这里,我们来实现一个简单的聊天机器人,运行下面的代码:
import openai
import os
OPENAI_API_KEY ='你的APIKey'
openai.api_key = OPENAI_API_KEY
def ask_gpt3(prompt):
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
max_tokens=512,
n=1,
stop=None,
temperature=0.5,
)
message = response.choices[0].text.strip()
return message
print("你好,我是一个聊天机器人,请你提出你的问题吧?")
questions = []
answers = []
def generate_prompt(prompt, questions, answers):
num = len(answers)
for i in range(num):
prompt += "\n Q : " + questions[i]
prompt += "\n A : " + answers[i]
prompt += "\n Q : " + questions[num] + "\n A : "
return prompt
while True:
try:
user_input = input(">>>")
questions.append(user_input)
if user_input.lower() in ["bye", "goodbye", "exit"]:
print("Goodbye!")
break
prompt = generate_prompt("", questions, answers)
answer = ask_gpt3(prompt)
print(answer)
answers.append(answer)
except KeyboardInterrupt:
print("\nKeyboardInterrupt detected. Stopping the program...")
break
这里我们使用 OpenAI GPT-3 模型来回答用户输入的问题。当用户输入一个问题后,该问题被添加到 questions 列表中,然后通过 generate_prompt 函数生成一个新的 prompt。这个 prompt 包含之前所有问题和它们的回答。新的 prompt 被用作输入参数调用 ask_gpt3 函数来生成一个新的回答,并将回答添加到 answers 列表中。最后,新的回答被打印到屏幕上并等待下一个用户输入。当用户输入 “bye”、“goodbye” 或 “exit” 时,聊天机器人退出。

通过以上简单的例子,我们就简单的实现了一个聊天机器人。
在上面的例子中,我们给AI“一个任务描述、给少数几个例子、给需要解决的问题”这样三个步骤的组合,AI 就能够举一反三,回答我们的问题。
这也是大语言模型里使用提示语的常见套路。一般我们称之为 Few-Shots Learning(少样本学习)
四.利用images 接口,实现AI绘画
01.图像生成
当涉及到生成图像时,OpenAI的API可以提供强大的功能。使用OpenAI的API,可以生成各种类型的图像,例如人物肖像、动物、风景等。
只需提供一个简短的提示,API就会自动生成与提示相关的图像。
以下是使用OpenAI的API生成图像的示例代码:
import requests
import json
from PIL import Image
import io,base64
# Set your OpenAI API key
openai_api_key = "你的API key"
# Set the API endpoint
endpoint = "https://api.openai.com/v1/images/generations"
def generate_image(prompt, model="image-alpha-001", num_images=1, size="1024x1024", response_format="url"):
"""
Generate an image using OpenAI's API given a prompt.
Parameters:
prompt (str): The prompt to generate the image from.
model (str): The model to use. Default is "image-alpha-001".
num_images (int): The number of images to generate. Default is 1.
size (str): The size of the image in pixels, in the format "widthxheight". Default is "1024x1024".
response_format (str): The format of the response. Default is "url".
Returns:
str: The base64-encoded image in JSON format.
"""
# Set the request data
data = {
"model": model,
"prompt": prompt,
"num_images": num_images,
"size": size,
"response_format": response_format
}
# Set the API endpoint and headers
endpoint = "https://api.openai.com/v1/images/generations"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {openai_api_key}"
}
# Send the POST request
response = requests.post(endpoint, headers=headers, data=json.dumps(data))
print(response.status_code)
if response.status_code !=200:
print("网路请求出错了")
return None
# Parse the response
if response_format == 'url':
image_data = response.json()["data"][0]["url"]
response = requests.get(image_data)
with open('image.jpg', 'wb') as f:
f.write(response.content)
else:
# # Decode image data
image_data = response.json()["data"][0]['b64_json']
# Save image to file
with open('image.jpg', 'wb') as f:
f.write(base64.b64decode(image_data))
prompt = '帮我生成一张可爱的狗'
print(generate_image(prompt=prompt,response_format='url'))
在上面的示例代码中,我们使用了OpenAI的API生成了一张可爱的狗的图像。
以下是生成的效果图,是不是超可爱.

