







任务描述
在Kettle中,读者可通过获得系统信息组件获得系统环境变量,也可以通过设置变量,定义虚拟机和任务中的变量。在项目中,经常利用生产环境或外围系统交互的FTP文件接口,获取固定格式的数据文件。
某生产系统每天定时推送名称格式包含yyyyMMdd的数据文件,为了获得日期变量并每天读取由生产系统推送的前两天的数据文件,需要使用设置变量组件,设置名称为fileDate的变量,该变量值需要符合yyyyMMdd格式,取值为当前系统日期的前两天。
任务分析
(1) 建立【设置变量】转换工程。
(2) 设置【设置变量】参数。
(3) 预览结果数据。
建立设置变量转换工程
某生产系统定时每天推送前两天的、名称格式为yyyyMMdd(y指的是年,M指的是月,d指的是日,例如20200320)数据文件,例如20200320.csv。自定义fileDate变量,取值符合yyyyMMdd格式,随着日期改变,取值为当前日期的前两天,例如,今天为2020年3月24日,则fileDate取值为“20200322”。
建立设置变量转换工程步骤如下。
(1) 创建设置变量转换工程。使用Ctrl+N快捷键,创建【设置变量】转换工程。
(2) 创建获取系统信息组件,定义变量。创建【获取系统信息】组件,设置参数,【字段】设置为“fileDate”,【类型】设置为“今天00:00:00”。
建立设置变量转换工程
(3) 创建JavaScript代码组件,定义变量格式。创建【JavaScript代码】组件,如图所示

双击【JavaScript代码】组件,编写JavaScript脚本,定义dtNew变量格式为yyyyMMdd,取值为当前日期的前两天,并将dtNew变量名称改名为fileDate。编写代码和设置完成时,【JavaScript代码】参数设置如图所示。

