







 本文介绍了ArcGIS中的空间统计工具,包括热点分析、分组分析和聚类异常值检测。热点分析用于识别高值和低值的聚集区域,分组分析通过属性和空间关系对数据进行自然聚类,聚类异常值分析则能发现统计显著的异常值。这些工具在犯罪分析、城市规划等领域有广泛应用。
本文介绍了ArcGIS中的空间统计工具,包括热点分析、分组分析和聚类异常值检测。热点分析用于识别高值和低值的聚集区域,分组分析通过属性和空间关系对数据进行自然聚类,聚类异常值分析则能发现统计显著的异常值。这些工具在犯罪分析、城市规划等领域有广泛应用。

这组工具中包含众所周知的热点分析工具,通过这个工具我们能捕获到大量数据中的热点和冷点,对我们分析问题有很大的帮助。例如,在犯罪分析中,我们可以研究哪些位置犯罪频繁并且聚集,对增设警力有重要的辅助作用。工具集中的其他工具也有类似的作用,都是通过执行聚类分析来识别具有统计显著性的热点、冷点和空间异常值的位置。
依照惯例,我们还是 one by one 来看。
Similarity Search
相似搜索工具,顾名思义,工具根据要素属性确定哪些候选要素与输入要素最相似或者最不相似。
举个栗子:
我希望找到与圣地亚哥5岁以下儿童、未成年人、65岁以上老年人人数分布相似的城市:
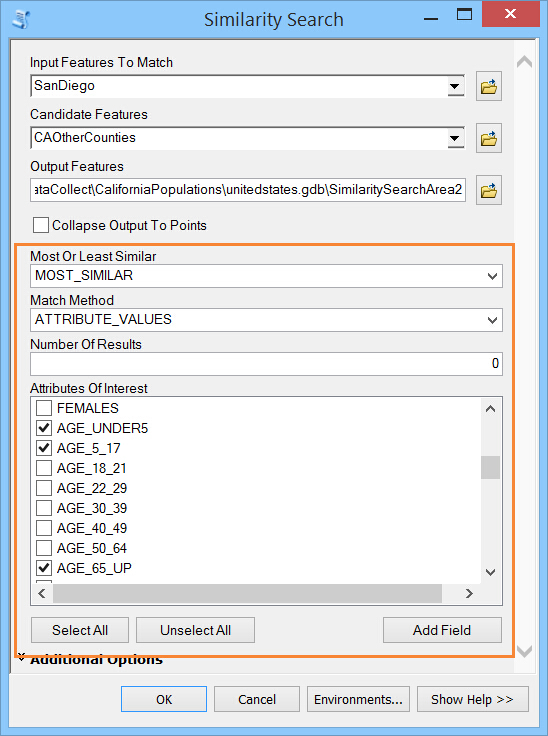
工具中我做如下配置:
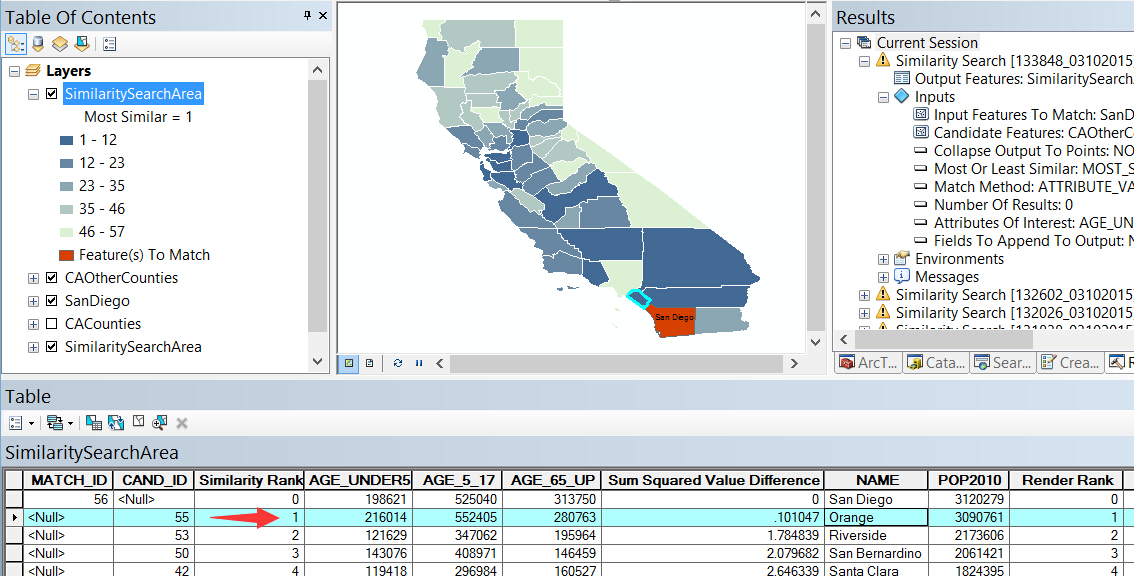
结果在这里,其中 Similarly Rank 为 1 的即为三个年龄属性最相似的城市 Orange:
匹配方法参数中提供了3种算法,分别为:属性值、等级属性值或属性剖面(余弦相似性)。
可能的应用:
- 人力资源经理可能希望能够证明公司的工资范围。找出在大小、生活成本、市容建筑方面相似的城市后,她便可以查看这些城市的工资范围,从而查看他们是否在此行列。
- 犯罪分析师希望搜索数据库以查看某罪行是否属于较重犯罪形式或有重罪趋势。
- 课外健身计划在 A 城极其成功。计划提倡者期望找到与其计划推广的候选城市具有相似特征的其他城市。
- 执法机构用此方法揭露毒品种植地或生产地。标识具有相似特征的地方可能有助于制定未来的搜索目标。
- 大型零售商不仅拥有数个成功店铺,也有少数业绩不佳的店铺。找到一些具有相似人口特征和环境特征(交通便利性、知名度以及商业互补性等等)的地方有助于标识新店的最佳位置。
Grouping Analysis
我们在学习研究事物时,有事需要对事物进行归类
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3224
3224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









