







https://blog.csdn.net/king52113141314/article/details/120259516
目录
2,How to choose Loss and Activation Functions and Metrics and Optimizer
Activation Functions' Choices:
Run tests in a Single Directory
Run tests in a Single Test File/Module
Run a Single Test Method of a Test Class
Run a Set of Tests Based on Test Name
5,the Difference Between Multi-Class and Multi-Label Classification
6,keras.callbacks.EarlyStopping
1, TensorFlow2.0学习
简单粗暴 TensorFlow 2 | A Concise Handbook of TensorFlow 2 — 简单粗暴 TensorFlow 2 0.4 beta 文档
https://www.bookstack.cn/read/eat_tensorflow2_in_30_days-zh
https://blog.csdn.net/qq_40643699/category_10545446.html
https://blog.csdn.net/qq_38251616/category_10732944.html
TensorFlow2简单入门-图像加载及预处理_K同学啊的博客-CSDN博客
深度学习100例-循环神经网络(LSTM)实现股票预测 | 第10天_K同学啊的博客-CSDN博客_lstm神经网络预测股票
https://developers.google.com/machine-learning/crash-course/ml-intro
https://github.com/monroyaume5/100-Days-Of-ML-Code
3搭建神经网络的套路(之一):用Tensorflow API--tf.keras搭建网络(六步法)_TypicalSpider的博客-CSDN博客
Tensorflow实现卷积神经网络识别MNIST - 斐斐のBlog
2,How to choose Loss and Activation Functions and Metrics and Optimizer
对于回归任务:要么使用linear,要么使用 ReLU。
- Take care of the output of your network. If that's a Real number and can take any value, you have to use linear activation as the output.
- ReLU — This results in a numerical value greater than 0
-
Loss Function:Mean squared error (MSE)
ReLU belongs to Linear
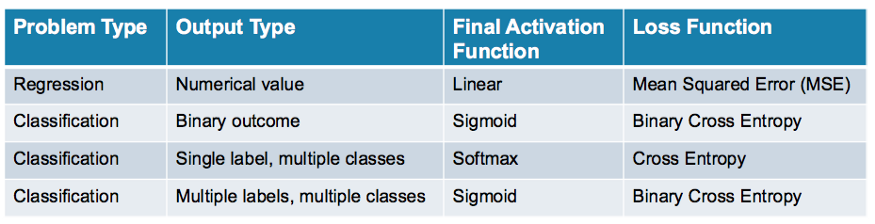
Activation Functions' Choices:
https://medium.com/analytics-vidhya/activation-functions-all-you-need-to-know-355a850d025e
神经网络炼丹术:神经网络调参_yilyil的博客-CSDN博客
sigmod
1. 输入太小或太大无梯度,因为接近0了
2. exp复杂计算
3. 梯度容易消失y(1-y),多层梯度很小
4. 输出均值为0.5
tanh
1. 快,计算量小
2. 输入太小或太大无梯度
3. 输出均值为0
ReLu
1. 快,计算量小,
2. 梯度不会太小
3. 输出均值非0
4 . 非常大的梯度流过神经元就不会有激活现象
leaky ReLu : ReLu改善
x小于0时乘以系数,就会更小,不会一直为0
ELU
1. 均值接近0
2. 小于0时exp难算
使用方式:
1. 小心设置ReLu学习率
2. 不要使用sigmod
3. 推荐使用 leaky ReLu,ELU
4. 试试 tanh
Metrics的选择:
Keras Metrics: Everything You Need To Know - neptune.ai
Regression:
The metrics used in regression problems include Mean Squared Error, Mean Absolute Error, and Mean Absolute Percentage Error.
from keras import metrics model.compile(loss='mse', optimizer='adam', metrics=[metrics.mean_squared_error, metrics.mean_absolute_error, metrics.mean_absolute_percentage_error])
Multiclass classification
These metrics are used for classification problems involving more than two classes.
keras.metrics.categorical_accuracy(y_true, y_pred)
keras.metrics.sparse_categorical_accuracy(y_true, y_pred)
keras.metrics.top_k_categorical_accuracy(y_true, y_pred, k=5)
Binary classification
Binary classification metrics are used on computations that involve just two classes.
