







1. 通配符
1.1 通配符简介
通配符是一种特殊语句,主要有星号(*)、问号(?)等表示,用来模糊搜索文件,当查找目录或文件时,可以使用通配符来代替一个或多个真正字符。
作用范围:目录和文件名。
常见通配符:常用通配符包括 *、? 、[ ]、 [^ ] 、[! ]和{},具体含义见下表。
| 字符 | 含义 |
| * | 匹符配任意字 |
| ? | 匹配单个字符 |
| [] | 匹配方括号中的任意一个,不能用于创建目录和文件 |
| [^] | 匹配方括号中的任意一个字符或数字后进行取反,等同于[! ],表示范围可以".."或"—”,用于查找和删除目录和文件,不用于创建目录和文件 |
| [!] | 匹配方括号中的任意一个字符或数字后进行取反, 等同于[^ ],表示范围可以".."或"—", 用于查找和删除目录和文件,不用于创建目录和文件 |
| [?-?] | 匹配方括号范围内任意一个,用于查询、删除,但不能用于创建目录和文件 |
| {string,string} | 匹配括号中的任意一个字符串,表示一个范围时,字符串之间个".." |
1.2 通配符示例
[root@linuxforliuhj test]# ll
total 0
-rw-r--r--. 1 root root 0 Nov 3 00:09 alis.txt
-rw-r--r--. 1 root root 0 Nov 3 00:10 Alis.txt
-rw-r--r--. 1 root root 0 Nov 3 00:10 bouch.sh
-rw-r--r--. 1 root root 0 Nov 3 00:10 Bouch.sh
-rw-r--r--. 1 root root 0 Nov 3 00:10 count.jpg
-rw-r--r--. 1 root root 0 Nov 3 00:10 Count.jpg
-rw-r--r--. 1 root root 0 Nov 3 00:10 zero
-rw-r--r--. 1 root root 0 Nov 3 00:10 Zero
[root@linuxforliuhj test]#- 匹配任意长度字符
[root@linuxforliuhj test]# ll *.sh
-rw-r--r--. 1 root root 0 Nov 3 00:10 bouch.sh
-rw-r--r--. 1 root root 0 Nov 3 00:10 Bouch.sh
[root@linuxforliuhj test]# ll *ou*
-rw-r--r--. 1 root root 0 Nov 3 00:10 bouch.sh
-rw-r--r--. 1 root root 0 Nov 3 00:10 Bouch.sh
-rw-r--r--. 1 root root 0 Nov 3 00:10 count.jpg
-rw-r--r--. 1 root root 0 Nov 3 00:10 Count.jpg
[root@linuxforliuhj test]#
- 匹配任意一个字符
[root@linuxforliuhj test]# ll ?e*
-rw-r--r--. 1 root root 0 Nov 3 00:10 zero
-rw-r--r--. 1 root root 0 Nov 3 00:10 Zero
[root@linuxforliuhj test]# ll ?ou*
-rw-r--r--. 1 root root 0 Nov 3 00:10 bouch.sh
-rw-r--r--. 1 root root 0 Nov 3 00:10 Bouch.sh
-rw-r--r--. 1 root root 0 Nov 3 00:10 count.jpg
-rw-r--r--. 1 root root 0 Nov 3 00:10 Count.jpg
- 匹配中括号中任意一个字符
[root@linuxforliuhj test]# ll [abz]*
-rw-r--r--. 1 root root 0 Nov 3 00:09 alis.txt
-rw-r--r--. 1 root root 0 Nov 3 00:10 bouch.sh
-rw-r--r--. 1 root root 0 Nov 3 00:10 zero
[root@linuxforliuhj test]# - 匹配中括号范围内的任意一个字符
[root@linuxforliuhj test]# export LC_ALL=C
[root@linuxforliuhj test]# ll [a-z]*
