







一、问题出现场景
产品使用的一家可燃气检测传感器,会传递给我一个已经是浮点数的四字节数据,但是我在编写程序时使用实际的浮点数数据
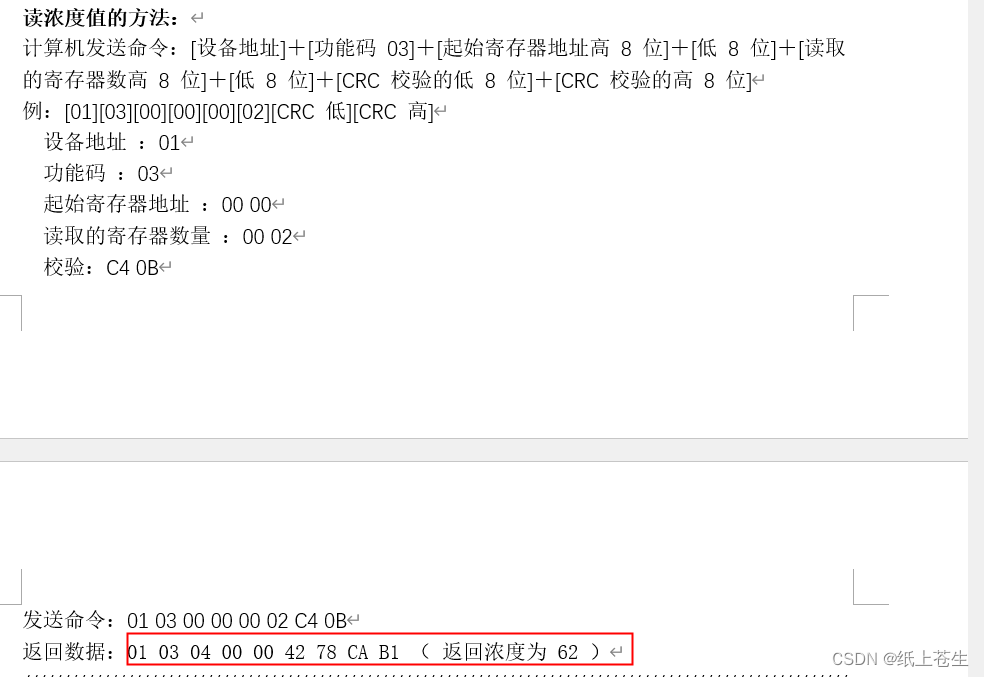
注:浓度值数据类型为浮点型,占4个字节;通讯时 先低(16位)后高(16位),高字节在前,低字节在后。(比如浮点数23.56,在内存中为41 BC 7A E1,通讯时传输顺序:7A E1 41 BC。)
二、进行四字节的浮点数转换
直接上代码:【直接可以得到浮点数】
#include <iostream>
float convertBytesToFloat(unsigned char* com_r) {
float sum0 = 0.0;
unsigned char* p0 = (unsigned char*)&sum0;
*p0 = com_r[1];
*(p0 + 1) = com_r[0];
*(p0 + 2) = com_r[3];
*(p0 + 3) = com_r[2];
return sum0;
}
int main() {
unsigned char com_r[10];
com_r[0] = 0x00;
com_r[1] = 0x00;
com_r[2] = 0x42;
com_r[3] = 0x78;
float result = convertBytesToFloat(com_r);
std::cout << "Result: " << result << std::endl;
return 0;
}三、将浮点数换成四字节数据
直接行代码:【注意数据传递顺序进行调整】
#include <iostream>
#include <cstdint>
int main() {
float value = 6.0;
uint32_t* floatPtr = reinterpret_cast<uint32_t*>(&value);
uint32_t floatValue = *floatPtr;
uint8_t bytes[4];
for (int i = 0; i < 4; i++) {
bytes[i] = (floatValue >> (8 * i)) & 0xFF;
}
std::cout << "Byte 1: " << std::hex << static_cast<int>(bytes[0]) << std::endl;
std::cout << "Byte 2: " << std::hex << static_cast<int>(bytes[1]) << std::endl;
std::cout << "Byte 3: " << std::hex << static_cast<int>(bytes[2]) << std::endl;
std::cout << "Byte 4: " << std::hex << static_cast<int>(bytes[3]) << std::endl;
return 0;
}关于浮点数的知识,大佬已经讲的很清楚,大家可以参考
IEEE754标准: 一 , 浮点数在内存中的存储方式 - 知乎 (zhihu.com) https://zhuanlan.zhihu.com/p/343033661摘要:
https://zhuanlan.zhihu.com/p/343033661摘要:
当时让AI帮我写的程序:
四、32位单精度浮点数在内存中的存储方式
上文说到: IEEE754标准提供了如何在计算机内存中, 以二进制的方式存储十进制浮点数的具体标准, 并制定了四种精度规范.
这里我们主要研究 32位浮点数 (或者说单精度浮点数, 或者说float类型) 在计算机中是怎么存储的. 其他精度, 比如64位浮点数, 则大同小异.
想要存储一个32位浮点数, 比如20.5, 在内存或硬盘中要占用32个二进制位 (或者说32个小格子, 32个比特位)
这32个二进制位被划分为3部分, 用途各不相同:

32位浮点数内存占用示意图, 共使用了32个小格子
这32个二进制位的内存编号从高到低 (从31到0), 共包含如下几个部分:
sign: 符号位, 即图中蓝色的方块
biased exponent: 偏移后的指数位, 即图中绿色的方块
fraction: 尾数位, 即图中红色的方块
下面会依次介绍这三个部分的概念, 用途.
1. 符号位: sign
以32位单精度浮点数为例, 以下不再赘述:
符号位: 占据最高位(第31位)这一位, 用于表示这个浮点数是正数还是负数, 为0表示正数, 为1表示负数.
举例: 对于十进制数20.5, 存储在内存中时, 符号位应为0, 因为这是个正数
2. 偏移后的指数位: biased exponent
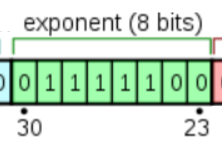
指数位占据第30位到第23位这8位. 也就是上图的绿色部分.
用于表示以2位底的指数. 至于这个指数的作用, 后文会详细讲解, 这里只需要知道: 8位二进制可以表示256种状态, IEEE754规定, 指数位用于表示[-127, 128]范围内的指数.
不过为了表示起来更方便, 浮点型的指数位都有一个固定的偏移量(bias), 用于使 指数 + 这个偏移量 = 一个非负整数. 这样指数位部分就不用为如何表示负数而担心了.
规定: 在32位单精度类型中, 这个偏移量是127. 在64位双精度类型中, 偏移量是1023. 所以, 这里的偏移量是127
⭐ 即, 如果你运算后得到的指数是 -127, 那么偏移后, 在指数位中就需要表示为: -127 + 127(偏移量) = 0
如果你运算后得到的指数是 -10, 那么偏移后, 在指数位中需要表示为: -10 + 127(偏移量) = 117
看, 有了偏移量, 指数位中始终都是一个非负整数.
看到这里, 可能会觉得还不是很清楚指数的作用到的是什么. 没关系, 让我们先继续往下看吧...
3. 尾数位:fraction
![]()
尾数位: 占据剩余的22位到0位这23位. 用于存储尾数.
五、转换举例
在以二进制格式存储十进制浮点数时, 首先需要把十进制浮点数表示为二进制格式, 还拿十进制数20.5举例:
十进制浮点数20.5 = 二进制10100.1
然后, 需要把这个二进制数转换为以2为底的指数形式:
二进制10100.1 = 1.01001 * 2^4
注意转换时, 对于乘号左边, 加粗的那个二进制数1.01001, 需要把小数点放在左起第一位和第二位之间. 且第一位需要是个非0数. 这样表示好之后, 其中的1.01001就是尾数.
用 二进制数 表示 十进制浮点数 时, 表示为 尾数*指数的形式, 并把尾数的小数点放在第一位和第二位之间, 然后保证第一位数非0, 这个处理过程叫做 规范化(normalized)
我们再来看看规范化之后的这个数: 1.01001 * 2^4
其中1.01001是尾数, 而4就是偏移前的指数(unbiased exponent), 上文讲过, 32位单精度浮点数的偏移量(bias)为127, 所以这里加上偏移量之后, 得到的偏移后指数(biased exponent)就是 4 + 127 = 131, 131转换为二进制就是1000 0011
现在还需要对尾数做一些特殊处理
1. 隐藏高位1
你会发现, 尾数部分的最高位始终为1. 比如这里的 1.01001, 这是因为前面说过, 规范化之后, 尾数中的小数点会位于左起第一位和第二位之间. 且第一位是个非0数. 而二进制中, 每一位可取值只有0或1, 如果第一位非0, 则第一位只能为1. 所以在存储尾数时, 可以省略前面的 1和小数点. 只记录尾数中小数点之后的部分, 这样就节约了一位内存. 所以这里只需记录剩余的尾数部分: 01001
所以, 以后再提到尾数, 如无特殊说明, 指的其实是隐藏了整数部分1. 之后, 剩下的小数部分
2. 低位补0
有时候尾数会不够填满尾数位(即图中的红色格子). 比如这里的, 尾数01001不够23位
此时, 需要在低位补零, 补齐23位.
之所以在低位补0, 是因为尾数中存储的本质上是二进制的小数部分, 所以如果想要在不影响原数值的情况下, 填满23位, 就需要在低位补零.
比如, 要把二进制数1.01在不改变原值的情况下填满八位内存, 写出来就应该是: 1.010 0000, 即需要在低位补0
同理, 本例中因为尾数部分存储的实际上是省略了整数部分 1. 之后, 剩余的小数部分, 所以这里补0时也需要在低位补0:
原尾数是: 01001(不到23位)

















 1701
1701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









