







| 论文名称 | 发表时间 | 发表期刊 | 期刊等级 | 研究单位 |
| EMBERSim: A Large-Scale Databank for Boosting Similarity Search in Malware Analysis | 2023年 | Neural Information Processing Systems | CCF A | CrowdStrike |
1. 引言
大规模相似性检测在恶意软件领域的必要性:恶意软件被用作网络武器来攻击公司和独立用户,造成未经授权的访问、拒绝服务、数据损坏和身份盗窃等严重影响。 从基于签名的恶意软件检测到更复杂的机器学习 (ML) 技术,防病毒 (AV) 成为这场网络战争中必要的防御层。 随着对有助于复制现有恶意软件的开源工具的前所未有的访问,类似恶意样本的数量不断增加。 从每年必须分析更多数据的威胁研究人员以及为恶意软件检测训练机器学习模型的数据科学家的角度来看,这都带来了问题。 在恶意软件检测器的新迭代中包含近乎重复的样本是危险的,因为它可能会对某些类型的攻击产生偏见。 因此,作者可以认为能够大规模执行相似性搜索对于网络安全世界至关重要。 考虑到大量数据,机器学习能够更好地在相似性搜索的背景下寻找模式,而不是依赖启发式或签名直到最近也是如此。
恶意软件相似性的研究内容、研究动机以及研究方法:论文拟解决 Windows 可移植可执行 (PE) 文件中的相似性搜索问题。 论文选择的平台是由全球绝大多数使用 Windows 操作系统的计算机驱动的。 此外,论文处理二进制代码相似性(BCS)的动机是由于缺乏源代码和二进制代码随编译器设置、体系结构或混淆而变化等因素,该问题具有挑战性。 论文发现网络安全中 BCS 领域数据稀缺,并决定通过生成二进制代码相似性基准来解决这个问题。 论文使用 EMBER (用于恶意软件检测的 PE 文件大型数据集)以及自动标记工具和机器学习技术的组合,如下所述。 论文希望能够推动这一领域的未来研究,重点是在训练和评估恶意软件相似性检测器时考虑现实世界的复杂性。
2. 相关工作
二进制代码相似性检测概述:二进制代码相似度(BCS)的核心是两段二进制代码之间的比较。 传统的 BCS 方法采用启发式方法,例如文件散列、图匹配或对齐。 用于相似性搜索的威胁分析师工具集中的一个合理的默认值是 ssdeep ,它是一种模糊哈希形式,将输入中的字节块映射到压缩文本表示,并使用自定义字符串编辑距离作为相似性函数。 或者,通常选择机器学习来解决二进制文件中的相似性,包括浅层模型和深层模型。 尤其是深度学习,在过去几年中已广泛用于 BCS,从更简单的神经网络到 GNN 和 Transformer 。 然而,只有少数 BCS ML 支持的解决方案能够解决网络安全领域。 其中,大多数论文讨论的是函数的相似性,而不是整个程序。
恶意软件相似性检测概述:通过目前的工作,论文拟填补网络安全 BCS 的一些空白,重点关注整个项目。 论文通过选择重新利用基于 XGBoost 的 PE 文件恶意软件分类器的方法来利用基于叶预测(即也称为邻近度)的成对相似性,从而将自己与相关研究区分开来。 Rhodes 等人、克里米尼西等人、卡特勒等人、齐等人的一些不同的著作提出了从基于树的集合中提取成对相似性的可能性。在这种情况下,相似性是通过计算两个给定样本最终位于同一叶节点的次数来确定的,作为预测的一部分。 有趣的是,尽管它在医学和生物学中有效,但我们在 BCS 文献中没有发现上述方法的任何对应关系,特别是在网络安全中的应用。