-rw-r--r--. 1 root root 0 Nov 3 00:09 alis.txt
-rw-r--r--. 1 root root 0 Nov 3 00:10 bouch.sh
-rw-r--r--. 1 root root 0 Nov 3 00:10 count.jpg
-rw-r--r--. 1 root root 0 Nov 3 00:10 zero
[root@linuxforliuhj test]#- 不匹配括号中的任意一个字符
[root@linuxforliuhj test]# ll [!abz]*
-rw-r--r--. 1 root root 0 Nov 3 00:10 Alis.txt
-rw-r--r--. 1 root root 0 Nov 3 00:10 Bouch.sh
-rw-r--r--. 1 root root 0 Nov 3 00:10 Count.jpg
-rw-r--r--. 1 root root 0 Nov 3 00:10 Zero
-rw-r--r--. 1 root root 0 Nov 3 00:10 count.jpg
[root@linuxforliuhj test]# -
不匹配中括号范围内的任意一个字符
[root@linuxforliuhj test]# ll [!a-z]*
-rw-r--r--. 1 root root 0 Nov 3 00:10 Alis.txt
-rw-r--r--. 1 root root 0 Nov 3 00:10 Bouch.sh
-rw-r--r--. 1 root root 0 Nov 3 00:10 Count.jpg
-rw-r--r--. 1 root root 0 Nov 3 00:10 Zero
[root@linuxforliuhj test]#2. grep命令
2.1 grep简介
grep(global search regular expression(RE) and print out the line),全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
Unix的grep家族包括grep、egrep和fgrep。egrep和fgrep的命令只跟grep有很小不同。egrep是grep的扩展,支持更多的re元字符, fgrep就是fixed grep或fast grep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊。linux使用GNU版本的grep,它功能更强,可以通过-G、-E、-F命令行选项来使用egrep和fgrep的功能。
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到屏幕,不影响原文件内容。
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
2.2 grep元字符集
| ^ | 锚定行首 如:'^grep'匹配所有以grep开头的行 |
| $ | 锚定行尾 如:'grep$'匹配所有以grep结尾的行 |
| . | 匹配一个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p |
| * | 匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行。 .*一起用代表任意字符 |
| [] | 匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep |
| [^] | 匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行 |
| .. | 标记匹配字符,如'love',love被标记为1 |
| \< | 锚定单词的开始,如:'\<grep'匹配包含以grep开头的单词的行 |
| \> | 锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的行 |
| x\{m\} | 重复字符x,m次,如:'o\{5\}'匹配包含5个o的行 |
| x\{m,\} | 重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行 |
| x\{m,n\} | 重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5-10个o的行 |
