







- 机器学习的基础架构
银行在决定是否要通过贷款申请人的授信请求前,会根据申请人的资料对其进行风险评估,(通常银行会为其计算信用评分),申请人状况符合银行要求时,银行通过其申请,反之则婉拒。那么银行凭借什么来判断申请人将来是否会违约呢?通过银行之前的信用贷款记录,这些记录中,有些客户发生了违约行为,其他则表现良好,银行从这些违约与非违约的记录中learning到了一些规律,然后利用这些规律,来对新申请人的违约风险进行估计。因此信用评估模型就是一个learning的问题,那么我们该如何使用历史数据做好learning呢?
下面这张图描述了learning的基础架构:
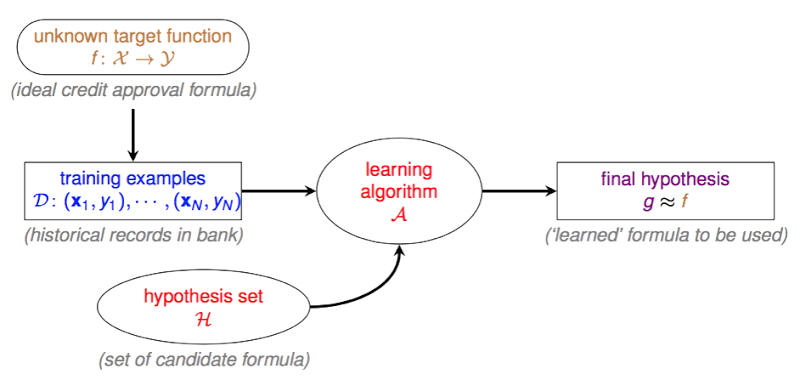
- f:X→Y ,其中表示输入空间,譬如下图中第一列
(age, gender, annual salary, year in residence, year in job, current debt)为输入空间(6维),而右边一列
(23 years, female, NTD 1,000,000, 1 year, 0.5 year, 200,000)为该输入空间下的一个向量,每位贷款申请人对应该空间下的一个向量。

Y
表示输出空间,在二元分类中,输出空间是一个1维的取值为+1或-1的空间
{−1,+1}1
,可以用-1表示非违约,+1表示违约。
f
是未知的真理,是事物运转的规律,假如我们可以拥有
f
,我们就可以知道一个人到底会不会发生违约行为。但是这个 ff 是不可知的,我们无法窥探其中运行的原理(函数内部构造),我们唯一知道的是
f
在我们已知的历史数据
D
当中的运行情况(把
Xn
当做
f
输入,把
Yn
当做
f
的输出),learning要作的事情,就是找一个在
D
中运行情与
f
类似的函数,这个函数对于相同的输入,会有与
f
相同的输出,并且希望在
D
之外,也就是我们未知的世界,我们找的这个函数的运行情况还能与
f
接近。















 2219
2219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