keras.metrics.binary_accuracy(y_true, y_pred, threshold=0.5)
keras.metrics.accuracy(y_true, y_pred)
keras.metrics.confusion_matrix(y_test, y_pred)
3.3. Metrics and scoring: quantifying the quality of predictions — scikit-learn 1.0.1 documentation
| Scoring | Function | Comment |
|---|---|---|
| Classification | ||
| ‘accuracy’ | ||
| ‘balanced_accuracy’ | ||
| ‘top_k_accuracy’ | ||
| ‘average_precision’ | ||
| ‘neg_brier_score’ | ||
| ‘f1’ | for binary targets | |
| ‘f1_micro’ | micro-averaged | |
| ‘f1_macro’ | macro-averaged | |
| ‘f1_weighted’ | weighted average | |
| ‘f1_samples’ | by multilabel sample | |
| ‘neg_log_loss’ | requires | |
| ‘precision’ etc. | suffixes apply as with ‘f1’ | |
| ‘recall’ etc. | suffixes apply as with ‘f1’ | |
| ‘jaccard’ etc. | suffixes apply as with ‘f1’ | |
| ‘roc_auc’ | ||
| ‘roc_auc_ovr’ | ||
| ‘roc_auc_ovo’ | ||
| ‘roc_auc_ovr_weighted’ | ||
| ‘roc_auc_ovo_weighted’ | ||
| Clustering | ||
| ‘adjusted_mutual_info_score’ | ||
| ‘adjusted_rand_score’ | ||
| ‘completeness_score’ | ||
| ‘fowlkes_mallows_score’ | ||
| ‘homogeneity_score’ | ||
| ‘mutual_info_score’ | ||
| ‘normalized_mutual_info_score’ | ||
| ‘rand_score’ | ||
| ‘v_measure_score’ | ||
| Regression | ||
| ‘explained_variance’ | ||
| ‘max_error’ | ||
| ‘neg_mean_absolute_error’ | ||
| ‘neg_mean_squared_error’ | ||
| ‘neg_root_mean_squared_error’ | ||
| ‘neg_mean_squared_log_error’ | ||
| ‘neg_median_absolute_error’ | ||
| ‘r2’ | ||
| ‘neg_mean_poisson_deviance’ | ||
| ‘neg_mean_gamma_deviance’ | ||
| ‘neg_mean_absolute_percentage_error’ |
optimizer优化器的选择:
神经网络中的优化器 (tensorflow2.0) - sun-a - 博客园
神经网络中常用操作和优化器 - dangxusheng - 博客园
优先选择Adam,另外大多情况下使用 Nadam 取得更好的效果
3, pytest指令
My answer provides a ways to run a subset of test in different scenarios.
Run all tests in a project
pytest
Run tests in a Single Directory
To run all the tests from one directory, use the directory as a parameter to pytest:
pytest tests/my-directory
Run tests in a Single Test File/Module
To run a file full of tests, list the file with the relative path as a parameter to pytest:
pytest tests/my-directory/test_demo.py
Run a Single Test Function
To run a single test function, add :: and the test function name:
pytest -v tests/my-directory/test_demo.py::test_specific_function
-v is used so you can see which function was run.
Run a Single Test Class
To run just a class, do like we did with functions and add ::, then the class name to the file parameter:
pytest -v tests/my-directory/test_demo.py::TestClassName
Run a Single Test Method of a Test Class
If you don't want to run all of a test class, just one method, just add another :: and the method name:
pytest -v tests/my-directory/test_demo.py::TestClassName::test_specific_method
Run a Set of Tests Based on Test Name
The -k option enables you to pass in an expression to run tests that have certain names specified by the expression as a substring of the test name. It is possible to use and, or, and not to create complex expressions.
For example, to run all of the functions that have _raises in their name:
pytest -v -k _raises4,函数定义时的说明文件
def create_auto_mpg_deep_and_wide_networks(
n_inputs: int, n_outputs: int) -> Tuple[tensorflow.keras.models.Model,
tensorflow.keras.models.Model]:
"""Creates one deep neural network and one wide neural network.
The networks should have the same (or very close to the same) number of
parameters and the same activation functions.
:param n_inputs: The number of inputs to the models.
:param n_outputs: The number of outputs from the models.
:return: A tuple of (deep neural network, wide neural network)
"""
'''
解释:
n_inputs: int,这里的: int代表n_inputs得定义成int数据;
-> Tuple , 这里的-> 代表输出数据类型得是Tuple,就是return: A tuple of (deep neural network, wide neural network)
'''5,the Difference Between Multi-Class and Multi-Label Classification
Difference between Multi-Class and Multi-Label Classification
https://www.instagram.com/deeplearningdemystified/?utm_medium=copy_link
An introduction to MultiLabel classification - GeeksforGeeks
As a short introduction, In multi-class classification, each input will have only one output class, but in multi-label classification, each input can have multi-output classes.
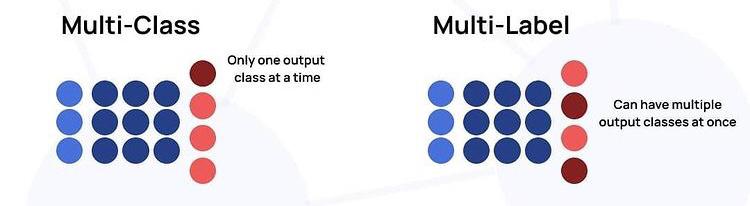
Multi-Class Classification
For example, If we are making an animal classifier that classifies between Dog, Rabbit, Cat, and Tiger, it makes sense only for one of these classes to be selected each time.