| \w | 匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个文字或数字字符,然后是p |
| \W | \w的反置形式,匹配一个或多个非单词字符,如点号句号等 |
| \b | 单词锁定符,如: '\bgrepb\'只匹配grep。 |
2.3 grep扩展字符集
用于egrep和 grep -E的元字符扩展集
| + | 匹配一个或多个先前的字符。如:'[a-z]+able',匹配一个或多个小写字母后跟able的串,如loveable,enable,disable等。 |
| ? | 匹配零个或多个先前的字符。如:'gr?p'匹配gr后跟一个或没有字符,然后是p的行。 |
| a|b|c | 匹配a或b或c。如:grep|sed匹配grep或sed |
| () | 分组符号,如:love(able|rs)ov+匹配loveable或lovers,匹配一个或多个ov。 |
| x{m},x{m,},x{m,n} | 作用同x\{m\},x\{m,\},x\{m,n\} |
2.4 grep命令选项
| --help | 在线帮助。 | |
| -a | --text | 不要忽略二进制的数据。 |
| -An | --after-context=n | 除了显示符合范本样式的那一列之外,并显示该列之后的内容。 |
| -Bn | --before-context=n | 除了显示符合范本样式的那一列之外,并显示该列之前的内容。 |
| -Cn | --context=n | 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。 |
| -b | --byte-offset | 在显示符合范本样式的那一列之前,标示出该列第一个字符的位编号。 |
| -c | --count | 计算符合范本样式的列数。 |
| -d | --directories | 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。 |
| -e | --regexp | 指定字符串做为查找文件内容的范本样式。 |
| -E | --extended-regexp | 将范本样式为延伸的普通表示法来使用。 |
| -f | --file | 指定范本文件,其内容含有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每列一个范本样式。 |
| -F | --fixed-regexp | 将范本样式视为固定字符串的列表。 |
| -G | --basic-regexp | 将范本样式视为普通的表示法来使用。 |
| -h | --no-filename | 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。 |
| -H | --with-filename | 在显示符合范本样式的那一列之前,表示该列所属的文件名称。 |
| -i | --ignore-case | 忽略字符大小写的差别。 |
| -l | --file-with-matches | 列出文件内容符合指定的范本样式的文件名称。 |
| -L | --files-without-match | 列出文件内容不符合指定的范本样式的文件名称。 |
| -n | --line-number | 在显示符合范本样式的那一列之前,标示出该列的列数编号。 |
| -q | --quiet或--silent | 不显示任何信息。 |
| -r | --recursive | 此参数的效果和指定“-d recurse”参数相同。 |
| -s | --no-messages | 不显示错误信息。 |
| -v | --revert-match | 反转查找。 |
| -V | --version | 显示版本信息。 |
| -w | --word-regexp | 只显示全字符合的列。 |
| -x | --line-regexp | 只显示全列符合的列。 |
| -y | 此参数的效果和指定“-i”参数相同。 |
#贪婪匹配
grep root passwd
#以root开头
grep ^root passwd
#以bash结尾
grep bash$ passwd
#忽略大小写
grep -i root passwd
#后面条件可以是一个正则表达式
grep -E "root|ROOT" passwd
#默认显示mail所在行
cat -b passwd | grep mail
#查看mail及上下两行
cat -b passwd | grep mail -2