恶意软件相似性检测研究内容:文献表明 PE 文件中相似性检测的数据匮乏。 过去的大多数工作仅针对良性/恶意类别之一进行验证,测试集中的样本少于 10K 。 因此,我们建议对 EMBER 进行研究,这是一个最初用于 PE 文件中恶意软件检测的大型数据集(1M 样本)。 使用 EMBER 作为支持的其他工作通常侧重于恶意软件检测。 与我们的第二个贡献类似,乔伊斯等人使用 AVClass 将EMBER中的恶意样本标记为相应的恶意软件家族。 然而,这项工作的重点是对恶意软件进行分类,而我们有不同的最终目标(即相似性搜索)和涉及上述标签的工作流程。 据我们所知,我们是第一个为 BCS 发布包含丰富元数据信息的大规模数据集的增强版本的公司。论文直接计算恶意软件样本间的相似性,而不是计算样本函数间的相似性
3. 实验数据
EMBER 是一个大型二进制文件数据集,最初用于恶意软件检测领域的研究。大多数使用 EMBER 作为支持的工作都遵循该数据发布的最初目的继续探索——恶意软件检测和按恶意软件家族分类 。 在目前的工作中,我们利用相似性衍生信息增强了 EMBER。 我们的目标是对网络安全中应用的机器学习驱动的二进制代码相似性搜索主题进行进一步研究。
3.1 EMBER 数据集
论文使用最新版本的 EMBER 数据集,该数据集包含 100 万个样本,其中 80 万个样本已标记,其余 20 万个样本未标记。 带标签的样本进一步分为大小为 600K 的训练子集和大小为 200K 的测试子集,两个子集相对于标签(即良性/恶意)完美平衡。 根据样本出现的时间顺序,很大一部分(95%)的样本是在2018年引入的,数据集主要包括该时期之前的良性样本。 此外,值得注意的是,将数据集划分为训练子集和测试子集遵循时间分割,该时间分割明确界定了两个子集。 总体而言,EMBER 存储库清楚地描述了数据,不包含个人身份信息或攻击性内容,并提供了一种易于应用且易于定制的特征提取方法,用于使用 VirusTotal (VT) 在所有供应商已知的样本上训练和试验新模型所需的特征提取。
3.2 EMBERSim 数据集
具有 AVClass2 标签的 EMBER:为了验证和丰富 EMBER 元数据,论文查询 VirusTotal,并从 90 多个 AV 供应商获取结果,特别是与检测结果(恶意或良性)以及(如果适用)归属检测名称相关的结果。 鉴于检测结果往往会在不同供应商之间波动,并且原始 EMBER 数据中尚未量化这种情况发生的程度,因此为了评估随时间推移潜在的标签变化,此步骤是必要的。 接下来,按照与 EMBER 中概述的过程类似的过程,论文在收集的 VirusTotal 数据上合并运行开源 AVClass 系统。 一个关键的区别是我们使用 AVClass v2 ,它在 EMBER 最初发布期间无法访问。 首先,通过 AVClass v2 中定义明确且全面的分类法,论文的目标是从供应商那里获得标准化的检测名称。 其次,我们利用 AVClass2 中的新功能对生成的标签(给定供应商结果)进行排名,并将它们分类为 FAM(家族)、BEH(行为)、CLASS(类)和 FILE(文件属性)。
- FAM:常见的恶意家族包括,xtrat、zbot、installmonster、ramnit、fareit、sality、wapomi、emotet、vtflooder、ulise 等。
- BEH:常见的行为包括,inject、infostealer、browsermodify、ddos、filecrypt、filemodify、autorun、killproc、hostmodify、jswebinject 等。