In neural networks, we usually use the Sigmoid Activation Function for binary classification tasks while on the other hand, we use the Softmax activation function for multi-class as the last layer of the model.

Multi-Label Classification
Multi-label vs. single-label is the matter of how many classes an object or example can belong to. In neural networks, when single-label is required, we use a single softmax layer as the last layer, learning a single probability distribution that ranges over all classes. In the case where multi-label classification is needed, we use multiple sigmoids on the last layer and thus learn a separate distribution for each class.
For example, If we are building a model which predicts all the clothing articles(衣服类别(帽子也算)) a person is wearing, we can use a multi-label classification model since there can be more than one possible option at once.
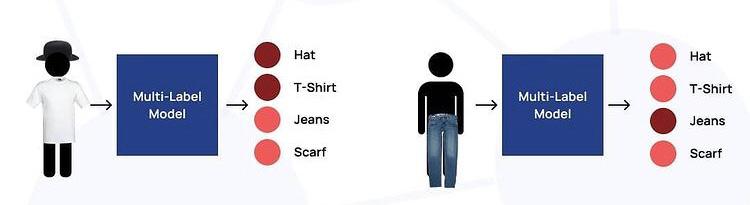
Real-Life Example to Understand the Difference between Multi-Class and Multi-Label Classification
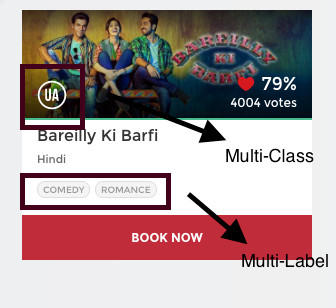
For example, if you look in the above image, then you may see that this movie has been rated as ‘U/A’ (meaning ‘Parental Guidance for children below the age of 12 years) certificate. This is not the only type of certificate but there are other types of certificates classes such as,
- ‘A’ (Restricted to adults), or
- ‘U’ (Unrestricted Public Exhibition),
but while categorizing the movies based on this, it is sure that each movie can only be categorized with only one out of those three types of certificates. In short, there are multiple categories (i.e, multiple certificates assigned to the movie) but each instance is assigned only one (i.e, each movie is assigned with only one certificate at once), therefore such problems are categorized under the multi-class classification problem statement.
Again, if you see carefully the image, then this movie has been categorized into the comedy and romance genres. But this time there is a difference that each of the movies can fall into one or more different sets of categories (i.e, have more than one genre). Therefore, each instance can be assigned with multiple categories (i.,e multiple genres), so these types of problems are categorized under the multi-label classification problem statement, where we have a set of target labels for each of the samples.
- Multi-class classification problems have multiple categories but each instance is assigned only once.
- Multi-label classification problems have each instance can be assigned with multiple categories or a set of target labels.
model = Sequential()
model.add(Dense(128, activation='relu', input_shape=X_train.shape[1]))
model.add(Dropout(0.1))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(y_train.shape[1], activation='sigmoid')) # <-- Notice activation in final layer.
model.compile(loss='binary_crossentropy', # <-- Notice loss function.
optimizer='adam)
For a multiclass classification problem we use
softmaxactivation function. It is because we want to maximize the probability of a single class and softmax ensures that the sum of the probabilities is one. However we usesigmoidactivation function for the output layer in multi-label classification setting. What sigmoid does is that it allows you to have a high probability for all your classes or some of them, or none of them.For a multiclass classification problem we often use
categorical_crossentropyloss. This is useful since we are interested to approximate the true data distribution(where only one class is true). However in multi label classification setting we formulate the objective function like a binary classifier where each neuron(y_train.shape[1]) in the output layer is responsible for one vs all class classification.binary_crossentropyis suited for binary classification and thus used for multi-label classification.
6,keras.callbacks.EarlyStopping
Use Early Stopping to Halt the Training of Neural Networks At the Right Time
# mlp overfit on the moons dataset with simple early stopping
from sklearn.datasets import make_moons
from keras.models import Sequential
from keras.layers import Dense
from keras.callbacks import EarlyStopping
from matplotlib import pyplot
# generate 2d classification dataset
X, y = make_moons(n_samples=100, noise=0.2, random_state=1)
# split into train and test
n_train = 30
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
# define model
model = Sequential()
model.add(Dense(500, input_dim=2, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# simple early stopping,To discover the training epoch on which training was stopped, the “verbose” argument can be set to 1. adding a delay to the trigger in terms of the number of epochs on which we would like to see no improvement. This can be done by setting the “patience” argument.