02.图片编辑,实现AI修图功能
OpenAI的图片编辑功能可以帮助你实现AI自动编辑或扩展图片的功能。通过向API发送请求,用户可以提供一张原始图片、一个描述图片要实现的效果的文本提示,以及可选的遮罩层图片,API将返回一张或多张已经编辑或扩展好的图片。用户可以选择返回的图片格式,支持 URL 或者 Base64 编码后的 JSON 字符串。该功能可以被用来自动修图、创作艺术作品、生成场景和图像等多种应用。
具体来说,首先发送 HTTP POST 请求,请求 API 对指定图片进行编辑。你只需要提供原始图片、图片的描述文本提示、遮罩层图片(可选)、编辑生成图片的数量、编辑生成图片的大小等参数。API 将根据提示文本,利用深度学习模型自动编辑并生成一张或多张编辑后的图片,然后将编辑后的图片以指定的格式返回给你。
具体实现代码如下,你可以试着运行下面的代码:
import requests
import json
import os,base64
from PIL import Image
from io import BytesIO
# Your OpenAI API key
api_key = "YOUR_API_KEY"
def generate_edited_image(image: str, prompt: str, mask: str = None, n: int = 1, size: str = "1024x1024",
response_format: str = "url"):
"""
Generate an edited or extended image given an original image and a prompt.
Args:
image (str): Required. The image to edit. Must be a valid PNG file, less than 4MB, and square. If mask is not provided, image must have transparency, which will be used as the mask.
mask (str, optional): An additional image whose fully transparent areas (e.g. where alpha is zero) indicate where image should be edited. Must be a valid PNG file, less than 4MB, and have the same dimensions as image.
prompt (str): Required. A text description of the desired image(s). The maximum length is 1000 characters.
n (int, optional): The number of images to generate. Must be between 1 and 10. Defaults to 1.
size (str, optional): The size of the generated images. Must be one of 256x256, 512x512, or 1024x1024. Defaults to "1024x1024".
response_format (str, optional): The format in which the generated images are returned. Must be one of "url" or "b64_json". Defaults to "url".
"""
endpoint = "https://api.openai.com/v1/images/edits"
headers = {
"Authorization": f"Bearer {api_key}"
}
data = {
"prompt": prompt,
"n": n,
"size": size,
"response_format": response_format,
}
# Convert the image to RGBA format
image = Image.open(image)
image = image.convert("RGBA")
# Convert the image to bytes
with BytesIO() as output:
image.save(output, format='PNG')
contents = output.getvalue()
files = {
"image": ("image.png", contents),
}
if mask is not None:
# Open the mask image
mask_image = Image.open(mask)
mask_image = mask_image.convert("RGBA")
# Convert the mask image to bytes
with BytesIO() as output:
mask_image.save(output, format='PNG')
contents = output.getvalue()
files["mask"] = ("mask.png", contents)
response = requests.post(endpoint, headers=headers, data=data, files=files)
if response.ok:
# Get the edited image
response_data = response.json()["data"][0]
if response_format == "url":
image_data = response_data["url"]
response = requests.get(image_data)
with open('data.jpg', 'wb') as f:
f.write(response.content)
elif response_format == "b64_json":
image_data = response_data["b64_json"]
# Save image to file
with open('data.jpg', 'wb') as f:
f.write(base64.b64decode(image_data))
return image_data
else:
raise Exception(f"Failed to generate edited image: {response.content}")
image = "image.png"
file_size = os.path.getsize(image)
print(f'The size of {image} is {file_size} bytes.')
mask = "image.png"
prompt = "让这只小狗在可爱一点"
url = generate_edited_image(image, prompt, mask=mask,response_format="b64_json")
print(url)
以上提供的代码实现了一个编辑图片的函数 generate_edited_image(),你可以在其中指定要编辑的原始图片、图片的描述文本提示、遮罩层图片(可选)、编辑生成图片的数量、编辑生成图片的大小等参数,然后调用该函数即可生成编辑后的图片。在代码中,生成的编辑后的图片可以以 Base64 编码后的 JSON 字符串或 URL 的形式返回,你可以根据自己的需求选择合适的返回格式。
五.使用audio API实现音频翻译
首先,准备一个音频文件,当然你可以用我提供的。
这里我是从网上随便找的英语广播原声听力音频。
链接地址如下,你可以打开浏览器下载。
https://aod.cos.tx.xmcdn.com/group26/M08/E3/FC/wKgJRljdFw6xP42DAA4MfO1UHGs723.m4a
Linux可以执行如下命令下载:
wget https://aod.cos.tx.xmcdn.com/group26/M08/E3/FC/wKgJRljdFw6xP42DAA4MfO1UHGs723.m4a
OpenAI API提供了一种简单的方式将音频文件转换为文本。
这里我们通过调用调用API,将音频文件和其他参数发送到API端点,API将返回转录后的文本。
以下是使用OpenAI API将音频文件转换为文本的代码示例:
import requests
def transcribe_audio(file_path, api_key,model_id='whisper-1', prompt="", response_format="json", temperature=0, language=""):
"""
使用OpenAI API将音频文件转换为文本。
参数:
file_path:要转录的音频文件路径。
model_id:要使用的模型ID。目前只有whisper-1可用。
prompt:用于指导模型风格或继续先前音频段的可选文本(就是当前音频的主题)。prompt应该与音频语言相匹配。
response_format:转录输出的格式。可选项为:json,text,srt,verbose_json或vtt。默认为json。
temperature:采样温度,介于0和1之间。较高的值(如0.8)将使输出更随机,而较低的值(如0.2)将使其更加集中和确定性。如果设置为0,则模型将使用对数概率自动增加温度,直到达到某些阈值。
language:输入音频的语言(需要转译的语言类型)。使用ISO-639-1格式提供输入语言将提高准确性和延迟。对应的规范文档参考地址:https://en.wikipedia.org/wiki/List_of_ISO_639-1_codes
返回:
如果请求成功,返回响应的文本格式。否则返回None。
"""
url = "https://api.openai.com/v1/audio/transcriptions"
headers = {"Authorization": f"Bearer {api_key}"}
# 将参数放入字典中,供requests.post使用
data = {"model": model_id, "prompt": prompt, "response_format": response_format, "temperature": temperature, "language": language}
files = {"file": open(file_path, "rb")}
# 发送post请求
try:
response = requests.post(url, headers=headers, data=data, files=files)
if response.ok:
return response.text
else:
print("请求失败,错误码:", response.status_code)
print("msg:",response.text)
except requests.exceptions.RequestException as e:
print("请求异常:", e)
return None
# 替换 YOUR_API_KEY, FILE_PATH 和 YOUR_INPUT_LANGUAGE 为您自己的值
api_key = 'YOUR_API_KEY'
file_path = '你的文件'
language = 'en'
prompt ="Young people's creativity"
transcription_text = transcribe_audio(file_path=file_path, api_key=api_key, prompt=prompt,language=language)
print(transcription_text)
运行代码后结果如图:

如果你想让他翻译为中文,只需要将language 改为zh。
# 替换 YOUR_API_KEY, file_path 和 YOUR_INPUT_LANGUAGE 为您自己的值
api_key = ''
file_path = 'wKgJRljdFw6xP42DAA4MfO1UHGs723.m4a'
language = 'zh'
prompt ="Young people's creativity"
transcription_text = transcribe_audio(file_path=file_path, api_key=api_key, prompt=prompt,language=language,)
print(transcription_text)
运行后结果如下:

看起来有点语句不通,这是因为目前这个接口对中文并不是很友好,所以一般建议还是使用英文。
好了,到这里就实现了一些简单的翻译工具。
当然,官网也还提供了一些其他的API接口,大家可以去看一下,
OpenAI官网API文档:https://platform.openai.com/docs/api-reference/introduction
六.总结
01.AI会替代谁的工作?
OpenAI 创始人曾说到,AI 将取代谁的工作,十年前大部分人认为的顺序:
蓝领 > 低技能白领 > 高技能白领 > 创造性作(也许不会发生)
现在事实证明: AI 最有可能取代的反而是创造性工作。
这种预测说明人类可能不够了解自己,不清楚什么类型的技能最难,最需要调动大脑,或者错误估计了控制身体的难度。
工业革命解决了“重复体力劳动”的事情,人工智能未来解决“重复脑力劳动”的事情。
就像工业机器替代体力劳动者那样,越来越多的脑力劳动者也会因智能机器人的加入得以解放,随之而来的是工作流的调整和组织的重构。
在过去的几百年里,每次革命都在摧毁一些职业的同时创造一些新的工作岗位人工智能时代也是一样,单纯的智能不会解决所有的问题,机器和人将协同工作。
因为时代在不断的发生变化,未来可能需要的不是专才,而是通才。
02.人工智能真的会替代人吗?
这也是个非常热门的一个话题。
在Copilot 刚出来的时候,人们AI将要取代程序员,但是Copilot最终成倍的增加了程序员的生产力。
张小龙也曾说过:“希望我们的产品能成为用户的朋友,而不仅仅是工具。”当然,这句话套用到人工智能时代同样适用。
人工智能不会取代你,因为人是会犯错误的,机器永远只是做认为正确的事情,但是会使用人工智能的人才会取代你。
因为会使用人工智能的人,一个人可以干几个人的活。
所以,AI时代的浪潮力,学习与AI共生,学习如何promoting,让机器做机器擅长的事情,让人类发挥人类的特长,让人工智能拓展人类智能。
机器与人,和而共生,彼此关爱,共享未来。
好了,今天的分享就到这里,希望本文能够帮助到你,欢迎大家点赞,转发,评论!
















 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











