






大模型——阿里Wan2.1 ComfyUI本地部署保姆级教程,最低8G显存可跑。
前段时间,阿里开源了万相视频生成大模型Wan2.1系列,在评测集VBench中,万相2.1超越了Sora、Luma、Pika等国内外开源模型。
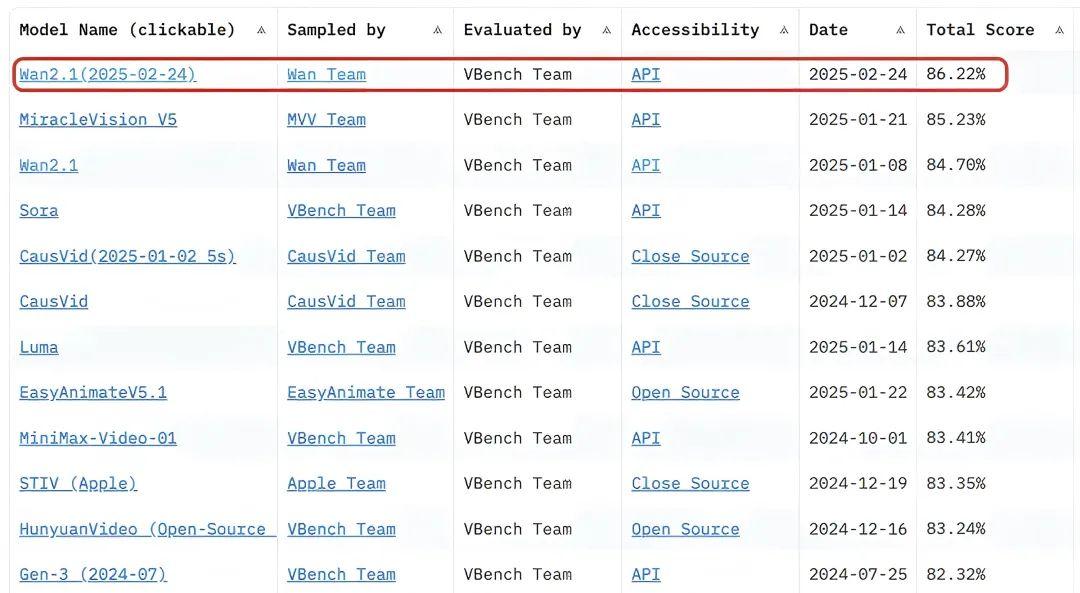
△https://huggingface.co/spaces/Vchitect/VBench_Leaderboard
具体来说,Wan2.1开源了文生视频和图生视频两种模型。
其中,文生视频模型有1.3B和14B两种大小,图生视频模型大小都是14B,不过,一个是480P,另一个是720P。

大尺寸14B版本主打高性能,但1.3B小版本适合消费级显卡,只需要 8.2GB 显存就可以生成 480P 高质量视频。
也即是说,只要你有一张4060显卡(8G显存),就能跑得动这个模型,并且可以在大约4分钟以内生成5秒的480p视频。
刚好,ComfyUI官方也支持了Wan2.1模型,所以,这篇文章就带大家一步一步在本地部署Wan2.1模型。
一、ComfyUI整合包下载
先去B站UP主秋葉aaaki发布的这条视频留言区下载最新的ComfyUI整合包,链接在此:
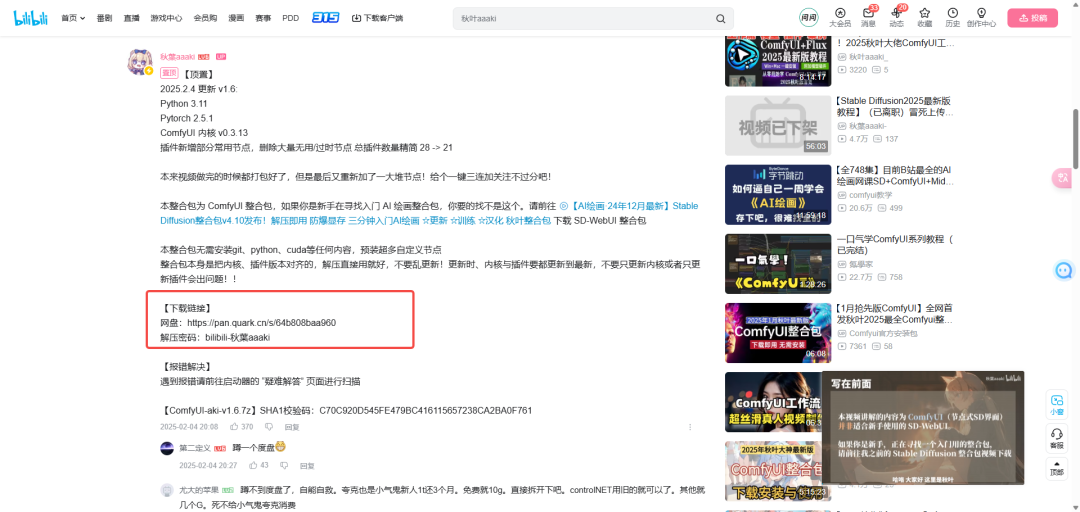
我把夸克网盘的下载链接直接贴出来:
网盘链接:https://pan.quark.cn/s/64b808baa960
解压密码:bilibili-秋葉aaaki
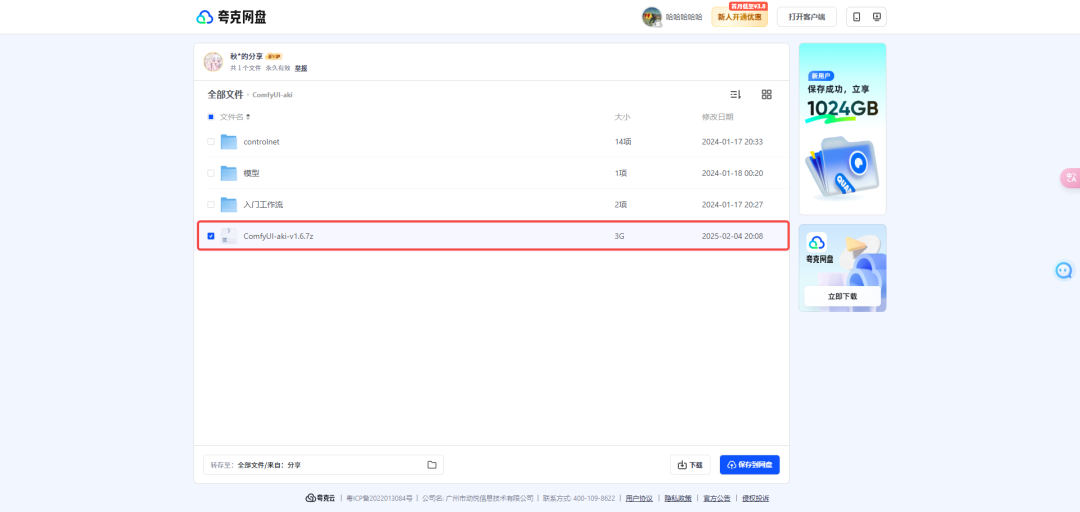
网盘里面包含了四个文件,只需要下载ComfyUl-aki-v1.6.7z本体文件,其他文件可以不需要下载。
注意解压的时候需要解压密码,解压后放到D盘或者其他磁盘空间比较大的硬盘。
二、clip_vision下载
打开下面这个页面,下载clip_vision:
https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/clip_vision
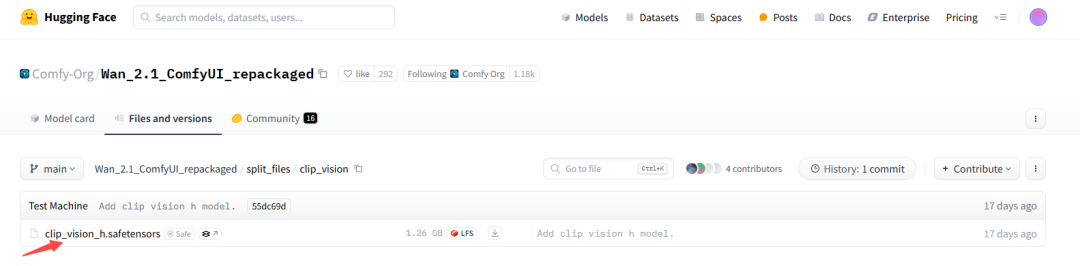
下载到本地后,移到ComfyUI整合包的ComfyUI\models\clip_vision目录下。
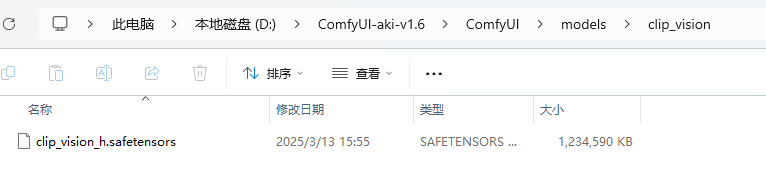
三、diffusion_models下载
打开下面这个页面,下载diffusion_model:
https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/diffusion_models
Wan2.1模型支持文生视频和图生视频两种方式,每种方式下又有14B和1.3B两种尺寸的模型,其中:
- 文生视频
- wan2.1_t2v_1.3B的模型,最大只支持生成832×480像素视频
- wan2.1_t2v_14B的模型,支持1280×720像素和832×480像素视频
- 图生视频
- wan2.1_i2v_480p_14B的模型,最大支持生成832×480像素视频
- wan2.1_i2v_720p_14B的模型,最大支持生成1280×720像素视频
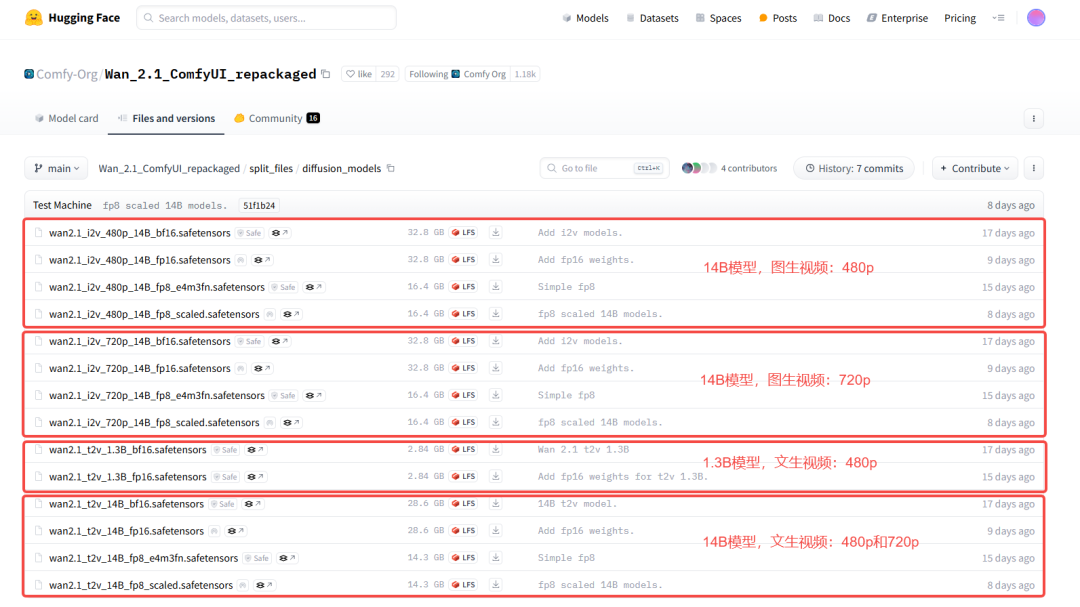
同时,每个尺寸的模型下也有多个模型,根据生成质量的优劣,按照如下原则选择(质量等级从高到低):
fp16 > bf16 > fp8_scaled > fp8_e4m3fn
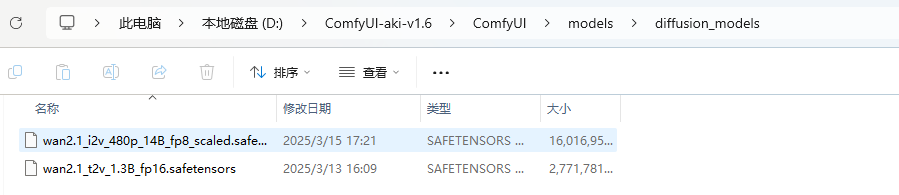
结合自己的显存大小,我选择这两个模型下载到本地:
- 文生视频:
wan2.1_t2v_1.3B_fp16.safetensors - 图生视频:
wan2.1_i2v_480p_14B_fp8_scaled.safetensors