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1)#verbose=1,mean that output Epoch 00219: early stopping
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0, callbacks=[es])
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
# plot training history
pyplot.plot(history.history['loss'], label='train')
pyplot.plot(history.history['val_loss'], label='test')
pyplot.legend()
pyplot.show()7,卷积神经网络keras实现
Python-深度学习-学习笔记(13):keras搭建卷积神经网络(对二维数据进行一维卷积)_赵小琛在路上的博客-CSDN博客
易 AI - 机器学习卷积神经网络(CNN) | MakeOptim
MaxPooling1D和GlobalMaxPooling1D的区别_zztSky-CSDN博客
Keras学习笔记(四):MaxPooling1D和GlobalMaxPooling1D的区别_林夕-CSDN博客_maxpooling1d
Keras 学习笔记(三)Keras Sequential 顺序模型 - 云+社区 - 腾讯云
L26 使用卷积及循环神经网络进行文本分类_雨人的博客-CSDN博客
8,Python 把较长的一行代码分成多行
Python 把较长的一行代码分成多行的技巧 - 星星和西西 - 博客园
9,HDF5 文件及 h5py
python开源库——h5py快速入门指南 - 那抹阳光1994 - 博客园
- HDF(Hierarchical Data Format)指一种为存储和处理大容量科学数据设计的文件格式及相应库文件,当前流行的版本是 HDF5, 是一种常见的跨平台数据储存文件,可以存储不同类型的图像和数码数据,并且可以在不同类型的机器上传输,同时还有统一处理这种文件格式的函数库。HDF5 拥有一系列的优异特性,使其特别适合进行大量科学数据的存储和操作,如它支持非常多的数据类型,灵活,通用,跨平台,可扩展,高效的 I/O 性能,支持几乎无限量(高达 EB)的单文件存储等,详见其官方介绍:https://support.hdfgroup.org/HDF5/ 。HDF5 文件一般以 .h5 或者 .hdf5 作为后缀名.
- h5py是对HDF5文件格式进行读写的python包
h5py 必知--String存储_苦作舟的人呐-CSDN博客_h5py.file

1. h5py 文件介绍
一个h5py文件是 “dataset” 和 “group” 二合一的容器。
1. dataset : 类似数组组织的数据的集合,像 numpy 数组(arrays)一样工作,每个 dataset 可以分成两部分: 原始数据 (raw) data values 和 元数据 metadata (a set of data that describes and gives information about other data => raw data)。
2. group : 包含了其它 dataset 和 其它 group ,像字典(dictionaries)一样工作,一般也有metadata that describes exactly what the data are.
Hierarchical Data Formats - What is HDF5? | NSF NEON | Open Data to Understand our Ecosystems
Using Hierarchical Data Format (HDF5) in Machine Learning | NaadiSpeaks
There are two important terms used in HDF5 format.
- Groups – Folder like element within the HDF5 file which can contain subgroups or datasets.
- Dataset – Actual data contained within the HDF5 file. (Numpy arrays etc. )
- Metadata-
we might add information about how the data in the dataset were collected, such as descriptions of the sensor used to collect the temperature data. We can also attach information, to each dataset within the site group, about how the averaging was performed and over what time period data are available.
One key benefit of having metadata that are attached to each file, group and dataset, is that this facilitates automation without the need for a separate (and additional) metadata document. Using a programming language, like R or
Python, we can grab information from the metadata that are already associated with the dataset, and which we might need to process the dataset.
