







 本文介绍了使用决策树实现WIFI室内定位的原理和具体步骤,包括数据采集、训练集和测试集的构建、坐标建立及代码实现。在决策树分类和回归算法下,通过对比不同参数的误差,发现'gini'参数下的平均误差最小,为6.565m。同时,文章也分析了误差来源并提供了数据集和源代码链接。
本文介绍了使用决策树实现WIFI室内定位的原理和具体步骤,包括数据采集、训练集和测试集的构建、坐标建立及代码实现。在决策树分类和回归算法下,通过对比不同参数的误差,发现'gini'参数下的平均误差最小,为6.565m。同时,文章也分析了误差来源并提供了数据集和源代码链接。
WIFI室内定位——位置指纹法的实现(决策树)
| 位置指纹法中常用的算法之一是决策树:本文介绍决策树用于定位的基本原理与具体实现(python)。 |
|---|
基本原理
位置指纹法可以看作是分类或回归问题(特征是RSS向量,标签是位置),监督式机器学习方法可以从数据中训练出一个从特征到标签的映射关系模型。
决策树:是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果,本质是一颗由多个判断节点组成的树。决策树主要指CART(classification and regression tree)算法,内部结点特征的取值为“是”和“否”, 为二叉树结构。
- 决策树回归: 所谓回归,就是根据特征向量来决定对应的输出值。回归树就是将特征空间划分成若干单元,每一个划分单元有一个特定的输出。因为每个结点都是“是”和“否”的判断,所以划分的边界是平行于坐标轴的。对于测试数据,我们只要按照特征将其归到某个单元,便得到对应的输出值。
- 决策树分类: 能够根据特征值一层一层的将数据集进行分类。它的优点在于计算复杂度不高,分类出的结果能够很直观的呈现,但是也会出现过度匹配的问题。使用ID3算法的决策树分类第一步需要挑选出一个特征值,能够将数据集最好的分类,之后递归构成分类树。使用信息增益,来得到最佳的分类特制。
具体实现
数据采集:
地点:图书馆二层
采集方法:根据地面砖块的分布,分成25*25个区域,每一个区域取5个点(砖块的4个顶点和中心1个点),每个点选取5个相对稳定的IP(注意要尽量避免手机移动),共测出125份数据,其中训练数据100份 测试数据随机抽取的25份;
测试集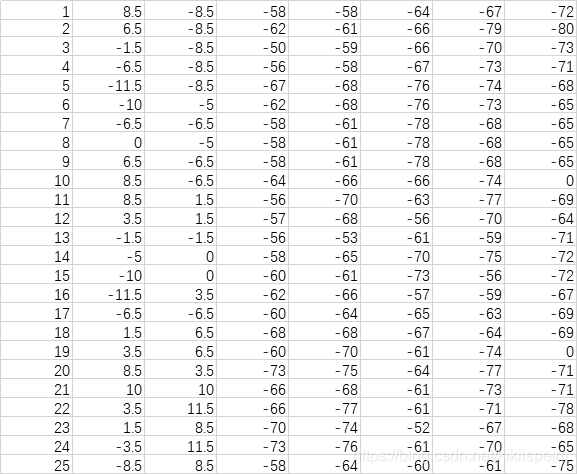
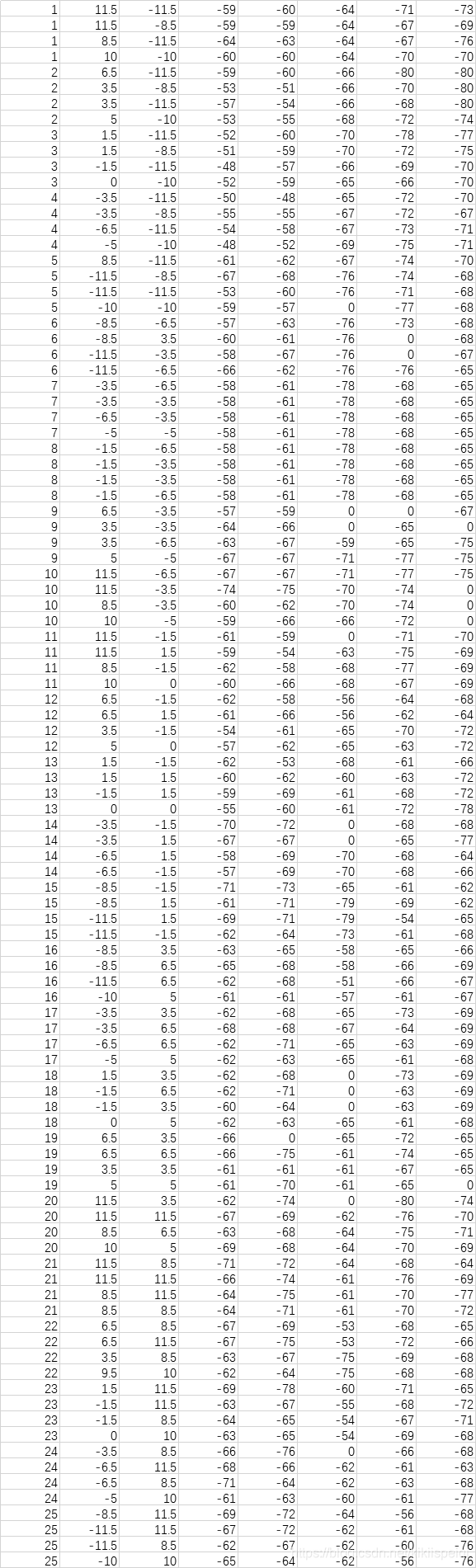
训练集
|
建立坐标
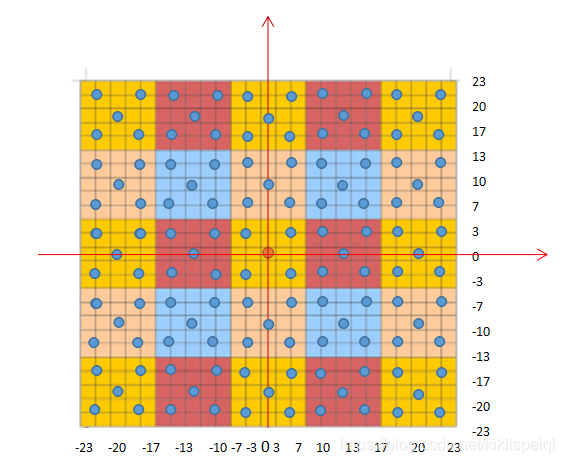
| 取中心点为坐标(0,0点 |
|---|
代码实现
导入数据
| 获取数据,将数据分为训练集和测试集 |
|---|
TrainData = xlrd.open_workbook('train.xlsx')
table = TrainData.sheets()[0]
nrows = table.nrows
ncols = table.ncols
TrainX = [([0] * (ncols - 3 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









