







导读
需求
一说爬虫,很多人都会向导python,不过,真正省心的方案,应当是通过js控制获取数据,实现爬虫功能,它避免了很多反爬检查。
最不济,通过js模拟鼠标键盘操作,然后检查页面内容,进行数据爬取。
开发环境
| 版本号 | 描述 | |
|---|---|---|
| 文章日期 | 2022-11-25 | |
| 操作系统 | Win11-22H2 | 内部版本号22621.674 |
fetch介绍
fetch被称为下一代Ajax技术,采用Promise方式来处理数据。
- 是一种简洁明了的API,比XMLHttpRequest更加简单易用。
为什么选择fetch
- 相对于axios、jquery等第三方库,fetch是chrome自带的函数,不用导入。
- fetch为Promise操作,代码更简单和清晰。
- 通过
devtools的Network标签页,可以快速生成fetch代码,再也不用手动配置各种header、url参数了。
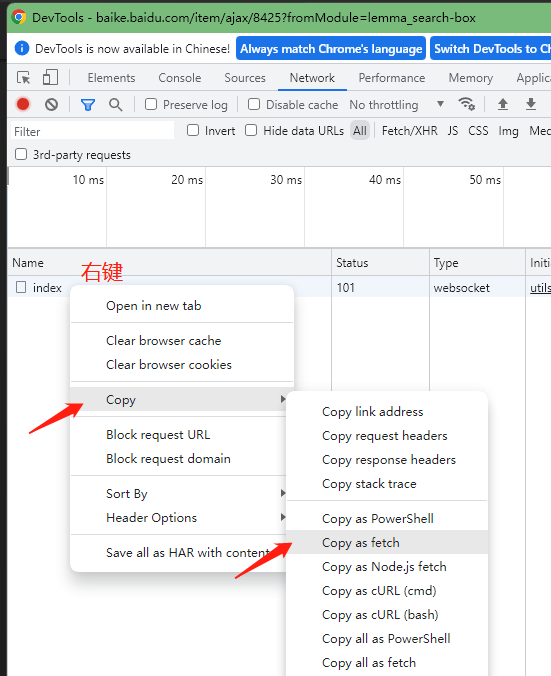
fetch的封装使用
以百度百科的某json请求为例
function dealOne(index, gameLibraryId) {
fetch("https://baike.baidu.com/api/usercenter/checkfavorites?lemmaId=8425", {
"headers": {
"accept": "application/json, text/javascript, */*; q=0.01",
"accept-language": "zh,zh-CN;q=0.9,ja;q=0.8,ko;q=0.7,en;q=0.6,zh-TW;q=0.5",
"sec-ch-ua": "\"Google Chrome\";v=\"105\", \"Not)A;Brand\";v=\"8\", \"Chromium\";v=\"105\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"x-requested-with": "XMLHttpRequest"
},
"referrer": "https://baike.baidu.com/item/ajax/8425?fromModule=lemma_search-box",
"referrerPolicy": "unsafe-url",
"body": null,
"method": "GET",
"mode": "cors",
"credentials": "include"
}).then(function(response) { // 获取文本
return response.text();
}).then(function(text) { // 转为对象
// 部分请求不返回数据
if (text.length == 0) {
return {}
}
return JSON.parse(text);
}).then(v=> { // 数据保存...
// 数据保存...
console.log(v)
});
}
数据存储
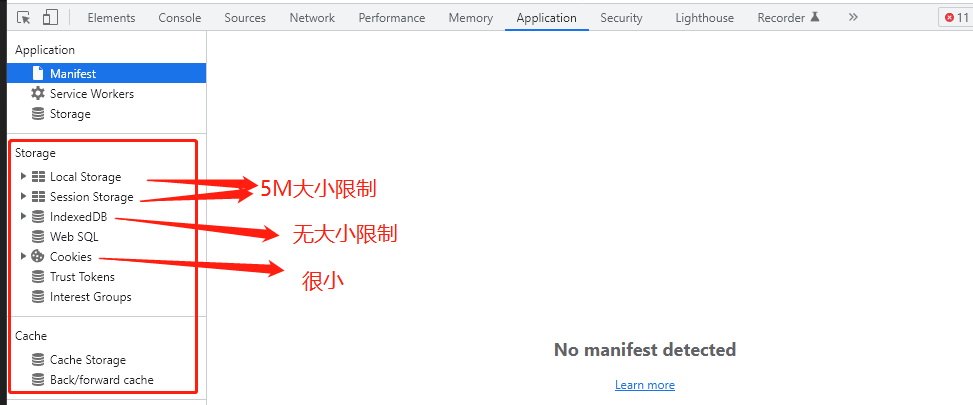
chrome浏览器提供了丰富的存储方案,各种存储如下:
indexedDB操作复杂,暂时不考虑。
Cookies保存数据太小,而且会被上传到服务器,不适合存储数据。
Local和Session Storage我们随便选一个就行,这里我们选择Session Storage。
数据访问封装
一般,我们爬取的数据以数组形式保存起来,所以,封装如下函数:
function saveItem(key_name, data) {
// 获取当前缓存中的数据,当数据为空,返回`[]`。
// 注意:获取的数据是字符串
var old = sessionStorage[key_name] || `[]`;
// 将数据转换为对象j(json数组)
var j = JSON.parse(old);
// 当data为数组时,concat拼接数组
// 拼接后的数组赋值给j
if (Array.isArray(j)) {
j = j.concat(data)
}
// 当data为对象时,需要使用push将数据添加到数组中,返回值为添加数据的索引
else {
j.push(data)
}
sessionStorage[key_name] = JSON.stringify(j)
}
多页面处理方案
一般,我们都需要处理如下多个页面的数据请求,从1到283,为了防止被服务器认为是恶意请求,我们需要做延迟操作。
这样的方案有很多,如Promise完成后再执行下一个任务。
不过为了代码简便,这里采用定时器setTimeout,一次性设置完所有任务,第一个请求是0s,第二个请求是5s,第三个请求是10s,依次增加。

function deal(key_name) {
for (let index = 1; index <= 283; index++) {
setTimeout(()=>{
dealOne(index, key_name)
}, (index-1) * 5000)
}
}
数据过大,拆分处理
当缓存大于5M,sessionStorage就会写入失败,这时候就需要将请求拆分。
下面以100为单位执行任务
function deal100(min, max, key_name) {
for (let index = min; index <= max; index++) {
setTimeout(()=>{
dealOne(index, key_name)
}, (index-min) * 5000)
}
}
// deal100(1, 100, 'games_100')
deal100(201, 283, 'games_300')
参考资料
**ps:**文章中内容仅用于技术交流,请勿用于违规违法行为。
















 857
857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