然后移到ComfyUI整合包的ComfyUI\models\diffusion_models目录下面。
四、text_encoders下载
打开下面这个页面,下载text_encoders:
https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/text_encoders
- 如果显存 >= 12G,选择第一个text_encoder
下载 - 如果显存 < 12G,选择第二个text_encoder
下载
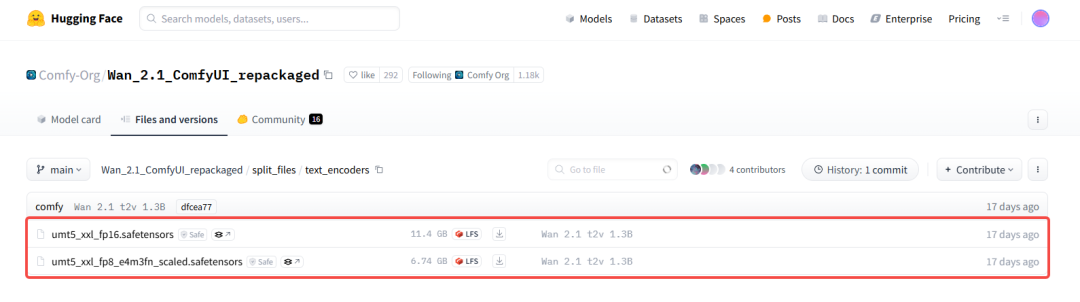
我下载一个小一点的,然后移到ComfyUI整合包的ComfyUI\models\text_encoders目录下。
五、vae下载
打开下面这个页面,下载vae:
https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/vae
下载到本地后,移到ComfyUI整合包的ComfyUI\models\vae目录下。
六、工作流下载
打开下面这个页面,下载工作流:
https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/example%20workflows_Wan2.1