#查看mail及下两行
cat -b passwd | grep mail -A2
#查看mail及上两行
cat -b passwd | grep mail -B2
#查看mail及上下两行
cat -b passwd | grep mail -C2
#在当前目录中,查找后缀有file字样的文件中包含test字符串的文件,并打印出该字符串的行
grep test *file
#以递归的方式查找符合条件的文件。例如,查找指定目录/etc/acpi 及其子目录(如果存在子目录的话)下所有文件中包含字符串"update"的文件,并打印出该字符串所在行的内容:
grep -r update /etc/acpi
#反向查找。前面各个例子是查找并打印出符合条件的行,通过"-v"参数可以打印出不符合条件行的内容
grep -v test *test*
#在某个文件夹下递归搜索含有特定字符的文件
grep -rl "^demo$" ./
3. sed命令
3.1 sed简介
sed是Stream Editor(流编辑器)的缩写,简称流编辑器,用来处理文件的。sed是一行一行读取文件内容并按照要求进行处理,把处理后的结果输出到屏幕。
何为流编辑器?就是把文本中的文字按照特定的分隔方式,进行数据流处理。sed就是基于这种方式,它是以换行符以分隔单位,对文本进行逐行的处理。处理时,把当前处理的行存储在临时缓冲区中,称为『模式空间』(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。sed主要用来自动编辑一个或多个文件,简化对文件的反复操作,编写转换程序等。
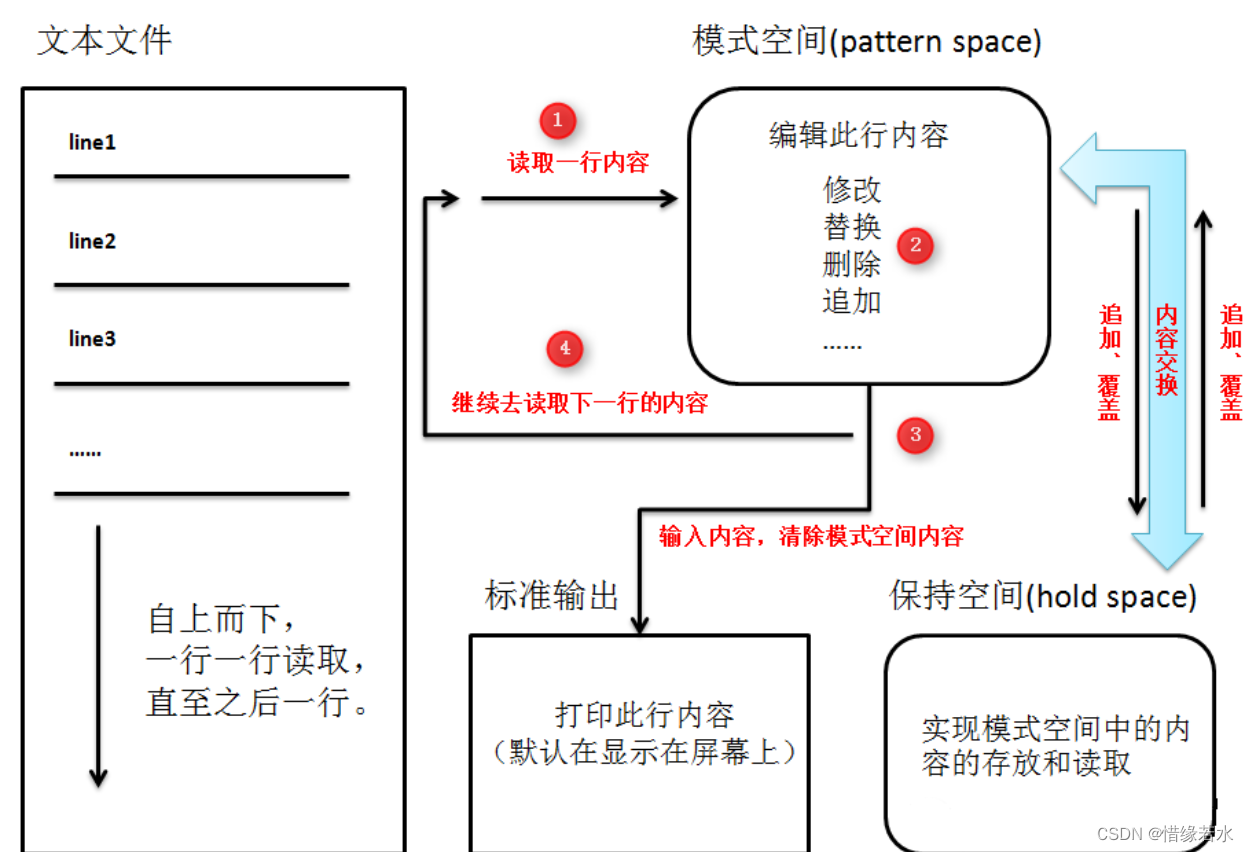
前提:首先对于一个文本文件来说,它是由至上而下的一行或N行组成。
- 当用sed命令对文本进行处理的时候,sed先读取对象的文本文件的第一行到模式空间中。
- 当有内容进入“模式空间”时,sed的编辑命令对模式空间中的内容进行编辑操作(修改,替换,删除,追加,显示等等)
- 模式空间中的内容编辑处理完成之后,sed把此内容通过标准输出(默认为显示器)打印出来,并删除模式空间中的内容。
- 第一行处理结束。从新读取第二行的内容进行处理,直到最后一行。
3.2 sed命令选项
| -e | --expression | 以选项中指定的script来处理输入的文本文件 |
| -f | --file | 以选项中指定的script文件来处理输入的文本文件 |
| --help | 显示帮助 | |
| -n | --quiet | 取消自动打印模式空间 |
| --version | 显示版本信息 | |
| -i | --inplace | 直接修改读取的文件内容,而不是输出到终端 |
3.3 sed命令动作
| i | 插入 | 行前插入文本 |
| a | 新增 | 行后插入文本 |
| c | 取代 | 替换当前行 |
| d | 删除 | 删除所选行 |
| p | 打印 | 亦即将某个选择的数据印出。通常p会与参数sed-n一起运行 |
| s | 取代 | 可以直接进行取代的工作哩!通常这个s的动作可以搭配正则表达式!例如s/old/new/g |
# 删除1/2行(源文件保持不变)
sed '1,2d' test.txt
# 删除1/2行
sed -i '1,2d' test.txt
#使用正则表达式选出符合条件的行
sed '/2/d' test.txt
#第四行后添加一行,并将结果输出到标准输出
sed -e 4a\newLine testfile
#新增行
sed '1a hello world' test.txt
#替换整行
sed '1c hello world' test.txt
#替换行内部分内容
sed 's/aa/AA/' test.txt
sed 's#aa#AA#' test.txt
sed 's@aa@AA@' test.txt
#限定在1行替换
sed '1s/aa/AA/g' test.txt
#限定在5行及以后替换
sed '5,$s/aa/AA/g' test.txt
#设定正则表达式
sed '/^[0-9]/s/aa/AA/g' test.txt
#搜索并输出行内容
sed '2p' test.txt在sed中正则表达式是写在 /.../ 两个斜杠中间的,这个正则的意思是寻找所有包含2的行
sed正则中的元字符

















 1043
1043











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