//Script here
Date.prototype.Format = function (fmt) { //author: meizz
var o = {
"M+": this.getMonth() + 1, //月份
"d+": this.getDate(), //日
"h+": this.getHours(), //小时
"m+": this.getMinutes(), //分
"s+": this.getSeconds(), //秒
"q+": Math.floor((this.getMonth() + 3) / 3), //季度
"S": this.getMilliseconds() //毫秒
};
if (/(y+)/.test(fmt)) fmt = fmt.replace(RegExp.$1, (this.getFullYear() + "").substr(4 - RegExp.$1.length));
for (var k in o)
if (new RegExp("(" + k + ")").test(fmt)) fmt = fmt.replace(RegExp.$1, (RegExp.$1.length == 1) ? (o[k]) : (("00" + o[k]).substr(("" + o[k]).length)));
return fmt;
}
var dtNew=new Date(new Date().getTime()-2*24*60*60*1000).Format("yyyyMMdd");
//当天减去2天时间ms数,得到前天的时间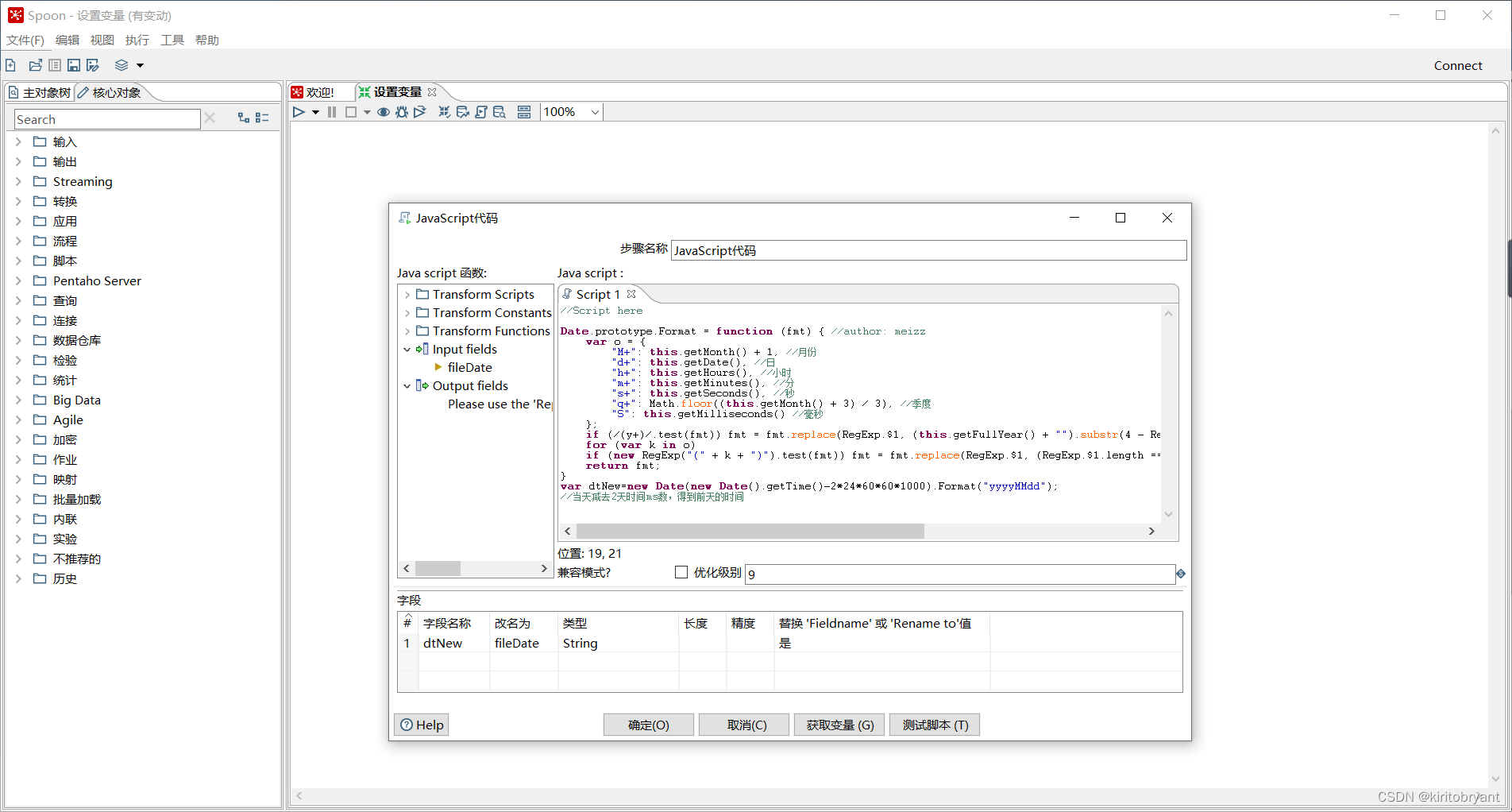
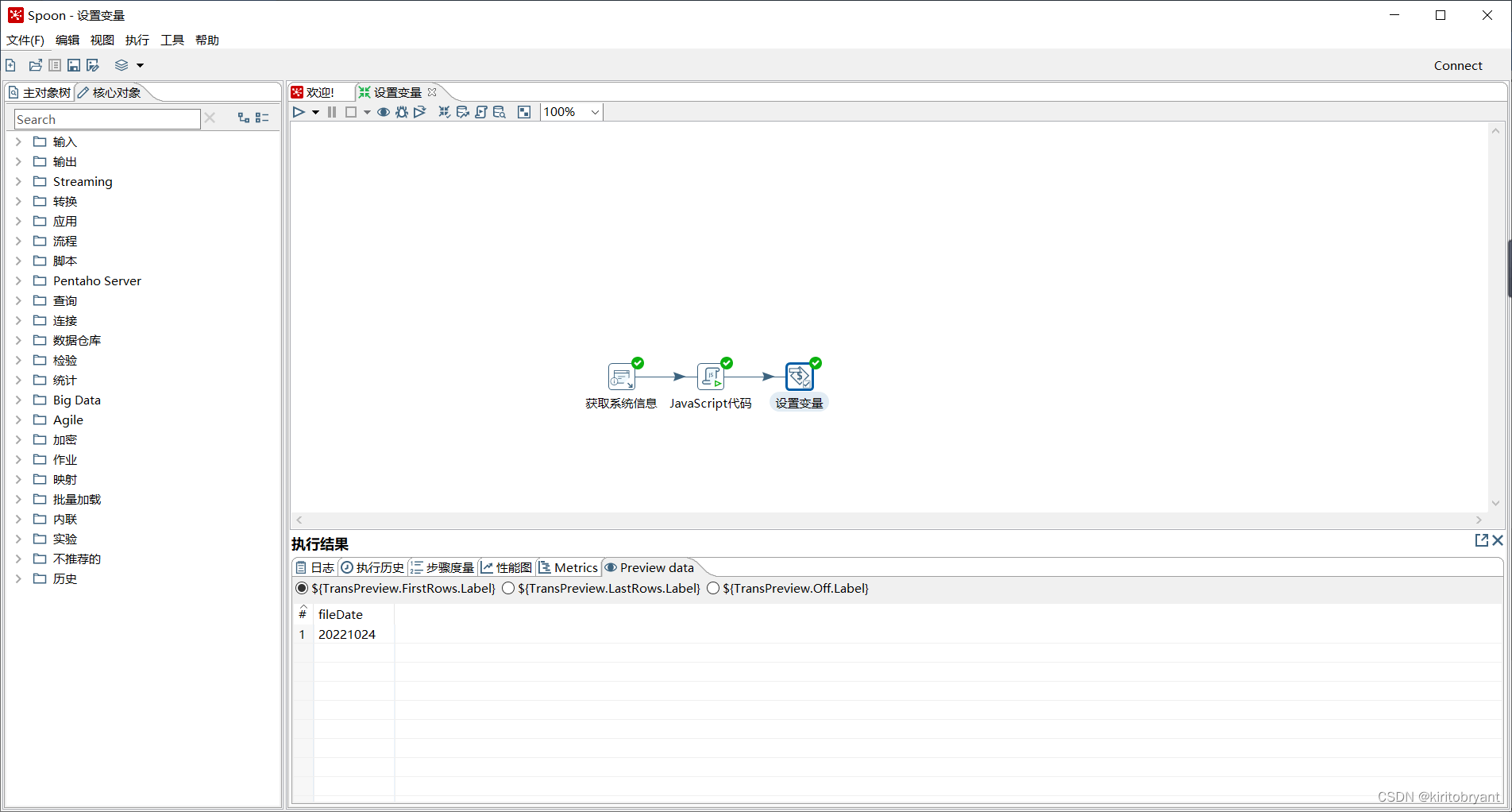
双击【设置变量】组件,弹出【设置环境变量】对话框,如图所示。

最后的运行情况如下:
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