In simpler terms, if your data is large, complex, heterogeneous and need random access most probably HDF5 would be the best option you can go forward with.
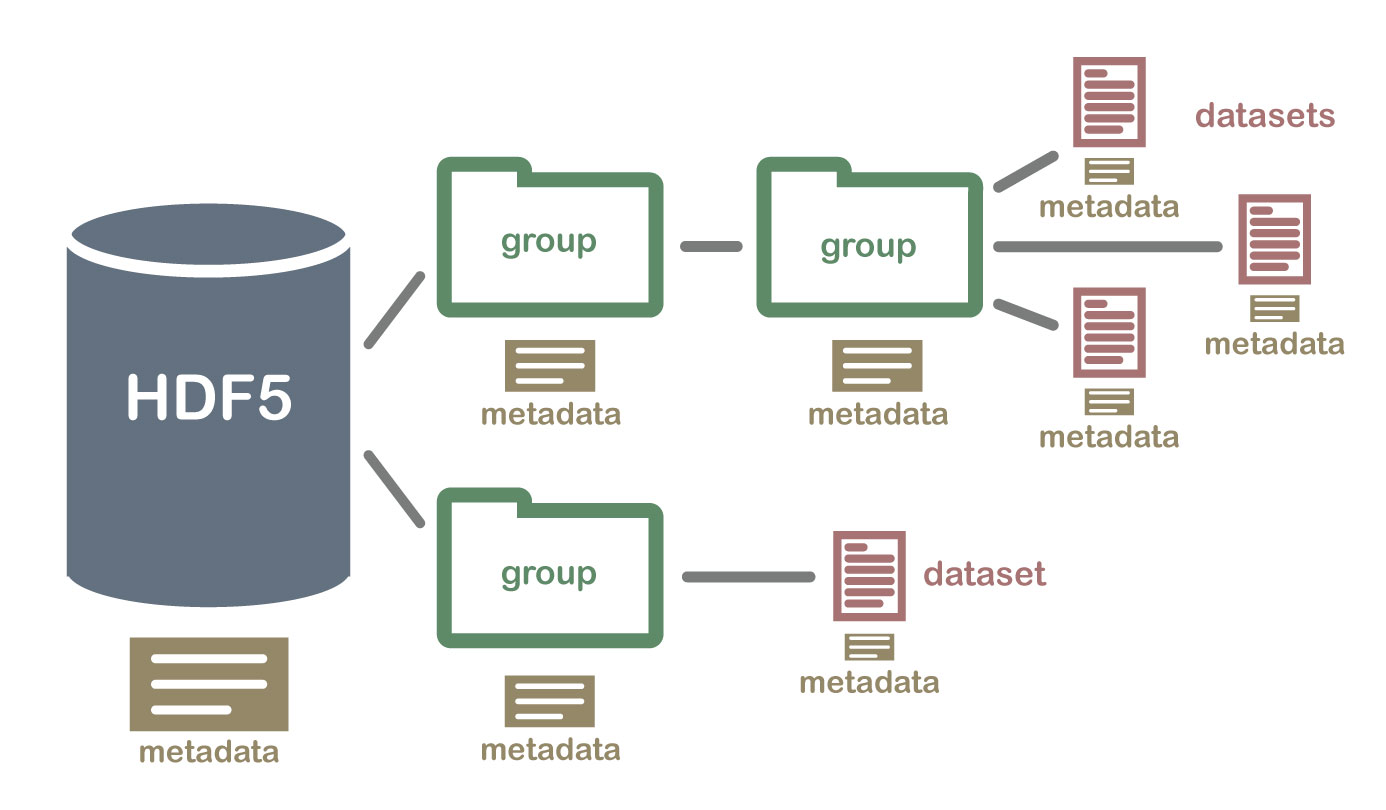
''' h5py_example.hdf5 file structure
+-- '/'
| +-- group "bar1"
| | +-- group "car1"
| | | +-- None
| | |
| | +-- dataset "dset1"
| |
| +-- group "bar2"
| | +-- group "car2"
| | | +-- None
| | |
| | +-- dataset "dset2"
| |
| +-- dataset "dset"
| | +-- attribute "myAttr1"
| | +-- attribute "myAttr2"
| |
|
'''
'''dataset structure
+-- Dataset
| +-- (Raw) Data Values (eg: a 4 x 5 x 6 matrix)
| +-- Metadata
| | +-- Dataspace (eg: Rank = 3, Dimensions = {4, 5, 6})
| | +-- Datatype (eg: Integer)
| | +-- Properties (eg: Chuncked, Compressed)
| | +-- Attributes (eg: attr1 = 32.4, attr2 = "hello", ...)
|
'''
HDF5数据模型介绍及h5py_RS&Hydrology的博客-CSDN博客_hdf5模型
一个 HDF5 文件从一个命名为 "/" 的 group 开始,所有的 dataset 和其它 group 都包含在此 group 下,当操作 HDF5 文件时,如果没有显式指定 group 的 dataset 都是默认指 "/" 下的 dataset,另外类似相对文件路径的 group 名字都是相对于 "/" 的。
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 18 15:07:11 2021
@author: Administrator
https://docs.h5py.org/en/latest/quick.html
"""
import h5py
import numpy as np
'''
r Readonly, file must exist (default)
r+ Read/write, file must exist
w Create file, truncate if exists
w- or x Create file, fail if exists
a Read/write if exists, create otherwise
'''
############################### Creating a hdf5 file
# f1 = h5py.File("mytestfile.hdf5", "w")
# dset = f1.create_dataset("mydataset", (100,), dtype='i')
# for key in f1.keys():
# print(key)
# print(f1[key].name)
# print(f1[key].shape)
# f1.close()
#https://www.cnblogs.com/yaoyue68/p/13793442.html
#更推荐下面方法操作文件,with as保证无论是否出错都能正确地关闭文件,注意运行完with语句时,f文件已经关闭
#,因此有关f的任何属性需要在with语句内打印
"""
keys() : 获取本文件夹下所有的文件及文件夹的名字
f['key_name'] : 获取对应的对象
"""
with h5py.File("mytestfile.hdf5", "w") as f:
#dset = f.create_dataset("mydataset", data=np.arange(16).reshape([4, 4]), dtype='i')
dset = f.create_dataset("mydataset", (16,), data=np.arange(16), dtype='i') #"mydataset"数据集的名字;(16,)数据集的shape;i数据集元素类型
#创建dset2数据集,并直接赋值
f["dset2"]=np.arange(5)
f["dset3"]=np.arange(8)
print(f.name,'\n',f.keys())
for key in f.keys():
print('*'*20,key)
print(f[key].name)#f[key]=dset
print(f[key].shape)
print(f[key]) #https://docs.h5py.org/en/latest/high/dataset.html#dataset
print(f[key][:])
#print(f[key][()])
g1 = f.create_group("subgroup1")
dset4 = g1.create_dataset("dset4", data=np.arange(10))
g1["dset5"]=np.arange(20)
print(f.name,'\n',f.keys(),'\n',g1.keys())
print(dset4.name)
print(dset4[()])
print(g1["dset5"].name)
print(g1["dset5"][()])
print(f["/subgroup1/dset4"][:])
print(f["subgroup1"]["dset4"][:])
# Add two attributes to dataset 'dset'
dset4.attrs["myAttr1"] = [100, 200]
dset4.attrs["myAttr2"] = "Hello, world!"