我们根据第三步下载的diffusion_model,相对应地选择第一个和第三个工作流下载:
然后移到ComfyUI整合包的ComfyUI\user\default\workflows目录下:
七、文生视频
第一步,打开秋叶启动器,更新到最新的版本,然后一键启动。
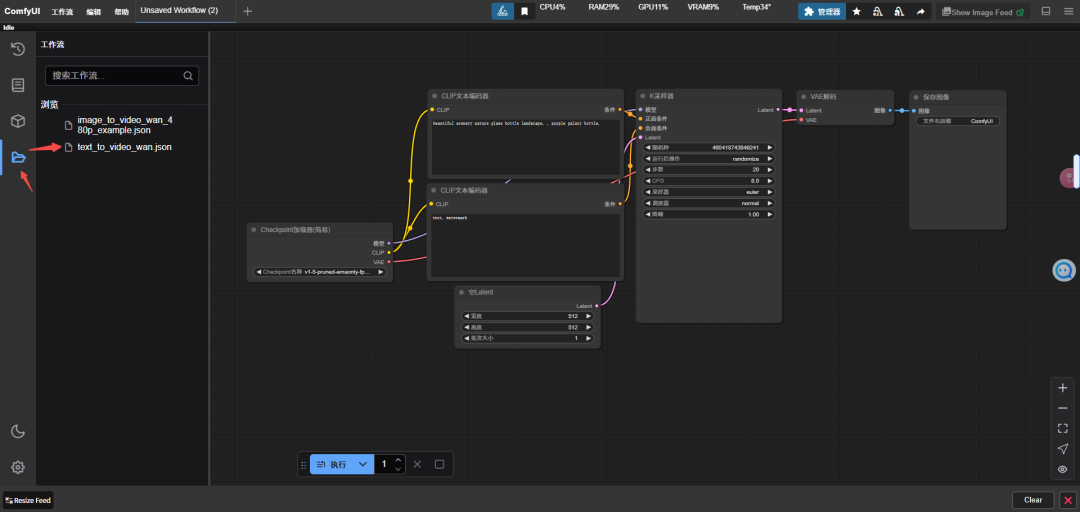
第二步,点击左边侧栏,打开文生视频工作流。
第三步,调整diffusion_model、text_encoder和vae的配置,选择之前下载好的模型。
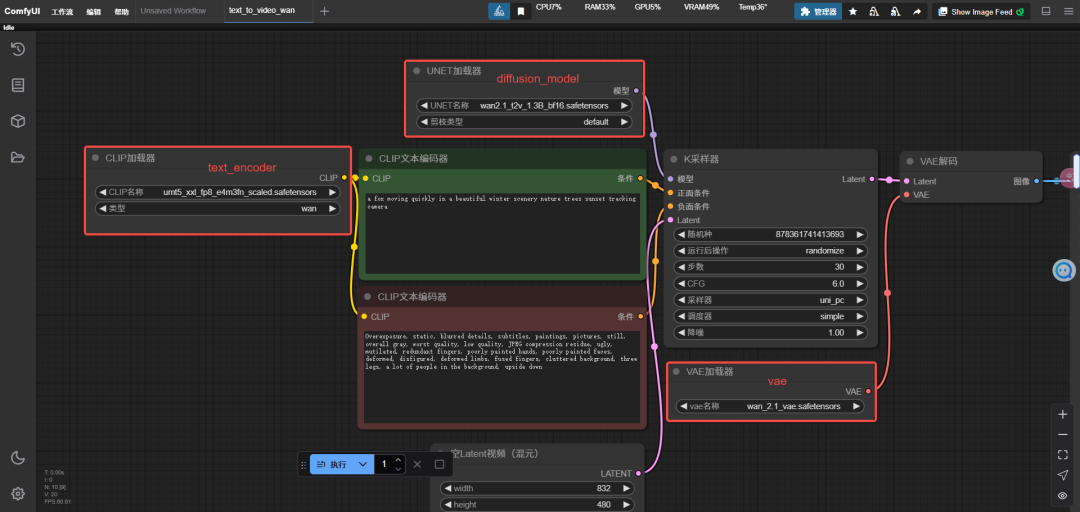
第四步,在CLIP文本编码器框输入正向提示词,最后点执行按钮,开始生成视频。
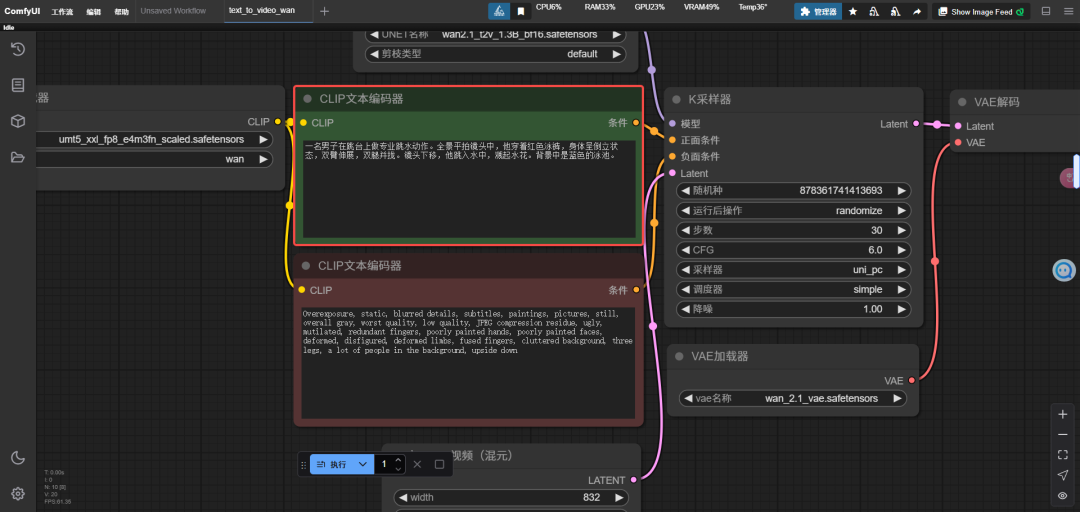
以下是一些测试案例
提示词:一名男子在跳台上做专业跳水动作。全景平拍镜头中,他穿着红色泳裤,身体呈倒立状态,双臂伸展,双腿并拢。镜头下移,他跳入水中,溅起水花。背景中是蓝色的泳池。

提示词:体育摄影风格,骑手在场地障碍赛中引导马匹快速通过障碍物。骑手身着专业比赛服,头戴安全帽,表情专注而坚定,双手紧握缰绳,双腿夹紧马腹,与马匹完美配合。马匹腾空跃起,动作连贯且准确,四蹄有力地踏过每一个障碍物,保持速度和平衡。背景是自然的草地和蓝天,画面充满动感和紧张感。4K, 高清画质,动作完整。