- CLASS:常见的恶意软件类别包括,grayware, downloader, virus, backdoor, worm, ransomware, spyware, miner, clicker, infector 等。
- FILE:常见的文件属性包括,os 属性、packed 属性、proglang 属性、installer 属性以及proglang 属性等。
通过 co-occurrence 丰富标签:论文使用经常一起出现的新标签来扩充 EMBER 中的标签列表,如使用 AVClass v2 功能构建的标签 co-occurrence 矩阵所示。
获取标签排名进行评估:论文利用从 AVClass 中提取的丰富标签信息,并使用标签 co-occurrence数据对其进行扩充,为 EMBERSim 生成元数据。 下表显示了标签的存在如何与原始标签相关。
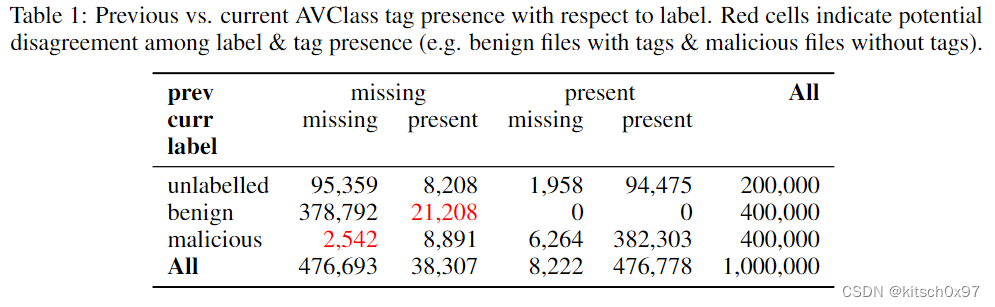
上表强调了当前版本和先前版本的 AVClass 属性标签之间的潜在差异。 鉴于灰色软件/广告软件很难量化为良性或恶意,而且供应商对特定样本可能有不同的看法,因此良性文件在有限的情况下可能会发生这些标签更改(在我们的例子中小于 5%)。 这里可以观察到的另一个限制是 AVClass 不能将无法生成所有样本的标签(大约 1% 的恶意样本) 。
4. 实验方法
4.1 基于 Leaf Prediction 的二进制代码相似性检测
论文通过 Leaf Prediction 的视角来观察相似性。作者认为这是论文的主要贡献之一,据研究文献显示,上述基于叶相似性的方法之前并未在网络安全 BCS 中应用。
本小节中概述的相似性方法基于叶子预测,这意味着论文依赖于训练基于树的分类器。 尽管该方法本身可以应用于任何基于树的集成,但论文具体选择的算法是 XGBoost 集成,因为它在一般行业和学术研究中都有相关性。 鉴于论文选择的数据集和本工作中涉及的领域,上述 XGBoost 模型经过训练以区分恶意和良性 PE 文件。与论文的工作相关的是我们如何使用二元 XGBoost 分类器来量化样本之间的成对相似性。
对于两个样本 s1 和 s2 和经过训练的基于树的模型,论文计算两个用于 Leaf Prediction 的向量 x1 和 x2。当将对应样本传递给模型时,两个向量中的每一个都包含集合中每棵树的终端节点的索引,其中 T 是集合中树的总数。直观上,Leaf Prediction 向量被视为哈希码,其中位置 i 处的每个值对应于输入空间中由 i 划分的特定区域。因此,如果两个样本在树中遵循相似的路径,论文就认为它们是相似的,从而获得相似的叶子预测。在论文的其余部分,将这种方法称为 Leaf Similarity ,其计算公式如下:
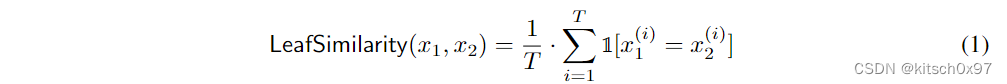
4.2 EMBERSim 元数据增强
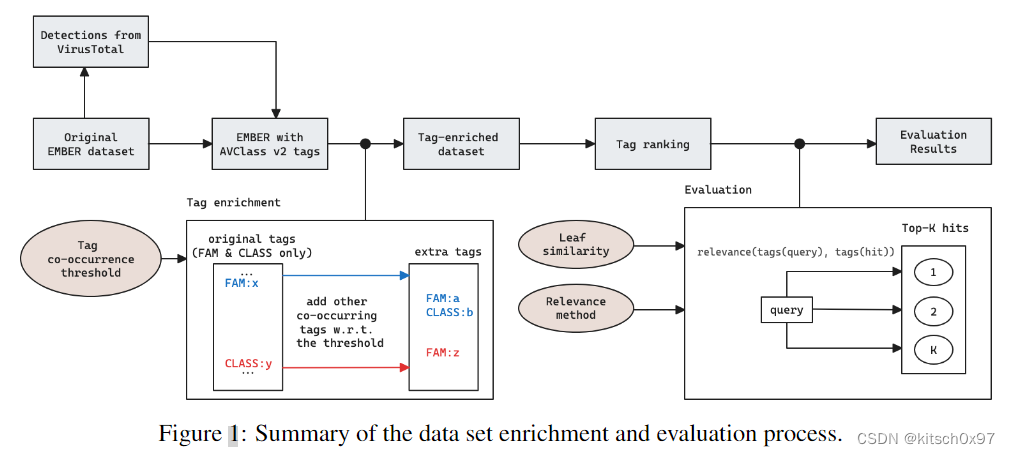
AVClass2 标签生成:论文使用原始 EMBER 数据集中样本的 SHA256 来查询 VirusTotal 并从 VT 上可用的 AV 供应商获取检测结果。然后,论文对收集的 VirusTotal 数据运行 AVClass。论文的主要目标是从供应商那里获得标准化的检测名称。其次,我们获得生成的标签的排名,并将它们分类为恶意软件类别(CLASS)、家族(FAM)或行为(BEH)。
基于 co-occurrence 的标签丰富:AVClass 的输出包括,文件的 SHA256、供应商的检测数量或没有检测到的 NULL 值,最后是逗号分隔的标签列表(即标签类型: FILE、BEH、FAM、CLASS、UNK)。