for key in dset4.attrs.keys():
print(key, ":", dset4.attrs[key])
############################################# Reading a hdf5 file
#f = h5py.File('mytestfile.hdf5', 'a') #we need to open the file in the “append” mode first,so we can add data
with h5py.File('mytestfile.hdf5', 'a') as f:
#g2 = f.create_group("subgroup2")
# Print the keys of groups and datasets under '/'.
print(f.filename, ":")
print([key for key in f.keys()], "\n")
# Read dataset 'dset' under '/'.
d = f["mydataset"]
# Print the data of 'dset'.
print(d.name, ":")
print(d[:])
# Read group 'bar1'.
g = f["subgroup1"]
# Print the keys of groups and datasets under group 'bar1'.
print([key for key in g.keys()])
# Delete a database.
# Notice: the mode should be 'a' when you read a file.
del g["dset4"]
print([key for key in g.keys()]) 10,python描述路径的三种方式
python在描述路径时可以有多种方式,现列举常见的三种
方式一:转义的方式
'd:\\a.txt'
方式二:显式声明字符串不用转义
'd:r\a.txt'
方式三:使用Linux的路径/
'd:/a.txt'
我强烈推荐第三种写法,这在Linux和window下都是行的通的。将路径中的\ 转为 /:
为了防止字符转义,前置'r' 就能保留原有路径的样子
#'r'是防止字符转义的,'\n'就能保留原有的样子
str =r'F:\git_work\ista\convolutionalnetworks\data\Youtube0{0}.csv'
print(str.replace('\\','\\\\')) #将\ 转为 \\
print(str.replace('\\','/')) #将\ 转为 / 使用re.sub()将windows路径转化为Linux路径的方法_哪吒!。的博客-CSDN博客
机器学习中常用的评价指标:

Keras中的回调函数
Python——回调函数(callback)_庄小焱的博客-CSDN博客_python 回调函数
机器学习笔记 - Keras中的回调函数Callback使用教程_坐望云起的博客-CSDN博客_keras callback
现在,我们希望在对训练过程进行监控。这种情况下我们向Keras模型添加回调。回调是一个对象,它可以在训练的各个阶段(例如,在一个时期的开始或结束,单个批次之前或之后等)执行操作。
对于回调的时间点,Keras提供了多个定义。
on_train_begin、on_train_end --- 训练开始、训练结束
on_epoch_begin、on_epoch_end --- 一个epoch开始或结束
on_test_begin、on_test_end --- 评估模型开始或结束
on_predict_begin、on_predict_end --- 预测开始或结束
on_predict_batch_begin、on_predict_batch_end --- 批量预测开始或结束
on_train_batch_begin、on_train_batch_end、on_test_batch_begin、on_test_batch_end --- 批次输入到训练或测试过程之前或之后直接执行特定操作。
class LFW_callback(keras.callbacks.Callback):
def __init__(self, test_loader):
self.test_loader = test_loader
def on_train_begin(self, logs={}):
return
def on_train_end(self, logs={}):