提示词:红色橡胶球从高处自由下落到水泥地面,弹跳后静止,摄像机固定视角侧拍,写实风格,慢动作细节。

提示词:两只拟人化的猫咪身穿紧身拳击服,戴着鲜艳的手套,在聚光灯下的拳击台上激烈对决。它们眼神坚定,肌肉紧绷,展现出专业拳击手的力量与敏捷。一只花斑狗裁判站在一旁,吹着哨子,公正地掌控比赛节奏。四周观众席上的动物们欢呼雀跃,为比赛增添热烈氛围。猫咪的拳击动作迅速而有力,爪子在空中划出一道道模糊的轨迹。画面采用动感模糊效果,捕捉瞬间的激烈交锋,展现出比赛的紧张与刺激。近景特写,聚焦于拳台上的激烈对抗。

提示词:美妆短视频,特写镜头下,一位年轻女性正在细致涂抹睫毛膏。画面聚焦于她的眼部,只见她从睫毛根部开始,缓缓而均匀地向上刷动,睫毛膏的质地轻薄,轻易附着于每一根睫毛。每一次刷动都能明显看到睫毛变得更加纤长卷翘,根根分明的效果如同小扇子般逐渐展现,整个过程流畅自如。视频精准捕捉了睫毛膏带来的惊艳效果。近景特写,细腻清晰的画面质感。

八、图生视频
第一步,点击左边侧栏,打开图生视频工作流。
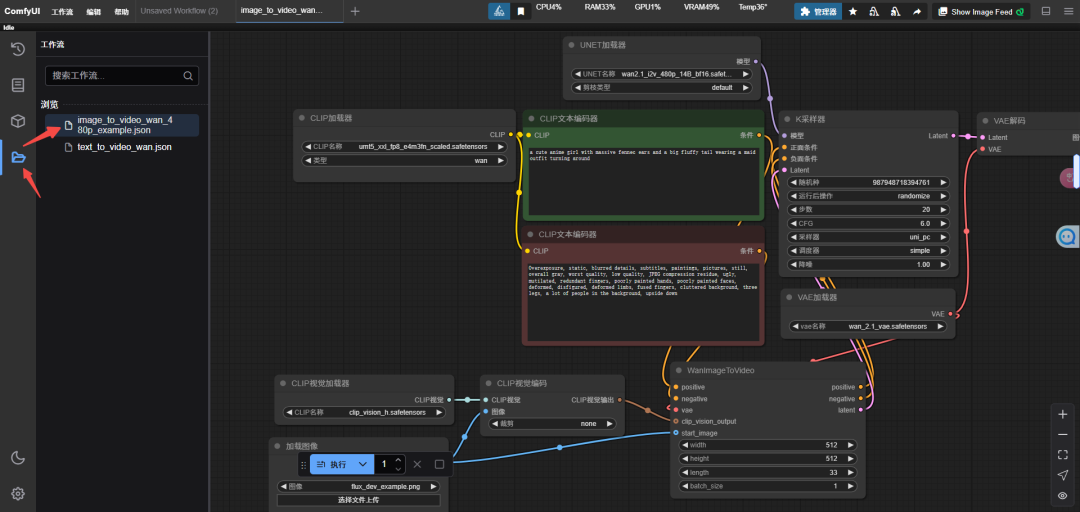