除了单独的结果之外,AVClass 还可以构建一个标签 co-occurence 矩阵,其中包含样本中一起出现的所有标签对以及共现统计数据。 考虑标签对 (a, b),AVClass 提供以下信息:标签 a 出现的总数、标签 b 出现的总数、常见共现总数、相对于标签 a 的常见共现 ,以及与标签 b 相关的常见共现。 给定样本的标签频率信息仅由其出现的不同样本总数决定,无论有多少供应商生产该标签。 这种常见的共现频率可以被视为标签对相关性的代理,因此论文可以利用它来用经常一起出现的新标签来扩充现有的标签列表。 也就是说,如果一个样本原本只有一个标签x,但是给定共现矩阵,观察到标签对 (x, y) 频繁地一起出现,那么论文也会给样本添加标签 y。 这种标签丰富机制在网络安全相似性搜索的背景下特别重要,因为它允许查找可能共享多个特征(即二进制文件结构)的样本,尽管它们被标记在不同的(例如家族)名称下,其具体算法如下所示。

计算标签的排名:论文使用来自 AVClass 的丰富标签信息和共现分析来生成地面实况元数据,该元数据可用于评估基于 Leaf Prediction 的 BCS 方法。本小节的重点是用于生成上述地面实况元数据的标签排名方法。考虑到良性样本没有标签,论文采用了适用于 EMBER 数据集中所有恶意软件样本的标签排名程序。该过程利用了通过早期阶段进行的共现分析获得的补充标签。为了理解本小节的其余部分,我们应该回顾一下,在原始 AVClass 输出中,每个标签都附有 AVClass 排名分数。
给定一个样本及其 AVClass 标签列表,其中包含多个不同类型的标签(FAM、CLASS、BEH、FILE)及其相应的排名分数,以标签类型为条件,可以得出概率分布:

可以将此概率视为多个供应商之间的信心和协议的衡量标准。 此外,论文用 freq(x, y) 表示标签 x 和 y 的共同同现频率,其公式如下所示:

标签 x 相对于标签 y 出现的相对出现频率。 标签排名算法使用共现信息扩展了原始 AVClass 排名分数,其公式如下所示:

请注意,由于按频率进行缩放,该评分方案将原始标签的排名高于通过共现获得的标签,考虑到共现信息可能更加嘈杂,这可能是理想的。

5. 实验结果
为了方便起见,我们在具有 64CPU 和 256GB RAM 的架构上进行实验。 运行论文提出的方法的最低要求是能够将数据集和模型加载到内存中。 具体来说,对于 EMBER 数据集和经过训练的 XGBoost 模型,内存消耗约为 27 GB RAM。 因此,具有 32 GB RAM 的机器应该足以复制本文中的结果。
在本工作的背景下,实验首先意味着确定真实的恶意软件标签。 其次,论文对 XGBoost 支持的二进制恶意软件分类器进行微调,直到其达到令人满意的性能,即我们在 EMBER 的测试分割上获得了 0.9966 的 ROC AUC 分数。 一批 EMBER 数据。 论文在微调过程产生了以下一组超参数:max_depth = 17,eta = 0.15,n_estimators = 2048,colsample_bytree = 1。最后,也是实验的一部分,论文利用叶子预测来计算 EMBER 中样本之间的相似度。
实验后,论文执行两种不同类型的评估,利用 EMBER 中的恶意/良性标签以及通过 AVClass 计算的标签信息来评估相似性搜索的质量。 值得一提的是,论文的评估在类似现实世界的环境中采用了反事实分析场景:论文使用包含超时样本的测试集,测试数据是在 2018-11 至 2018-12 之间收集的,而索引数据库仅包括 2018 年 10 月之前的样本。 作者认为,这种情况反映了威胁形势不断变化的性质,就像网络安全领域的情况一样。
5.1 基于恶意/良性标签的 Top-K 选择和评估
对于测试分割中的每个查询样本,论文从整个数据集中选择前 K 个最相似的样本。 鉴于 XGBoost 分类器在训练期间没有看到测试样本,因此查询过程不应附加任何偏差。 论文的第一个评估场景基于对查询及其最相似样本共享的标签(恶意/良性)进行计数。 下表显示了考虑前 K 个命中的此类评估的结果,其中 K 在 [1, 10, 50, 100] 中。 平均值列表示与针相同类别的平均命中数(例如,为了获得最佳性能,平均值应接近 K,标准差应接近 0)。 我们在下表中报告了 ssdeep 结果。在这种情况下,论文放宽了评估条件,如果查询的标签与结果的标签匹配并且样本具有非零 ssdeep 相似性,则考虑命中。 结果表明整体性能较差,恶意样本的得分略高,很可能是因为此类样本包含特定的字节模式。 相比之下,论文提出的方法对于恶意和良性查询都取得了更好的结果,表明叶相似性能够很好地找到相似的条目,并且随着我们减小 K 的值而变得更加精确。

5.2 K 值相关性的评估
探索的第二种评估风格需要以 FAM 标签排名的形式获取真实元数据。 随后,给定一个查询样本,论文检查其标签排名是否与前 K 个最相似的样本一致。
这里遵循的基本假设是应该为相似的样本保留元数据。 为了评估两个标签列表之间的相关性,论文使用下面列出的相似性函数:
- Exact Match:如果输入完全相同,则输出1,否则输出0。这是最严格的比较方法,作为该性能的下限。
- Jaccard index(IoU):忽略元素排序,仅关注输入中元素是否相同。
- Normalized edit similarity:基于字符串的 Damerau-Levenshtein 距离,实现排名中差异的惩罚。
评估过程称为相关性@K,工作原理如下:给定查询样本及其标签排名,以及前 K 个最相似的命中(每个都有自己的标签排名),我们使用上述函数来计算查询和每个命中之间的相关性。 这会为每个样本生成 K 个相关性分数。 然后,论文对子集中的所有 N 个查询样本重复此过程。 值得注意的是,如果样本缺少标签列表,论文认为它是良性的。 因此,如果查询和命中都缺少其标签列表,则相关性为 100%; 如果查询或命中存在标签列表,则相关性为 0%; 否则,论文应用上述相似函数。为了构建查询和知识库子集,论文考虑以下场景:
- 反事实分析(查询=测试,知识库=训练∪测试): 利用训练-测试时间分割(即时间戳(测试)>时间戳(训练)),我们可以模拟现实世界中类似生产的场景,其中我们使用看不见的但标记的数据(即测试集)来查询知识 根据。
- 无监督标记:给定未标记样本的集合,目标是识别知识库中的相似样本,以分配临时标签或标签。
通过下表不难发现,这两种场景在根据标签匹配查询和点击方面都提供了非常好的结果。 从相似性搜索的角度来看,这意味着在模拟生产环境的反事实分析场景中,论文的方法能够根据标签信息为给定的未见过的良性查询检索超过 95% 的良性相似样本,并为恶意样本检索超过 71% 的相关性。 给定的恶意查询分别即使有 100 次点击。 这也允许高置信度的无人监督标记,如底部表格所示。 作者确实注意到,考虑到这里的查询,生产场景预计将是这两个场景中最困难的。