return
def on_epoch_begin(self, epoch, logs={}):
return
def on_epoch_end(self, epoch, logs={}):
labels, distances = [], []
print("正在进行LFW数据集测试")
for _, (data_a, data_p, label) in enumerate(self.test_loader.generate()):
out_a, out_p = self.model.predict(data_a)[1], self.model.predict(data_p)[1]
dists = np.linalg.norm(out_a - out_p, axis=1)
distances.append(dists)
labels.append(label)
labels = np.array([sublabel for label in labels for sublabel in label])
distances = np.array([subdist for dist in distances for subdist in dist])
_, _, accuracy, _, _, _, _ = evaluate(distances,labels)
print('Accuracy: %2.5f+-%2.5f' % (np.mean(accuracy), np.std(accuracy)))
def on_batch_begin(self, batch, logs={}):
return
def on_batch_end(self, batch, logs={}):
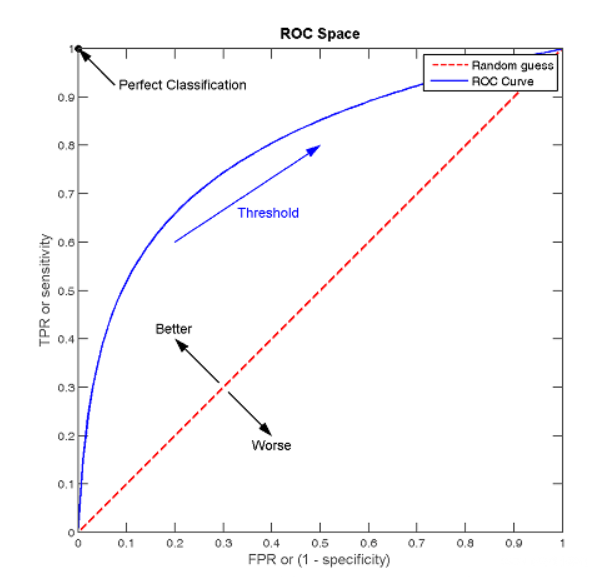
return ROC AUC tpr fpr frr far
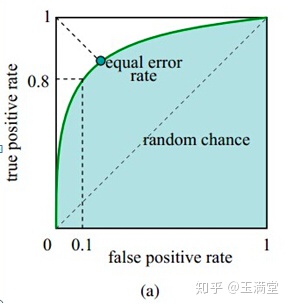
ROC曲线
纵轴:真阳性率(TPR) = TP/(TP+FN) ,与recall等价,即正样本中分类器判断正确的样本数量占比;
横轴:假阳性率(FPR) = FP/(FP+TN) ,即负样本中分类器判断错误的样本数量占比。类似于PR曲线,不同的点在于ROC曲线是用TPR和FPR来绘制的。
TPR和FPR呈现正向的相关关系,FPR提高,TPR也会提高。
假设采用逻辑回归分类器,其给出针对每个实例为正类的概率,那么通过设定一个阈值如0.6,概率大于等于0.6的为正类,小于0.6的为负类。对应的就可以算出一组(FPR,TPR),在平面中得到对应坐标点。随着阈值的逐渐减小,越来越多的实例被划分为正类,但是这些正类中同样也掺杂着真正的负实例,即TPR和FPR会同时增大。阈值最大时,对应坐标点为(0,0),阈值最小时,对应坐标点(1,1)。ROC曲线上每个点都分别对应一个不同的阈值。ROC曲线描述的其实是分类器性能随着分类器阈值的变化而变化的过程。
receiver operating characteristic (ROC)曲线数据越多,阈值分的越细,”曲线”越光滑。 曲线越靠左上角,分类器越佳。
AUC(Area Under Curve)被定义为ROC曲线下与坐标轴围成的面积;AUC值越大的分类器,正确率越高。
为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:
当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。
在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
ROC与AUC 的理解和python实现_码猿小菜鸡的博客-CSDN博客_python roc 实现
python绘制ROC曲线,计算AUC_卅拓的博客-CSDN博客_python roc
ROC曲线的阈值确定与平衡点确定_wqjsmile的博客-CSDN博客_roc曲线阈值
机器学习之分类性能度量指标 : ROC曲线、AUC值、正确率、召回率 - 知乎
ROC曲线-阈值评价标准_Rachel-Zhang的博客-CSDN博客
机器学习中精准率/召回率/PR曲线/AUC-ROC曲线等概念_大哇唧的博客-CSDN博客

【机器学习】错误拒绝率FRR,错误接受率FAR,等误率EER,准确率ACC 的理解_LCCFlccf的博客-CSDN博客_错误拒绝率
False Rejection Rate, FRR : 若两个样本为同类(同一个人),却被系统误认为异类(非同一个人),则为错误拒绝案例.