第二步,调整diffusion_model、text_encoder、clip_vision和vae的配置,选择之前下载好的模型。
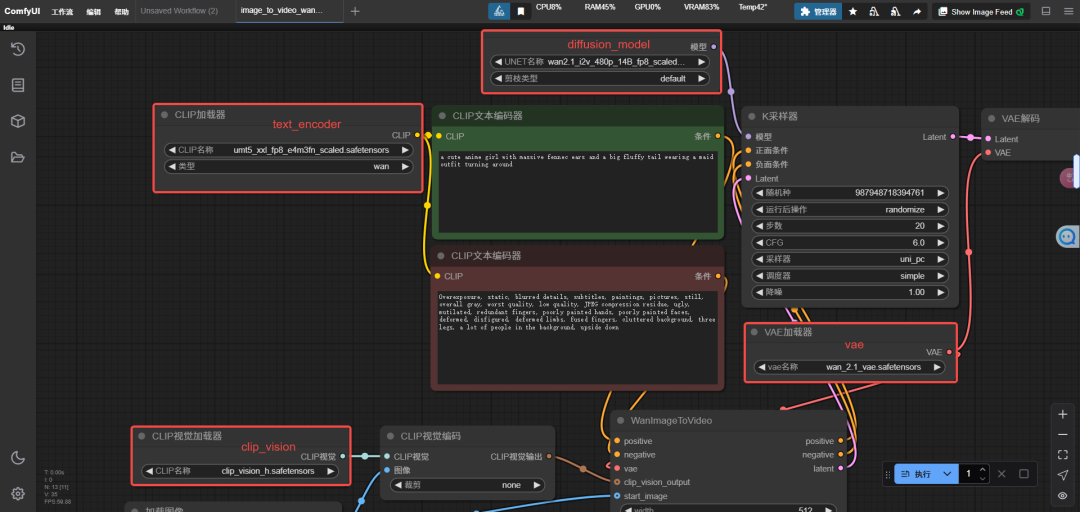
从上图可以看到,图生视频的工作流相比文生视频,有两个主要的区别:
1、多了一个clip_vision的节点;
2、diffusion_model换成了图生视频的模型。
第三步,上传图片,并在CLIP文本编码器框输入正向提示词,最后点执行按钮,开始生成视频。
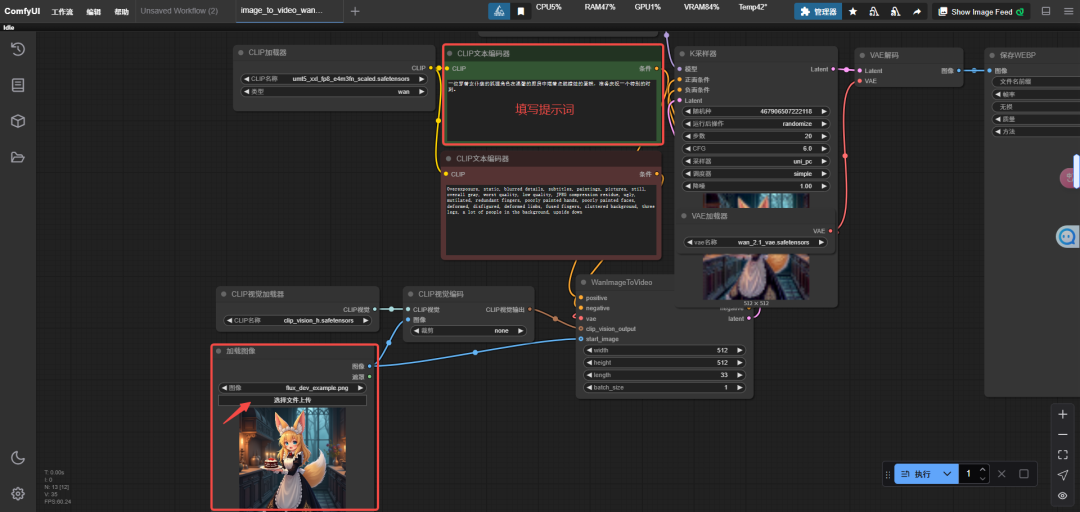
以下是一些测试案例
提示词:一位穿着女仆装的狐狸角色在温馨的厨房中端着点燃蜡烛的蛋糕,准备庆祝一个特别的时刻。

提示词:一位可爱的小白兔女生在往前走,并挥手打招呼。

提示词:给图片中的美女戴上墨镜。

只能说效果还可以,但是没有特别好,还是和模型大小有关,模型太小生成的视频质量就很一般。
如果有条件的话,还是需要跑14B的模型效果会好很多,但是本地跑ComfyUI只支持单GPU,所以上限也就在这了,对于普通人有一张消费级的4090显卡顶天了。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