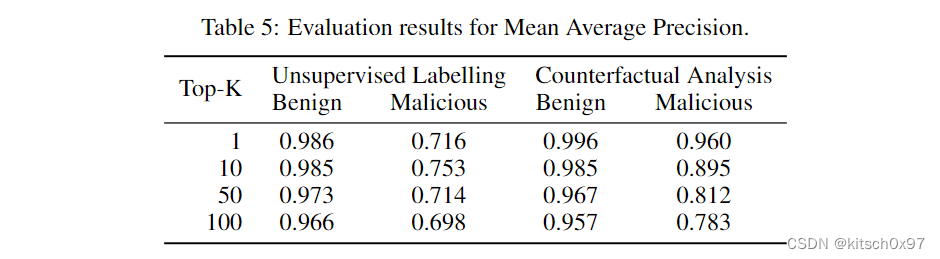
与训练 XGBoost 模型的样本相比,来自超时分布。 为了完整起见,下表显示了使用精确匹配来检查两个标签排名列表是否等效(因此相关)的平均精度 (mAP) 的评估结果。
6. 结论
假设和限制:评估方案需要满足两个基本假设。 首先,决定样本标签信息质量的三个因素:(1) VT 供应商检测的准确性,(2) AVClass 使用的标签标准化和排名算法,以及 (3) 标签的方式利用共现信息。 其次,论文认为样本缺少标签表明该样本是良性的。 尽管由于供应商之间的各种差异,VT 检测可能会产生噪音,但论文的策略旨在尽可能减轻这种影响。
潜在的负面社会影响和道德问题:论文通过额外的增强相似性的元数据来丰富数据集,其中包含已知的恶意软件样本,并且多年来已经使网络安全研究受益。 因此,网络安全供应商非常清楚并且有能力防御该数据集中包含的所有样本。
未来研究方向:论文确定了两种可以推动该领域未来研究的不同想法,同时使用论文当前的结果作为支持:模型可解释性和完善本工作中提出的基线。 对于后一种情况,我们认为使用多个基于树的模型进行比较研究是有价值的。
最后的评论:在目前的工作中,作者团队介绍了 EMBERSim,这是一个大规模数据集,它通过相似性衍生信息丰富了 EMBER,并可立即应用于两种不同粒度的样本标记。 作者团队是第一个研究成对相似性(在本文中也称为叶相似性)的适用性的人,无论是在二进制代码相似性的背景下,还是在一般网络安全中的适用性。 正如论文的评估所示,上述方法显示出有希望的结果。 这使论文能够为恶意软件分析师提供一组全面的标签,描述恶意和干净样本池中的样本,他们可以利用这些标签进行大规模相似性搜索。 作者希望这里提出的见解能够促进该领域的进一步研究,真正受益于更多结果——网络安全中基于机器学习的二进制代码相似性。















 2008
2008











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