False Acceptance Rate, FAR: 若两个样本为异类(非同一个人),却被系统误认为同类(同一个人),则为错误接受案例(即本不该接受的但接受了)
accuracy coverage precision recall f1
accuracy coverage precision recall f1_king52113141314的博客-CSDN博客

机器学习何时使用归一化和标准化
python - How to rescale new data base on old MinMaxScale? - Stack Overflow
Compare the effect of different scalers on data with outliers — scikit-learn 1.1.3 documentation
关于机器学习何时使用归一化和标准化_weixin_62077732的博客-CSDN博客_支持向量机需要归一化吗那么是所有的机器学习算法建模之前都需要对相应的数据进行标准化和归一化处理吗?肯定不是的。其中KNN算法、支持向量机、线性回归、神经网络是需要进行标准化或归一化处理的,不难发现这几种算法都与"距离"相关,所以在进行计算时为了避免预测结果向数值大的特征倾斜,所以标准化处理是必要的,可以很大程度提高模型的精度。
决策树和朴素贝叶斯算法是不需要进行标准化的,因为前者是通过信息增益进行决策,后者是通过概率进行评判,这类模型不关心变量的取值,而是关心变量的分布和变量之间的条件概率,与"距离"计算无关,继而以决策树为基础构建的随机森林、AdaBoost等等也不需要标准化,但是需要注意的是,在应用这些算法之前若要使用PCA降维则需要进行标准化。
哪些模型对标准化处理比较敏感
-
基于距离度量的模型:由于距离对特征之间不同取值范围非常敏感,若某个特征取值非常大而导致其掩盖了特征之间的距离对总距离的影响,这样距离模型便不能很好地将不同类别的特征区分开。所以基于距离读量的模型是十分有必要做数据标准化处理的,此类模型在归一化后可有可能提高精度。 最典型基于距离度量的模型包括KNN、kmeans聚类、感知机和SVM。
-
判别模型:有些模型在各个维度进行不均匀伸缩后,最优解与原来不等价,例如SVM。对于这样的模型,除非本来各维数据的分布范围就比较接近,否则必须进行标准化,以免模型参数被分布范围较大或较小的数据占住主导地位。 有些模型在各个维度进行不均匀伸缩后,最优解与原来等价,例如logistic regression。对于这样的模型,是否标准化理论上不会改变最优解。但是,由于实际求解往往使用迭代算法,如果目标函数的形状太"扁",迭代算法可能收敛得很慢甚至不收敛。所以对于具有伸缩不变性的模型, 最好也进行数据标准化。
-
通过梯度下降求解最优解的模型:归一化后加快了梯度下降求最优解的速度, 运用梯度下降,损失等高线是椭圆形,需要进行多次迭代才能达到最优点,如果进行归一化了,那么等高线就是圆形的,促使往原点迭代,从而导致需要迭代次数较少。因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。如GBDT的树是在上一颗树的基础上通过梯度下降求解最优解,归一化能收敛的更快,而随机森林本来就是通过减少方差提高性能的,树之间建立关系是独立的,不需要归一化
-
概率模型不需要归一化:树模型是通过寻找最优分裂点构成的,样本点的数值缩放不影响分裂点的位置,对树模型的结构也不造成影响,而且树模型不能进行梯度下降,因为树模型是阶跃的,阶跃是不可导的,因此不需要归一化。决策树、基于决策树的Boosting和Bagging等集成学习模型对于特征取值大小并不敏感。因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率。
归一化和标准化选择
-
若对输出结果范围有要求 ---- 用归一化
-
数据较为稳定,不存在极端的最大最小 ---- 用归一化
-
如果数据存在异常值和较多噪音 ---- 用标准化,可以间接通过中心化避免异常值和极端值的影响
归一化和标准化原因
-
消除量纲或数值对计算结果的影响
-
模型要求数据假定服从相应的分布
-
将数据缩放到指定的区间上
multiple inputs and mixed data with Keras
Keras: Multiple Inputs and Mixed Data - PyImageSearch
Regression with Keras - PyImageSearch
Keras, Regression, and CNNs - PyImageSearch
Matching the number of nodes of those two branches is not a requirement but it does help balance the branches.
What is mixed data?
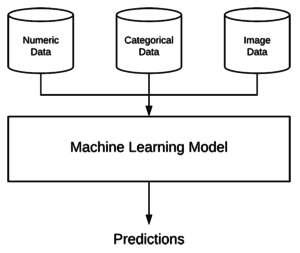
Figure 1: With the Keras’ flexible deep learning framework, it is possible define a multi-input model that includes both CNN and MLP branches to handle mixed data.
In machine learning, mixed data refers to the concept of having multiple types of independent data.
For example, let’s suppose we are machine learning engineers working at a hospital to develop a system capable of classifying the health of a patient.
We would have multiple types of input data for a given patient, including:
- Numeric/continuous values, such as age, heart rate, blood pressure
- Categorical values, including gender and ethnicity
- Image data, such as any MRI, X-ray, etc.
All of these values constitute different data types; however, our machine learning model must be able to ingest this “mixed data” and make (accurate) predictions on it.
You will see the term “mixed data” in machine learning literature when working with multiple data modalities.
Developing machine learning systems capable of handling mixed data can be extremely challenging as each data type may require separate preprocessing steps, including scaling, normalization, and feature engineering.
Working with mixed data is still very much an open area of research and is often heavily dependent on the specific task/end goal.
加载自定义loss的神经网络model
model = tf.keras.models.load_model(model_path, custom_objects={'_triplet_loss': triplet_loss}, compile=True)load_model 报错: Exception encountered when calling layer "" (type Lambda)
Keras model cannot be loaded if it contains a Lambda layer:
NameError: Exception encountered when calling layer "Embedding" (type Lambda).
name 'K' is not defined
Call arguments received by layer "Embedding" (type Lambda):
• inputs=tf.Tensor(shape=(None, 128), dtype=float32)
• mask=None
• training=False
## 使用 'K':K
model = tf.keras.models.load_model(model_path,custom_objects={'_triplet_loss': self.triplet_loss,'K':K}, compile=False)















 6911
6911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









